 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE Drive A Framework for Evaluating Reason-Responsiveness of Vision Language Models in Automated Driving
Feb 17, 2026Foundation models, including vision language models, are increasingly used in automated driving to interpret scenes, recommend actions, and generate natural language explanations. However, existing evaluation methods primarily assess outcome based performance, such as safety and trajectory accuracy, without determining whether model decisions reflect human relevant considerations. As a result, it remains unclear whether explanations produced by such models correspond to genuine reason responsive decision making or merely post hoc rationalizations. This limitation is especially significant in safety critical domains because it can create false confidence. To address this gap, we propose CARE Drive, Context Aware Reasons Evaluation for Driving, a model agnostic framework for evaluating reason responsiveness in vision language models applied to automated driving. CARE Drive compares baseline and reason augmented model decisions under controlled contextual variation to assess whether human reasons causally influence decision behavior. The framework employs a two stage evaluation process. Prompt calibration ensures stable outputs. Systematic contextual perturbation then measures decision sensitivity to human reasons such as safety margins, social pressure, and efficiency constraints. We demonstrate CARE Drive in a cyclist overtaking scenario involving competing normative considerations. Results show that explicit human reasons significantly influence model decisions, improving alignment with expert recommended behavior. However, responsiveness varies across contextual factors, indicating uneven sensitivity to different types of reasons. These findings provide empirical evidence that reason responsiveness in foundation models can be systematically evaluated without modifying model parameters.
Towards Developing Socially Compliant Automated Vehicles: State of the Art, Experts Expectations, and A Conceptual Framework
Jan 10, 2025Automated Vehicles (AVs) hold promise for revolutionizing transportation by improving road safety, traffic efficiency, and overall mobility. Despite the steady advancement in high-level AVs in recent years, the transition to full automation entails a period of mixed traffic, where AVs of varying automation levels coexist with human-driven vehicles (HDVs). Making AVs socially compliant and understood by human drivers is expected to improve the safety and efficiency of mixed traffic. Thus, ensuring AVs compatibility with HDVs and social acceptance is crucial for their successful and seamless integration into mixed traffic. However, research in this critical area of developing Socially Compliant AVs (SCAVs) remains sparse. This study carries out the first comprehensive scoping review to assess the current state of the art in developing SCAVs, identifying key concepts, methodological approaches, and research gaps. An expert interview was also conducted to identify critical research gaps and expectations towards SCAVs. Based on the scoping review and expert interview input, a conceptual framework is proposed for the development of SCAVs. The conceptual framework is evaluated using an online survey targeting researchers, technicians, policymakers, and other relevant professionals worldwide. The survey results provide valuable validation and insights, affirming the significance of the proposed conceptual framework in tackling the challenges of integrating AVs into mixed-traffic environments. Additionally, future research perspectives and suggestions are discussed, contributing to the research and development agenda of SCAVs.
Characterizing Behavioral Differences and Adaptations of Automated Vehicles and Human Drivers at Unsignalized Intersections: Insights from Waymo and Lyft Open Datasets
Oct 16, 2024The integration of autonomous vehicles (AVs) into transportation systems presents an unprecedented opportunity to enhance road safety and efficiency. However, understanding the interactions between AVs and human-driven vehicles (HVs) at intersections remains an open research question. This study aims to bridge this gap by examining behavioral differences and adaptations of AVs and HVs at unsignalized intersections by utilizing two comprehensive AV datasets from Waymo and Lyft. Using a systematic methodology, the research identifies and analyzes merging and crossing conflicts by calculating key safety and efficiency metrics, including time to collision (TTC), post-encroachment time (PET), maximum required deceleration (MRD), time advantage (TA), and speed and acceleration profiles. The findings reveal a paradox in mixed traffic flow: while AVs maintain larger safety margins, their conservative behavior can lead to unexpected situations for human drivers, potentially causing unsafe conditions. From a performance point of view, human drivers exhibit more consistent behavior when interacting with AVs versus other HVs, suggesting AVs may contribute to harmonizing traffic flow patterns. Moreover, notable differences were observed between Waymo and Lyft vehicles, which highlights the importance of considering manufacturer-specific AV behaviors in traffic modeling and management strategies for the safe integration of AVs. The processed dataset utilized in this study is openly published to foster the research on AV-HV interactions.
