 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories
May 02, 2025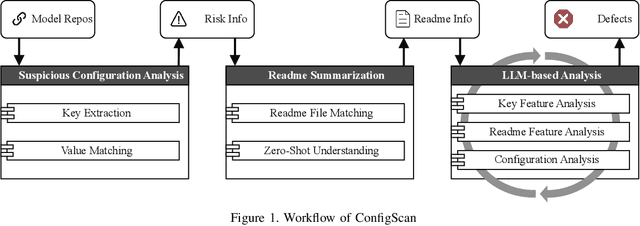

Recent advancements in large language models (LLMs) have spurred the development of diverse AI applications from code generation and video editing to text generation; however, AI supply chains such as Hugging Face, which host pretrained models and their associated configuration files contributed by the public, face significant security challenges; in particular, configuration files originally intended to set up models by specifying parameters and initial settings can be exploited to execute unauthorized code, yet research has largely overlooked their security compared to that of the models themselves; in this work, we present the first comprehensive study of malicious configurations on Hugging Face, identifying three attack scenarios (file, website, and repository operations) that expose inherent risks; to address these threats, we introduce CONFIGSCAN, an LLM-based tool that analyzes configuration files in the context of their associated runtime code and critical libraries, effectively detecting suspicious elements with low false positive rates and high accuracy; our extensive evaluation uncovers thousands of suspicious repositories and configuration files, underscoring the urgent need for enhanced security validation in AI model hosting platforms.
Indiana Jones: There Are Always Some Useful Ancient Relics
Jan 27, 2025



This paper introduces Indiana Jones, an innovative approach to jailbreaking Large Language Models (LLMs) by leveraging inter-model dialogues and keyword-driven prompts. Through orchestrating interactions among three specialised LLMs, the method achieves near-perfect success rates in bypassing content safeguards in both white-box and black-box LLMs. The research exposes systemic vulnerabilities within contemporary models, particularly their susceptibility to producing harmful or unethical outputs when guided by ostensibly innocuous prompts framed in historical or contextual contexts. Experimental evaluations highlight the efficacy and adaptability of Indiana Jones, demonstrating its superiority over existing jailbreak methods. These findings emphasise the urgent need for enhanced ethical safeguards and robust security measures in the development of LLMs. Moreover, this work provides a critical foundation for future studies aimed at fortifying LLMs against adversarial exploitation while preserving their utility and flexibility.
Image-Based Geolocation Using Large Vision-Language Models
Aug 18, 2024Geolocation is now a vital aspect of modern life, offering numerous benefits but also presenting serious privacy concerns. The advent of large vision-language models (LVLMs) with advanced image-processing capabilities introduces new risks, as these models can inadvertently reveal sensitive geolocation information. This paper presents the first in-depth study analyzing the challenges posed by traditional deep learning and LVLM-based geolocation methods. Our findings reveal that LVLMs can accurately determine geolocations from images, even without explicit geographic training. To address these challenges, we introduce \tool{}, an innovative framework that significantly enhances image-based geolocation accuracy. \tool{} employs a systematic chain-of-thought (CoT) approach, mimicking human geoguessing strategies by carefully analyzing visual and contextual cues such as vehicle types, architectural styles, natural landscapes, and cultural elements. Extensive testing on a dataset of 50,000 ground-truth data points shows that \tool{} outperforms both traditional models and human benchmarks in accuracy. It achieves an impressive average score of 4550.5 in the GeoGuessr game, with an 85.37\% win rate, and delivers highly precise geolocation predictions, with the closest distances as accurate as 0.3 km. Furthermore, our study highlights issues related to dataset integrity, leading to the creation of a more robust dataset and a refined framework that leverages LVLMs' cognitive capabilities to improve geolocation precision. These findings underscore \tool{}'s superior ability to interpret complex visual data, the urgent need to address emerging security vulnerabilities posed by LVLMs, and the importance of responsible AI development to ensure user privacy protection.