 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAL-KG: Schema-Free Incremental Knowledge Graph Construction via Dynamic Schema Induction and Evolution-Intent Assessment
Mar 20, 2026Knowledge Graphs (KGs) are foundational to applications such as search, question answering, and recommendation. Conventional knowledge graph construction methods are predominantly static, rely ing on a single-step construction from a fixed corpus with a prede f ined schema. However, such methods are suboptimal for real-world sce narios where data arrives dynamically, as incorporating new informa tion requires complete and computationally expensive graph reconstruc tions. Furthermore, predefined schemas hinder the flexibility of knowl edge graph construction. To address these limitations, we introduce DIAL KG, a closed-loop framework for incremental KG construction orches trated by a Meta-Knowledge Base (MKB). The framework oper ates in a three-stage cycle: (i) Dual-Track Extraction, which ensures knowledge completeness by defaulting to triple generation and switching to event extraction for complex knowledge; (ii) Governance Adjudica tion, which ensures the fidelity and currency of extracted facts to prevent hallucinations and knowledge staleness; and (iii) Schema Evolution, in which new schemas are induced from validated knowledge to guide subsequent construction cycles, and knowledge from the current round is incrementally applied to the existing KG. Extensive experiments demon strate that our framework achieves state-of-the-art (SOTA) performance in the quality of both the constructed graph and the induced schemas.
Rethink Efficiency Side of Neural Combinatorial Solver: An Offline and Self-Play Paradigm
Feb 24, 2026We propose ECO, a versatile learning paradigm that enables efficient offline self-play for Neural Combinatorial Optimization (NCO). ECO addresses key limitations in the field through: 1) Paradigm Shift: Moving beyond inefficient online paradigms, we introduce a two-phase offline paradigm consisting of supervised warm-up and iterative Direct Preference Optimization (DPO); 2) Architecture Shift: We deliberately design a Mamba-based architecture to further enhance the efficiency in the offline paradigm; and 3) Progressive Bootstrapping: To stabilize training, we employ a heuristic-based bootstrapping mechanism that ensures continuous policy improvement during training. Comparison results on TSP and CVRP highlight that ECO performs competitively with up-to-date baselines, with significant advantage on the efficiency side in terms of memory utilization and training throughput. We provide further in-depth analysis on the efficiency, throughput and memory usage of ECO. Ablation studies show rationale behind our designs.
CIRAG: Construction-Integration Retrieval and Adaptive Generation for Multi-hop Question Answering
Jan 11, 2026Triple-based Iterative Retrieval-Augmented Generation (iRAG) mitigates document-level noise for multi-hop question answering. However, existing methods still face limitations: (i) greedy single-path expansion, which propagates early errors and fails to capture parallel evidence from different reasoning branches, and (ii) granularity-demand mismatch, where a single evidence representation struggles to balance noise control with contextual sufficiency. In this paper, we propose the Construction-Integration Retrieval and Adaptive Generation model, CIRAG. It introduces an Iterative Construction-Integration module that constructs candidate triples and history-conditionally integrates them to distill core triples and generate the next-hop query. This module mitigates the greedy trap by preserving multiple plausible evidence chains. Besides, we propose an Adaptive Cascaded Multi-Granularity Generation module that progressively expands contextual evidence based on the problem requirements, from triples to supporting sentences and full passages. Moreover, we introduce Trajectory Distillation, which distills the teacher model's integration policy into a lightweight student, enabling efficient and reliable long-horizon reasoning. Extensive experiments demonstrate that CIRAG achieves superior performance compared to existing iRAG methods.
