 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAG: Financial Long Document Classification via AMR-based GNN
Oct 02, 2024



The advent of large language models (LLMs) has initiated much research into their various financial applications. However, in applying LLMs on long documents, semantic relations are not explicitly incorporated, and a full or arbitrarily sparse attention operation is employed. In recent years, progress has been made in Abstract Meaning Representation (AMR), which is a graph-based representation of text to preserve its semantic relations. Since AMR can represent semantic relationships at a deeper level, it can be beneficially utilized by graph neural networks (GNNs) for constructing effective document-level graph representations built upon LLM embeddings to predict target metrics in the financial domain. We propose FLAG: Financial Long document classification via AMR-based GNN, an AMR graph based framework to generate document-level embeddings for long financial document classification. We construct document-level graphs from sentence-level AMR graphs, endow them with specialized LLM word embeddings in the financial domain, apply a deep learning mechanism that utilizes a GNN, and examine the efficacy of our AMR-based approach in predicting labeled target data from long financial documents. Extensive experiments are conducted on a dataset of quarterly earnings calls transcripts of companies in various sectors of the economy, as well as on a corpus of more recent earnings calls of companies in the S&P 1500 Composite Index. We find that our AMR-based approach outperforms fine-tuning LLMs directly on text in predicting stock price movement trends at different time horizons in both datasets. Our work also outperforms previous work utilizing document graphs and GNNs for text classification.
FETILDA: An Effective Framework For Fin-tuned Embeddings For Long Financial Text Documents
Jun 14, 2022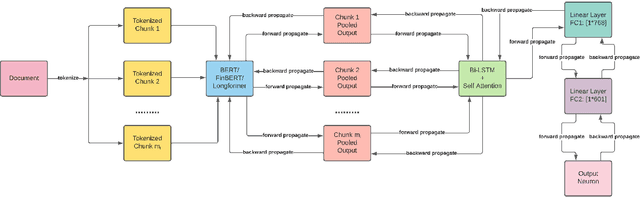
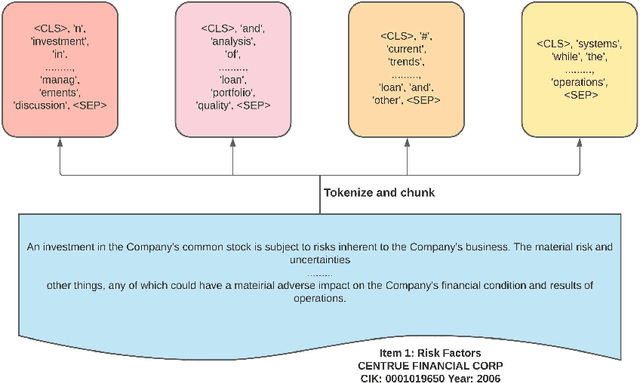

