 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Bayes' theorem with a neural network for gravitational-wave inference
Sep 23, 2019

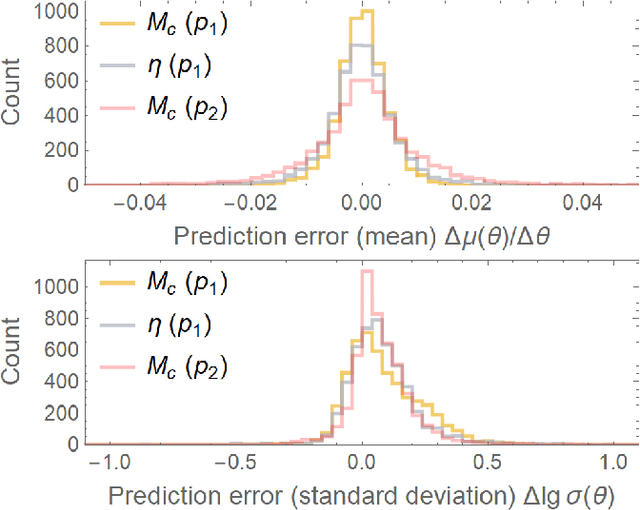

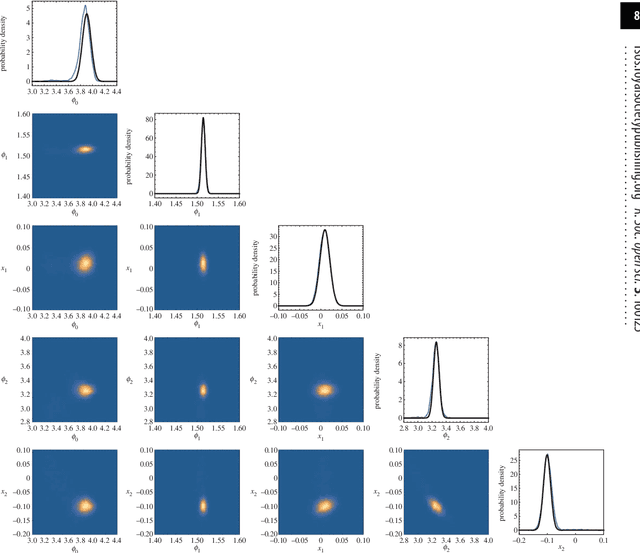
We seek to achieve the Holy Grail of Bayesian inference for gravitational-wave astronomy: using deep-learning techniques to instantly produce the posterior $p(\theta|D)$ for the source parameters $\theta$, given the detector data $D$. To do so, we train a deep neural network to take as input a signal + noise data set (drawn from the astrophysical source-parameter prior and the sampling distribution of detector noise), and to output a parametrized approximation of the corresponding posterior. We rely on a compact representation of the data based on reduced-order modeling, which we generate efficiently using a separate neural-network waveform interpolant [A. J. K. Chua, C. R. Galley & M. Vallisneri, Phys. Rev. Lett. 122, 211101 (2019)]. Our scheme has broad relevance to gravitational-wave applications such as low-latency parameter estimation and characterizing the science returns of future experiments. Source code and trained networks are available online at https://github.com/vallis/truebayes.
ROMAN: Reduced-Order Modeling with Artificial Neurons
Nov 13, 2018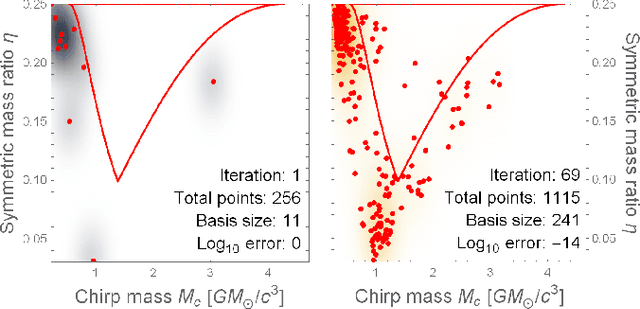
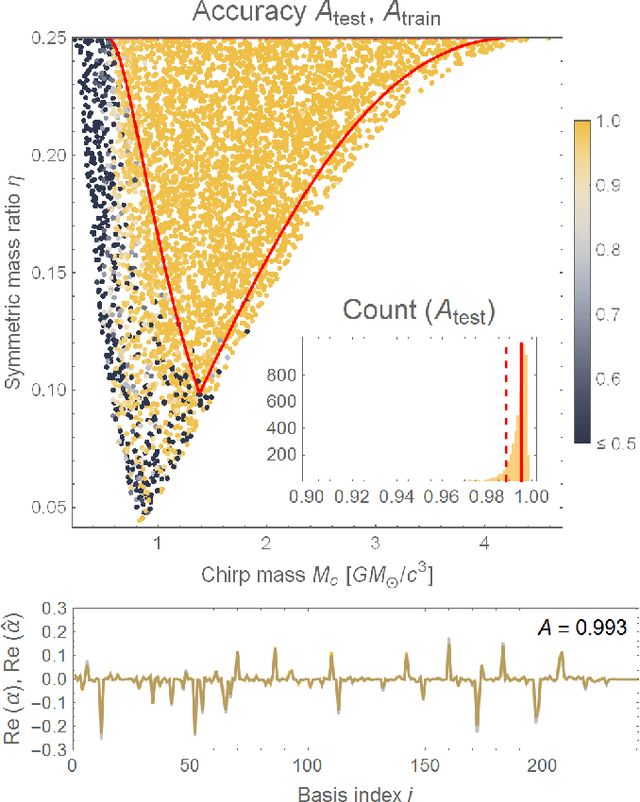

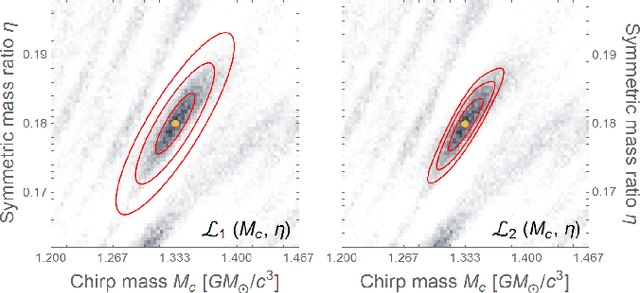
Gravitational-wave data analysis is rapidly absorbing techniques from deep learning, with a focus on convolutional networks and related methods that treat noisy time series as images. We pursue an alternative approach, in which waveforms are first represented as weighted sums over reduced bases (reduced-order modeling); we then train artificial neural networks to map gravitational-wave source parameters into basis coefficients. Statistical inference proceeds directly in coefficient space, where it is theoretically straightforward and computationally efficient. The neural networks also provide analytic waveform derivatives, which are useful for gradient-based sampling schemes. We demonstrate fast and accurate coefficient interpolation for the case of a four-dimensional binary-inspiral waveform family, and discuss promising applications of our framework in parameter estimation.
Fast methods for training Gaussian processes on large data sets
May 13, 2016

Gaussian process regression (GPR) is a non-parametric Bayesian technique for interpolating or fitting data. The main barrier to further uptake of this powerful tool rests in the computational costs associated with the matrices which arise when dealing with large data sets. Here, we derive some simple results which we have found useful for speeding up the learning stage in the GPR algorithm, and especially for performing Bayesian model comparison between different covariance functions. We apply our techniques to both synthetic and real data and quantify the speed-up relative to using nested sampling to numerically evaluate model evidences.
* Fixed missing references