 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebNavigator: Global Web Navigation via Interaction Graph Retrieval
Mar 20, 2026Despite significant advances in autonomous web navigation, current methods remain far from human-level performance in complex web environments. We argue that this limitation stems from Topological Blindness, where agents are forced to explore via trial-and-error without access to the global topological structure of the environment. To overcome this limitation, we introduce WebNavigator, which reframes web navigation from probabilistic exploration into deterministic retrieval and pathfinding. WebNavigator constructs Interaction Graphs via zero-token cost heuristic exploration offline and implements a Retrieve-Reason-Teleport workflow for global navigation online. WebNavigator achieves state-of-the-art performance on WebArena and OnlineMind2Web. On WebArena multi-site tasks, WebNavigator achieves a 72.9\% success rate, more than doubling the performance of enterprise-level agents. This work reveals that Topological Blindness, rather than model reasoning capabilities alone, is an underestimated bottleneck in autonomous web navigation.
Psychologically-Inspired, Unsupervised Inference of Perceptual Groups of GUI Widgets from GUI Images
Jun 15, 2022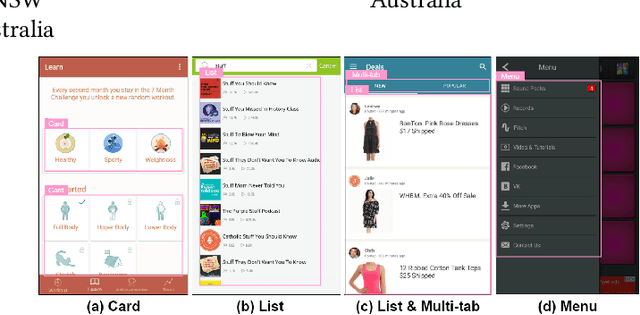
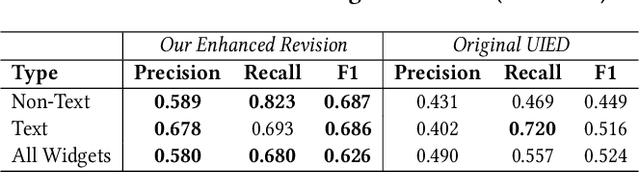
Graphical User Interface (GUI) is not merely a collection of individual and unrelated widgets, but rather partitions discrete widgets into groups by various visual cues, thus forming higher-order perceptual units such as tab, menu, card or list. The ability to automatically segment a GUI into perceptual groups of widgets constitutes a fundamental component of visual intelligence to automate GUI design, implementation and automation tasks. Although humans can partition a GUI into meaningful perceptual groups of widgets in a highly reliable way, perceptual grouping is still an open challenge for computational approaches. Existing methods rely on ad-hoc heuristics or supervised machine learning that is dependent on specific GUI implementations and runtime information. Research in psychology and biological vision has formulated a set of principles (i.e., Gestalt theory of perception) that describe how humans group elements in visual scenes based on visual cues like connectivity, similarity, proximity and continuity. These principles are domain-independent and have been widely adopted by practitioners to structure content on GUIs to improve aesthetic pleasant and usability. Inspired by these principles, we present a novel unsupervised image-based method for inferring perceptual groups of GUI widgets. Our method requires only GUI pixel images, is independent of GUI implementation, and does not require any training data. The evaluation on a dataset of 1,091 GUIs collected from 772 mobile apps and 20 UI design mockups shows that our method significantly outperforms the state-of-the-art ad-hoc heuristics-based baseline. Our perceptual grouping method creates the opportunities for improving UI-related software engineering tasks.
Object Detection for Graphical User Interface: Old Fashioned or Deep Learning or a Combination?
Sep 07, 2020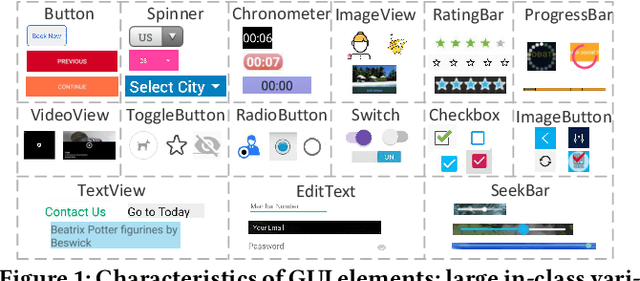

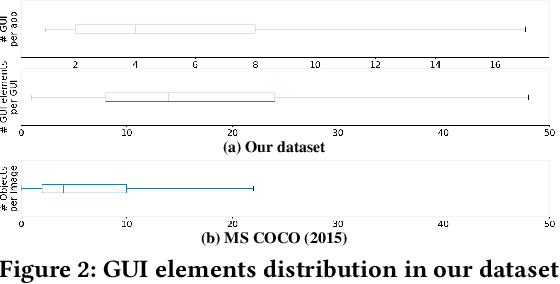
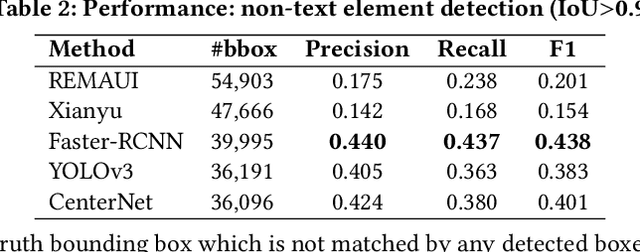
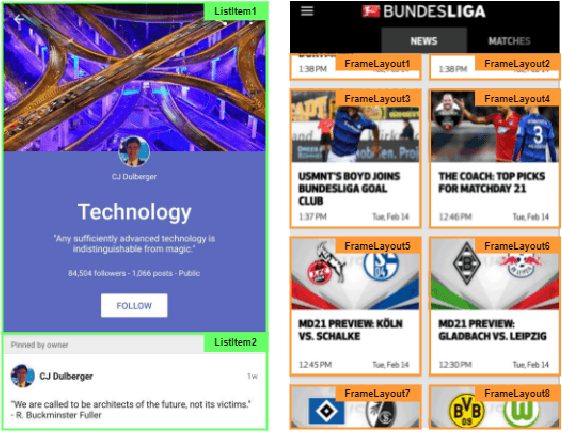
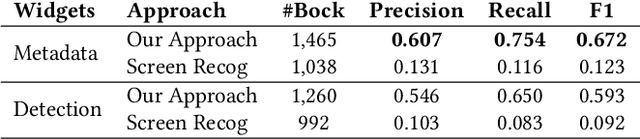
Detecting Graphical User Interface (GUI) elements in GUI images is a domain-specific object detection task. It supports many software engineering tasks, such as GUI animation and testing, GUI search and code generation. Existing studies for GUI element detection directly borrow the mature methods from computer vision (CV) domain, including old fashioned ones that rely on traditional image processing features (e.g., canny edge, contours), and deep learning models that learn to detect from large-scale GUI data. Unfortunately, these CV methods are not originally designed with the awareness of the unique characteristics of GUIs and GUI elements and the high localization accuracy of the GUI element detection task. We conduct the first large-scale empirical study of seven representative GUI element detection methods on over 50k GUI images to understand the capabilities, limitations and effective designs of these methods. This study not only sheds the light on the technical challenges to be addressed but also informs the design of new GUI element detection methods. We accordingly design a new GUI-specific old-fashioned method for non-text GUI element detection which adopts a novel top-down coarse-to-fine strategy, and incorporate it with the mature deep learning model for GUI text detection.Our evaluation on 25,000 GUI images shows that our method significantly advances the start-of-the-art performance in GUI element detection.