Data-driven Semi-supervised Machine Learning with Surrogate Safety Measures for Abnormal Driving Behavior Detection
Dec 07, 2023Detecting abnormal driving behavior is critical for road traffic safety and the evaluation of drivers' behavior. With the advancement of machine learning (ML) algorithms and the accumulation of naturalistic driving data, many ML models have been adopted for abnormal driving behavior detection. Most existing ML-based detectors rely on (fully) supervised ML methods, which require substantial labeled data. However, ground truth labels are not always available in the real world, and labeling large amounts of data is tedious. Thus, there is a need to explore unsupervised or semi-supervised methods to make the anomaly detection process more feasible and efficient. To fill this research gap, this study analyzes large-scale real-world data revealing several abnormal driving behaviors (e.g., sudden acceleration, rapid lane-changing) and develops a Hierarchical Extreme Learning Machines (HELM) based semi-supervised ML method using partly labeled data to accurately detect the identified abnormal driving behaviors. Moreover, previous ML-based approaches predominantly utilize basic vehicle motion features (such as velocity and acceleration) to label and detect abnormal driving behaviors, while this study seeks to introduce Surrogate Safety Measures (SSMs) as the input features for ML models to improve the detection performance. Results from extensive experiments demonstrate the effectiveness of the proposed semi-supervised ML model with the introduced SSMs serving as important features. The proposed semi-supervised ML method outperforms other baseline semi-supervised or unsupervised methods regarding various metrics, e.g., delivering the best accuracy at 99.58% and the best F-1 measure at 0.9913. The ablation study further highlights the significance of SSMs for advancing detection performance.
Intelligent Anomaly Detection for Lane Rendering Using Transformer with Self-Supervised Pre-Training and Customized Fine-Tuning
Dec 07, 2023The burgeoning navigation services using digital maps provide great convenience to drivers. Nevertheless, the presence of anomalies in lane rendering map images occasionally introduces potential hazards, as such anomalies can be misleading to human drivers and consequently contribute to unsafe driving conditions. In response to this concern and to accurately and effectively detect the anomalies, this paper transforms lane rendering image anomaly detection into a classification problem and proposes a four-phase pipeline consisting of data pre-processing, self-supervised pre-training with the masked image modeling (MiM) method, customized fine-tuning using cross-entropy based loss with label smoothing, and post-processing to tackle it leveraging state-of-the-art deep learning techniques, especially those involving Transformer models. Various experiments verify the effectiveness of the proposed pipeline. Results indicate that the proposed pipeline exhibits superior performance in lane rendering image anomaly detection, and notably, the self-supervised pre-training with MiM can greatly enhance the detection accuracy while significantly reducing the total training time. For instance, employing the Swin Transformer with Uniform Masking as self-supervised pretraining (Swin-Trans-UM) yielded a heightened accuracy at 94.77% and an improved Area Under The Curve (AUC) score of 0.9743 compared with the pure Swin Transformer without pre-training (Swin-Trans) with an accuracy of 94.01% and an AUC of 0.9498. The fine-tuning epochs were dramatically reduced to 41 from the original 280. In conclusion, the proposed pipeline, with its incorporation of self-supervised pre-training using MiM and other advanced deep learning techniques, emerges as a robust solution for enhancing the accuracy and efficiency of lane rendering image anomaly detection in digital navigation systems.