SacFL: Self-Adaptive Federated Continual Learning for Resource-Constrained End Devices
May 01, 2025



The proliferation of end devices has led to a distributed computing paradigm, wherein on-device machine learning models continuously process diverse data generated by these devices. The dynamic nature of this data, characterized by continuous changes or data drift, poses significant challenges for on-device models. To address this issue, continual learning (CL) is proposed, enabling machine learning models to incrementally update their knowledge and mitigate catastrophic forgetting. However, the traditional centralized approach to CL is unsuitable for end devices due to privacy and data volume concerns. In this context, federated continual learning (FCL) emerges as a promising solution, preserving user data locally while enhancing models through collaborative updates. Aiming at the challenges of limited storage resources for CL, poor autonomy in task shift detection, and difficulty in coping with new adversarial tasks in FCL scenario, we propose a novel FCL framework named SacFL. SacFL employs an Encoder-Decoder architecture to separate task-robust and task-sensitive components, significantly reducing storage demands by retaining lightweight task-sensitive components for resource-constrained end devices. Moreover, $\rm{SacFL}$ leverages contrastive learning to introduce an autonomous data shift detection mechanism, enabling it to discern whether a new task has emerged and whether it is a benign task. This capability ultimately allows the device to autonomously trigger CL or attack defense strategy without additional information, which is more practical for end devices. Comprehensive experiments conducted on multiple text and image datasets, such as Cifar100 and THUCNews, have validated the effectiveness of $\rm{SacFL}$ in both class-incremental and domain-incremental scenarios. Furthermore, a demo system has been developed to verify its practicality.
Efficient Multi-Task Modeling through Automated Fusion of Trained Models
Apr 14, 2025


Although multi-task learning is widely applied in intelligent services, traditional multi-task modeling methods often require customized designs based on specific task combinations, resulting in a cumbersome modeling process. Inspired by the rapid development and excellent performance of single-task models, this paper proposes an efficient multi-task modeling method that can automatically fuse trained single-task models with different structures and tasks to form a multi-task model. As a general framework, this method allows modelers to simply prepare trained models for the required tasks, simplifying the modeling process while fully utilizing the knowledge contained in the trained models. This eliminates the need for excessive focus on task relationships and model structure design. To achieve this goal, we consider the structural differences among various trained models and employ model decomposition techniques to hierarchically decompose them into multiple operable model components. Furthermore, we have designed an Adaptive Knowledge Fusion (AKF) module based on Transformer, which adaptively integrates intra-task and inter-task knowledge based on model components. Through the proposed method, we achieve efficient and automated construction of multi-task models, and its effectiveness is verified through extensive experiments on three datasets.
CUT: Pruning Pre-Trained Multi-Task Models into Compact Models for Edge Devices
Apr 14, 2025Multi-task learning has garnered widespread attention in the industry due to its efficient data utilization and strong generalization capabilities, making it particularly suitable for providing high-quality intelligent services to users. Edge devices, as the primary platforms directly serving users, play a crucial role in delivering multi-task services. However, current multi-task models are often large, and user task demands are increasingly diverse. Deploying such models directly on edge devices not only increases the burden on these devices but also leads to task redundancy. To address this issue, this paper innovatively proposes a pre-trained multi-task model pruning method specifically designed for edge computing. The goal is to utilize existing pre-trained multi-task models to construct a compact multi-task model that meets the needs of edge devices. The specific implementation steps are as follows: First, decompose the tasks within the pre-trained multi-task model and select tasks based on actual user needs. Next, while retaining the knowledge of the original pre-trained model, evaluate parameter importance and use a parameter fusion method to effectively integrate shared parameters among tasks. Finally, obtain a compact multi-task model suitable for edge devices. To validate the effectiveness of the proposed method, we conducted experiments on three public image datasets. The experimental results fully demonstrate the superiority and efficiency of this method, providing a new solution for multi-task learning on edge devices.