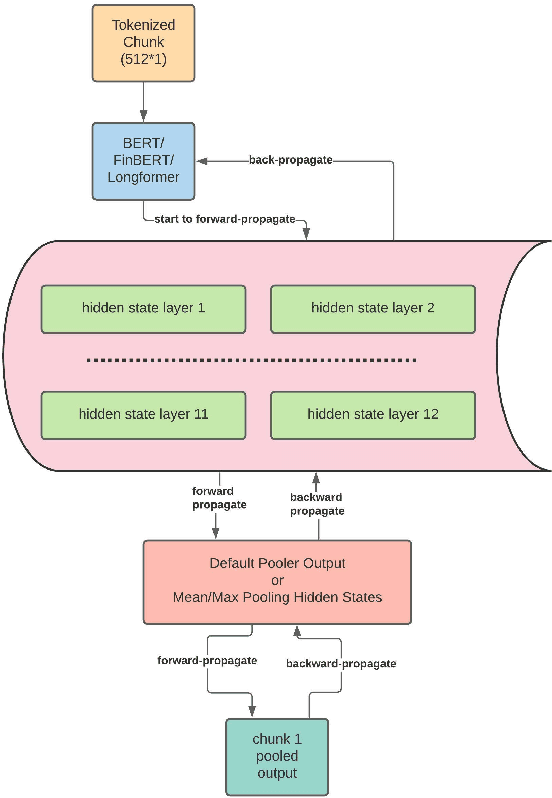
Unstructured data, especially text, continues to grow rapidly in various domains. In particular, in the financial sphere, there is a wealth of accumulated unstructured financial data, such as the textual disclosure documents that companies submit on a regular basis to regulatory agencies, such as the Securities and Exchange Commission (SEC). These documents are typically very long and tend to contain valuable soft information about a company's performance. It is therefore of great interest to learn predictive models from these long textual documents, especially for forecasting numerical key performance indicators (KPIs). Whereas there has been a great progress in pre-trained language models (LMs) that learn from tremendously large corpora of textual data, they still struggle in terms of effective representations for long documents. Our work fills this critical need, namely how to develop better models to extract useful information from long textual documents and learn effective features that can leverage the soft financial and risk information for text regression (prediction) tasks. In this paper, we propose and implement a deep learning framework that splits long documents into chunks and utilizes pre-trained LMs to process and aggregate the chunks into vector representations, followed by self-attention to extract valuable document-level features. We evaluate our model on a collection of 10-K public disclosure reports from US banks, and another dataset of reports submitted by US companies. Overall, our framework outperforms strong baseline methods for textual modeling as well as a baseline regression model using only numerical data. Our work provides better insights into how utilizing pre-trained domain-specific and fine-tuned long-input LMs in representing long documents can improve the quality of representation of textual data, and therefore, help in improving predictive analyses.
Efficient Algorithms for Generating Provably Near-Optimal Cluster Descriptors for Explainability
Feb 06, 2020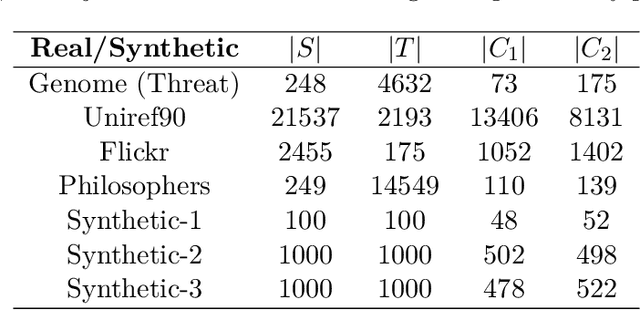

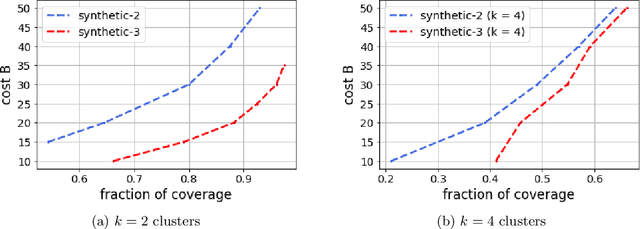
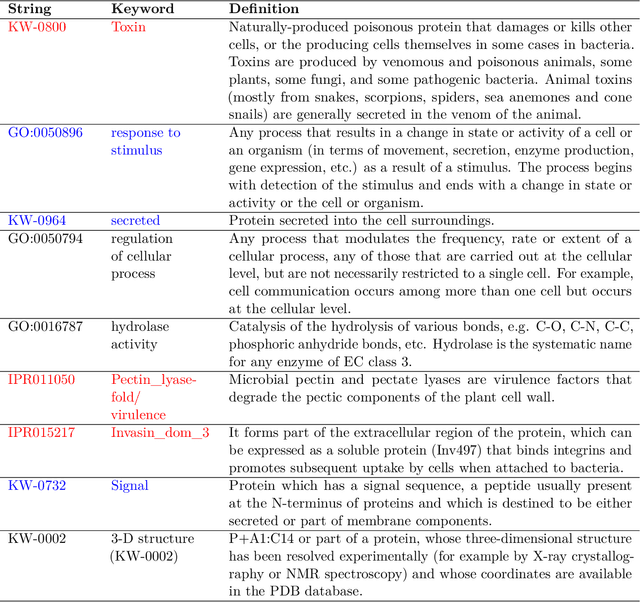
Improving the explainability of the results from machine learning methods has become an important research goal. Here, we study the problem of making clusters more interpretable by extending a recent approach of [Davidson et al., NeurIPS 2018] for constructing succinct representations for clusters. Given a set of objects $S$, a partition $\pi$ of $S$ (into clusters), and a universe $T$ of tags such that each element in $S$ is associated with a subset of tags, the goal is to find a representative set of tags for each cluster such that those sets are pairwise-disjoint and the total size of all the representatives is minimized. Since this problem is NP-hard in general, we develop approximation algorithms with provable performance guarantees for the problem. We also show applications to explain clusters from datasets, including clusters of genomic sequences that represent different threat levels.