Safe, Efficient, Comfort, and Energy-saving Automated Driving through Roundabout Based on Deep Reinforcement Learning
Jun 20, 2023Traffic scenarios in roundabouts pose substantial complexity for automated driving. Manually mapping all possible scenarios into a state space is labor-intensive and challenging. Deep reinforcement learning (DRL) with its ability to learn from interacting with the environment emerges as a promising solution for training such automated driving models. This study explores, employs, and implements various DRL algorithms, namely Deep Deterministic Policy Gradient (DDPG), Proximal Policy Optimization (PPO), and Trust Region Policy Optimization (TRPO) to instruct automated vehicles' driving through roundabouts. The driving state space, action space, and reward function are designed. The reward function considers safety, efficiency, comfort, and energy consumption to align with real-world requirements. All three tested DRL algorithms succeed in enabling automated vehicles to drive through the roundabout. To holistically evaluate the performance of these algorithms, this study establishes an evaluation methodology considering multiple indicators such as safety, efficiency, and comfort level. A method employing the Analytic Hierarchy Process is also developed to weigh these evaluation indicators. Experimental results on various testing scenarios reveal that the TRPO algorithm outperforms DDPG and PPO in terms of safety and efficiency, and PPO performs best in terms of comfort level. Lastly, to verify the model's adaptability and robustness regarding other driving scenarios, this study also deploys the model trained by TRPO to a range of different testing scenarios, e.g., highway driving and merging. Experimental results demonstrate that the TRPO model trained on only roundabout driving scenarios exhibits a certain degree of proficiency in highway driving and merging scenarios. This study provides a foundation for the application of automated driving with DRL in real traffic environments.