Multi-task Federated Learning with Encoder-Decoder Structure: Enabling Collaborative Learning Across Different Tasks
Apr 14, 2025



Federated learning has been extensively studied and applied due to its ability to ensure data security in distributed environments while building better models. However, clients participating in federated learning still face limitations, as clients with different structures or tasks cannot participate in learning together. In view of this, constructing a federated learning framework that allows collaboration between clients with different model structures and performing different tasks, enabling them to share valuable knowledge to enhance model efficiency, holds significant practical implications for the widespread application of federated learning. To achieve this goal, we propose a multi-task federated learning with encoder-decoder structure (M-Fed). Specifically, given the widespread adoption of the encoder-decoder architecture in current models, we leverage this structure to share intra-task knowledge through traditional federated learning methods and extract general knowledge from the encoder to achieve cross-task knowledge sharing. The training process is similar to traditional federated learning, and we incorporate local decoder and global decoder information into the loss function. The local decoder iteratively updates and gradually approaches the global decoder until sufficient cross-task knowledge sharing is achieved. Our method is lightweight and modular, demonstrating innovation compared to previous research. It enables clients performing different tasks to share general knowledge while maintaining the efficiency of traditional federated learning systems. We conducted experiments on two widely used benchmark datasets to verify the feasibility of M-Fed and compared it with traditional methods. The experimental results demonstrate the effectiveness of M-Fed in multi-task federated learning.
Unlearning through Knowledge Overwriting: Reversible Federated Unlearning via Selective Sparse Adapter
Feb 28, 2025



Federated Learning is a promising paradigm for privacy-preserving collaborative model training. In practice, it is essential not only to continuously train the model to acquire new knowledge but also to guarantee old knowledge the right to be forgotten (i.e., federated unlearning), especially for privacy-sensitive information or harmful knowledge. However, current federated unlearning methods face several challenges, including indiscriminate unlearning of cross-client knowledge, irreversibility of unlearning, and significant unlearning costs. To this end, we propose a method named FUSED, which first identifies critical layers by analyzing each layer's sensitivity to knowledge and constructs sparse unlearning adapters for sensitive ones. Then, the adapters are trained without altering the original parameters, overwriting the unlearning knowledge with the remaining knowledge. This knowledge overwriting process enables FUSED to mitigate the effects of indiscriminate unlearning. Moreover, the introduction of independent adapters makes unlearning reversible and significantly reduces the unlearning costs. Finally, extensive experiments on three datasets across various unlearning scenarios demonstrate that FUSED's effectiveness is comparable to Retraining, surpassing all other baselines while greatly reducing unlearning costs.
FedHPD: Heterogeneous Federated Reinforcement Learning via Policy Distillation
Feb 02, 2025



Federated Reinforcement Learning (FedRL) improves sample efficiency while preserving privacy; however, most existing studies assume homogeneous agents, limiting its applicability in real-world scenarios. This paper investigates FedRL in black-box settings with heterogeneous agents, where each agent employs distinct policy networks and training configurations without disclosing their internal details. Knowledge Distillation (KD) is a promising method for facilitating knowledge sharing among heterogeneous models, but it faces challenges related to the scarcity of public datasets and limitations in knowledge representation when applied to FedRL. To address these challenges, we propose Federated Heterogeneous Policy Distillation (FedHPD), which solves the problem of heterogeneous FedRL by utilizing action probability distributions as a medium for knowledge sharing. We provide a theoretical analysis of FedHPD's convergence under standard assumptions. Extensive experiments corroborate that FedHPD shows significant improvements across various reinforcement learning benchmark tasks, further validating our theoretical findings. Moreover, additional experiments demonstrate that FedHPD operates effectively without the need for an elaborate selection of public datasets.
