 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeCo: Enhancing LLM-Empowered Multi-Robot Collaboration via Similar Task Memoization
Jan 28, 2026Multi-robot systems have been widely deployed in real-world applications, providing significant improvements in efficiency and reductions in labor costs. However, most existing multi-robot collaboration methods rely on extensive task-specific training, which limits their adaptability to new or diverse scenarios. Recent research leverages the language understanding and reasoning capabilities of large language models (LLMs) to enable more flexible collaboration without specialized training. Yet, current LLM-empowered approaches remain inefficient: when confronted with identical or similar tasks, they must replan from scratch because they omit task-level similarities. To address this limitation, we propose MeCo, a similarity-aware multi-robot collaboration framework that applies the principle of ``cache and reuse'' (a.k.a., memoization) to reduce redundant computation. Unlike simple task repetition, identifying and reusing solutions for similar but not identical tasks is far more challenging, particularly in multi-robot settings. To this end, MeCo introduces a new similarity testing method that retrieves previously solved tasks with high relevance, enabling effective plan reuse without re-invoking LLMs. Furthermore, we present MeCoBench, the first benchmark designed to evaluate performance on similar-task collaboration scenarios. Experimental results show that MeCo substantially reduces planning costs and improves success rates compared with state-of-the-art approaches.
RaftFed: A Lightweight Federated Learning Framework for Vehicular Crowd Intelligence
Oct 11, 2023Vehicular crowd intelligence (VCI) is an emerging research field. Facilitated by state-of-the-art vehicular ad-hoc networks and artificial intelligence, various VCI applications come to place, e.g., collaborative sensing, positioning, and mapping. The collaborative property of VCI applications generally requires data to be shared among participants, thus forming network-wide intelligence. How to fulfill this process without compromising data privacy remains a challenging issue. Although federated learning (FL) is a promising tool to solve the problem, adapting conventional FL frameworks to VCI is nontrivial. First, the centralized model aggregation is unreliable in VCI because of the existence of stragglers with unfavorable channel conditions. Second, existing FL schemes are vulnerable to Non-IID data, which is intensified by the data heterogeneity in VCI. This paper proposes a novel federated learning framework called RaftFed to facilitate privacy-preserving VCI. The experimental results show that RaftFed performs better than baselines regarding communication overhead, model accuracy, and model convergence.
Beyond the Model: Data Pre-processing Attack to Deep Learning Models in Android Apps
May 11, 2023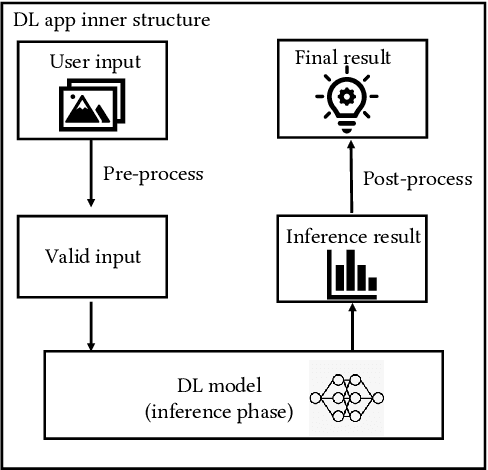
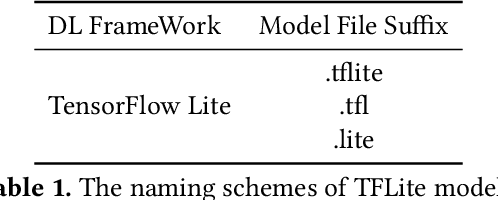
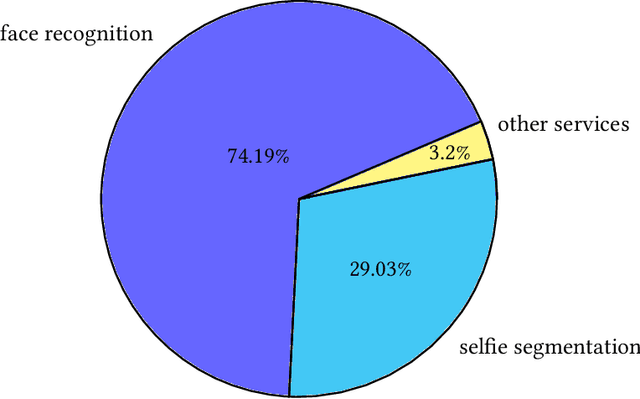

The increasing popularity of deep learning (DL) models and the advantages of computing, including low latency and bandwidth savings on smartphones, have led to the emergence of intelligent mobile applications, also known as DL apps, in recent years. However, this technological development has also given rise to several security concerns, including adversarial examples, model stealing, and data poisoning issues. Existing works on attacks and countermeasures for on-device DL models have primarily focused on the models themselves. However, scant attention has been paid to the impact of data processing disturbance on the model inference. This knowledge disparity highlights the need for additional research to fully comprehend and address security issues related to data processing for on-device models. In this paper, we introduce a data processing-based attacks against real-world DL apps. In particular, our attack could influence the performance and latency of the model without affecting the operation of a DL app. To demonstrate the effectiveness of our attack, we carry out an empirical study on 517 real-world DL apps collected from Google Play. Among 320 apps utilizing MLkit, we find that 81.56\% of them can be successfully attacked. The results emphasize the importance of DL app developers being aware of and taking actions to secure on-device models from the perspective of data processing.
Energy-Latency Attacks to On-Device Neural Networks via Sponge Poisoning
May 11, 2023In recent years, on-device deep learning has gained attention as a means of developing affordable deep learning applications for mobile devices. However, on-device models are constrained by limited energy and computation resources. In the mean time, a poisoning attack known as sponge poisoning has been developed.This attack involves feeding the model with poisoned examples to increase the energy consumption during inference. As previous work is focusing on server hardware accelerators, in this work, we extend the sponge poisoning attack to an on-device scenario to evaluate the vulnerability of mobile device processors. We present an on-device sponge poisoning attack pipeline to simulate the streaming and consistent inference scenario to bridge the knowledge gap in the on-device setting. Our exclusive experimental analysis with processors and on-device networks shows that sponge poisoning attacks can effectively pollute the modern processor with its built-in accelerator. We analyze the impact of different factors in the sponge poisoning algorithm and highlight the need for improved defense mechanisms to prevent such attacks on on-device deep learning applications.