Framework for Network-Constrained Target Tracking
Mar 02, 2022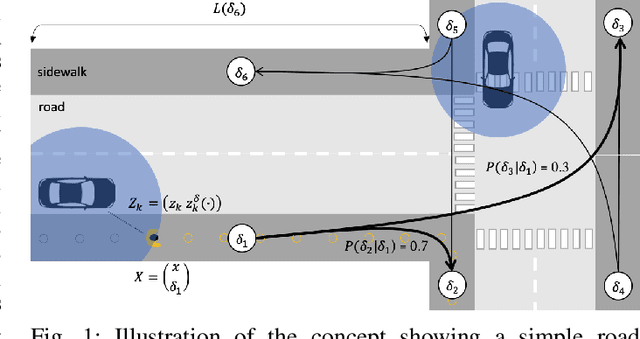
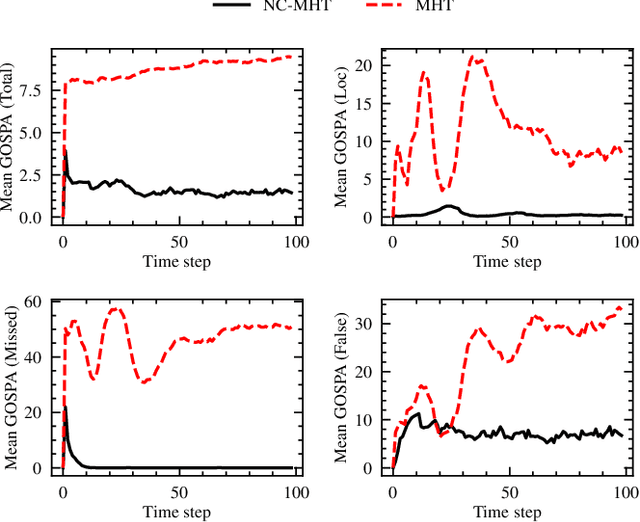
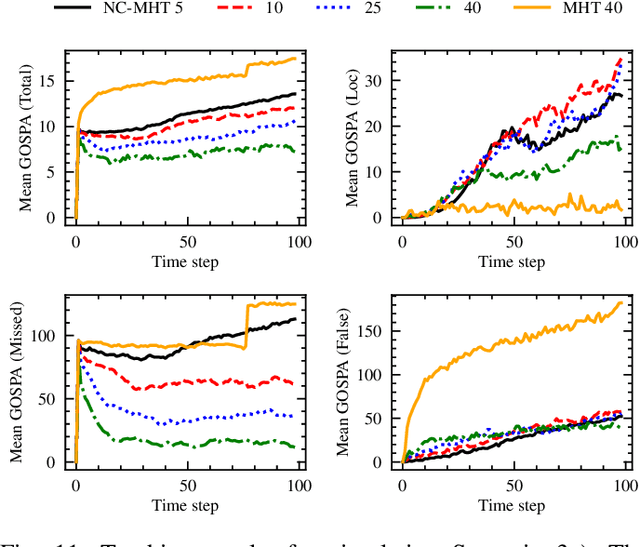
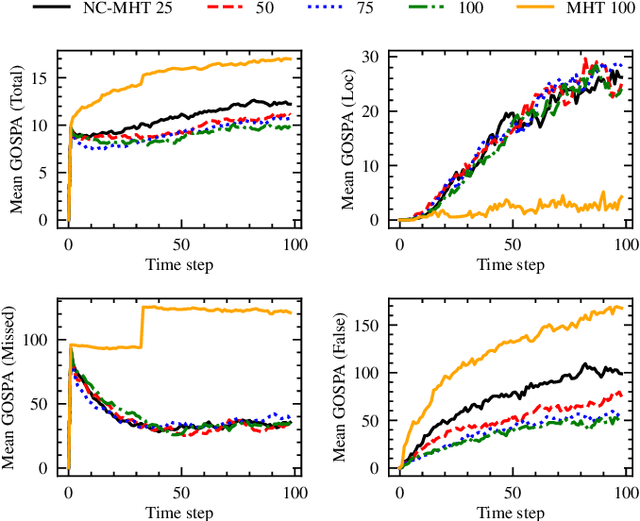
The increase in perception capabilities of connected mobile sensor platforms (e.g., self-driving vehicles, drones, and robots) leads to an extensive surge of sensed features at various temporal and spatial scales. Beyond their traditional use for safe operation, available observations could enable to see how and where people move on sidewalks and cycle paths, to eventually obtain a complete microscopic and macroscopic picture of the traffic flows in a larger area. This paper proposes a new method for advanced traffic applications, tracking an unknown and varying number of moving targets (e.g., pedestrians or cyclists) constrained by a road network, using mobile (e.g., vehicles) spatially distributed sensor platforms. The key contribution in this paper is to introduce the concept of network bound targets into the multi-target tracking problem, and hence to derive a network-constrained multi-hypotheses tracker (NC-MHT) to fully utilize the available road information. This is done by introducing a target representation, comprising a traditional target tracking representation and a discrete component placing the target on a given segment in the network. A simulation study shows that the method performs well in comparison to the standard MHT filter in free space. Results particularly highlight network-constraint effects for more efficient target predictions over extended periods of time, and in the simplification of the measurement association process, as compared to not utilizing a network structure. This theoretical work also directs attention to latent privacy concerns for potential applications.