G-flocking: Flocking Model Optimization based on Genetic Framework
Jul 27, 2019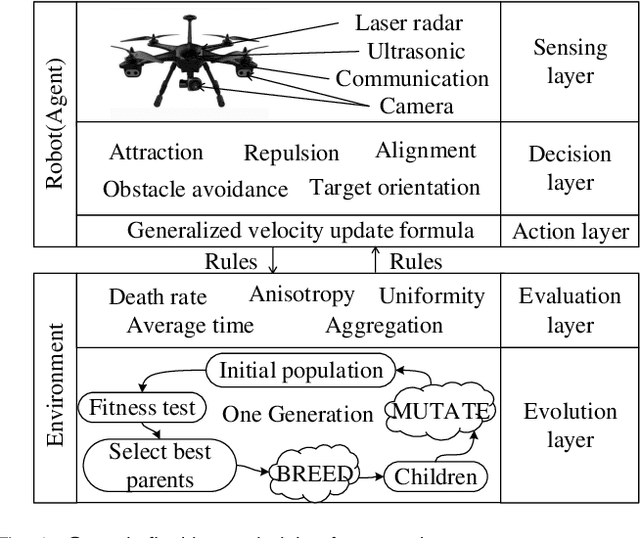
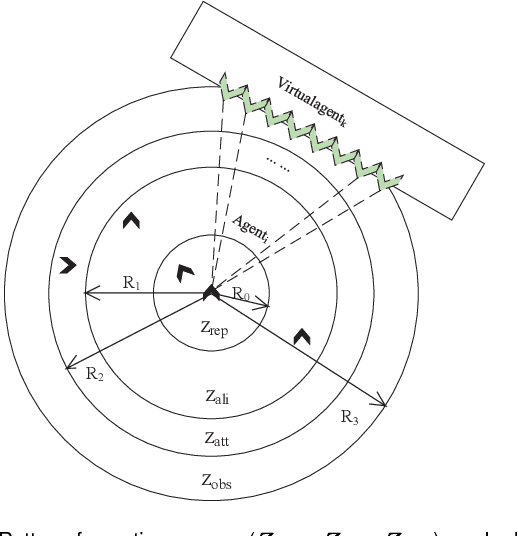
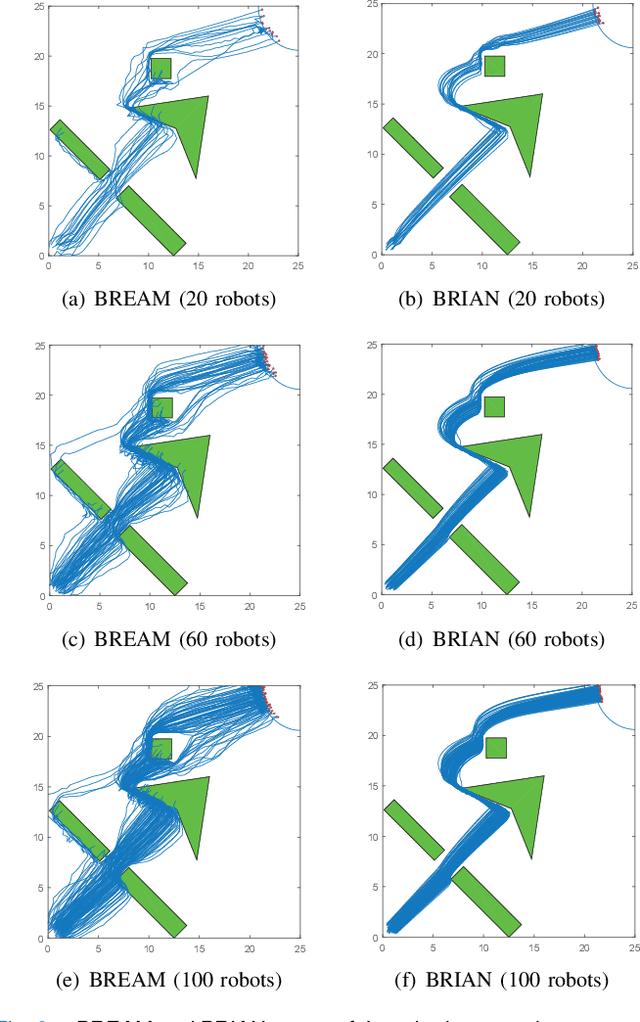
Flocking model has been widely used to control robotic swarm. However, with the increasing scalability, there exist complex conflicts for robotic swarm in autonomous navigation, brought by internal pattern maintenance, external environment changes, and target area orientation, which results in poor stability and adaptability. Hence, optimizing the flocking model for robotic swarm in autonomous navigation is an important and meaningful research domain.