A Hybrid Spatial-temporal Deep Learning Architecture for Lane Detection
Oct 14, 2021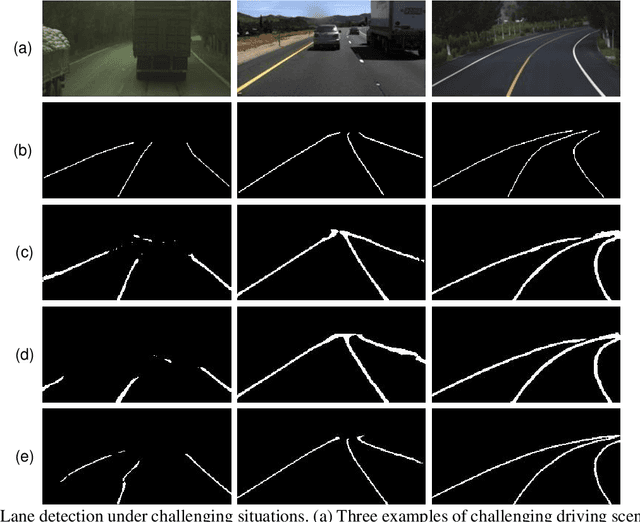
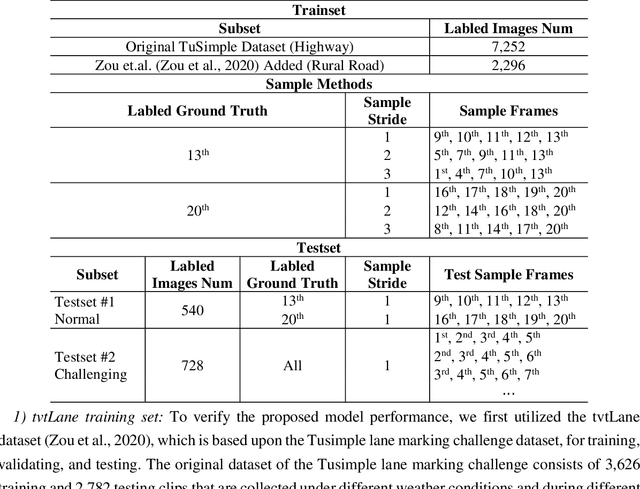
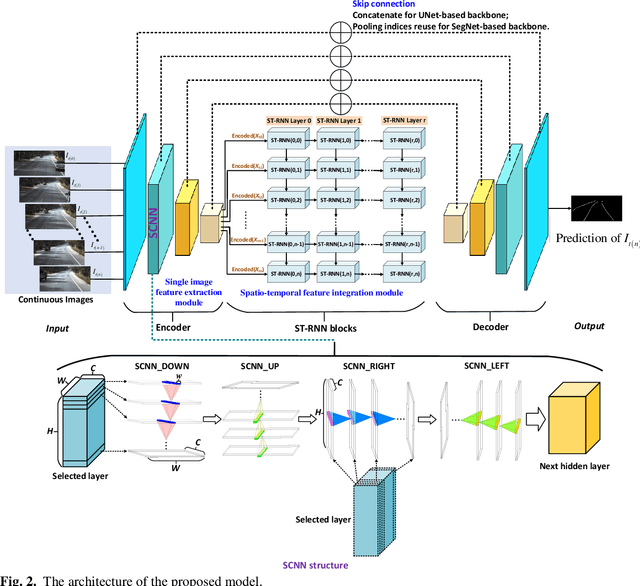
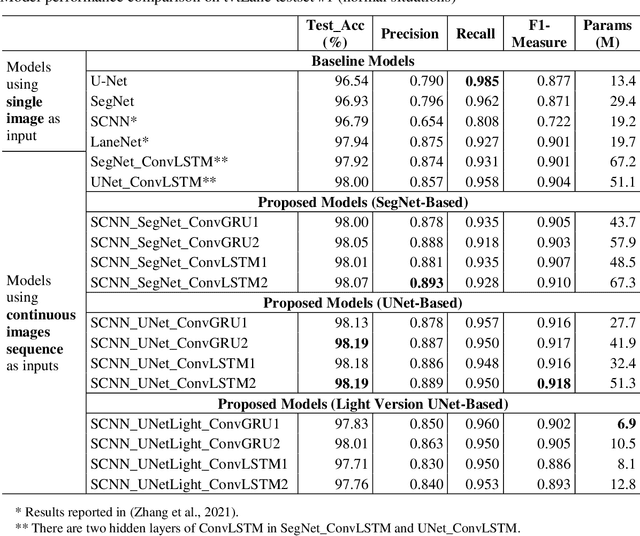
Reliable and accurate lane detection is of vital importance for the safe performance of Lane Keeping Assistance and Lane Departure Warning systems. However, under certain challenging peculiar circumstances, it is difficult to get satisfactory performance in accurately detecting the lanes from one single image which is often the case in current literature. Since lane markings are continuous lines, the lanes that are difficult to be accurately detected in the single current image can potentially be better deduced if information from previous frames is incorporated. This study proposes a novel hybrid spatial-temporal sequence-to-one deep learning architecture making full use of the spatial-temporal information in multiple continuous image frames to detect lane markings in the very last current frame. Specifically, the hybrid model integrates the single image feature extraction module with the spatial convolutional neural network (SCNN) embedded for excavating spatial features and relationships in one single image, the spatial-temporal feature integration module with spatial-temporal recurrent neural network (ST-RNN), which can capture the spatial-temporal correlations and time dependencies among image sequences, and the encoder-decoder structure, which makes this image segmentation problem work in an end-to-end supervised learning format. Extensive experiments reveal that the proposed model can effectively handle challenging driving scenes and outperforms available state-of-the-art methods with a large margin.