 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE-PD: Explainable AI on Subjective and Clinical Objective Measurements of Parkinson's Disease for Precision Decision-Making
Jan 30, 2026Parkinson's disease (PD) is a chronic and complex neurodegenerative disorder influenced by genetic, clinical, and lifestyle factors. Predicting this disease early is challenging because it depends on traditional diagnostic methods that face issues of subjectivity, which commonly delay diagnosis. Several objective analyses are currently in practice to help overcome the challenges of subjectivity; however, a proper explanation of these analyses is still lacking. While machine learning (ML) has demonstrated potential in supporting PD diagnosis, existing approaches often rely on subjective reports only and lack interpretability for individualized risk estimation. This study proposes SCOPE-PD, an explainable AI-based prediction framework, by integrating subjective and objective assessments to provide personalized health decisions. Subjective and objective clinical assessment data are collected from the Parkinson's Progression Markers Initiative (PPMI) study to construct a multimodal prediction framework. Several ML techniques are applied to these data, and the best ML model is selected to interpret the results. Model interpretability is examined using SHAP-based analysis. The Random Forest algorithm achieves the highest accuracy of 98.66 percent using combined features from both subjective and objective test data. Tremor, bradykinesia, and facial expression are identified as the top three contributing features from the MDS-UPDRS test in the prediction of PD.
Improving Speech-based Emotion Recognition with Contextual Utterance Analysis and LLMs
Oct 27, 2024Speech Emotion Recognition (SER) focuses on identifying emotional states from spoken language. The 2024 IEEE SLT-GenSEC Challenge on Post Automatic Speech Recognition (ASR) Emotion Recognition tasks participants to explore the capabilities of large language models (LLMs) for emotion recognition using only text data. We propose a novel approach that first refines all available transcriptions to ensure data reliability. We then segment each complete conversation into smaller dialogues and use these dialogues as context to predict the emotion of the target utterance within the dialogue. Finally, we investigated different context lengths and prompting techniques to improve prediction accuracy. Our best submission exceeded the baseline by 20% in unweighted accuracy, achieving the best performance in the challenge. All our experiments' codes, prediction results, and log files are publicly available.
Medication Error Detection Using Contextual Language Models
Jan 09, 2022
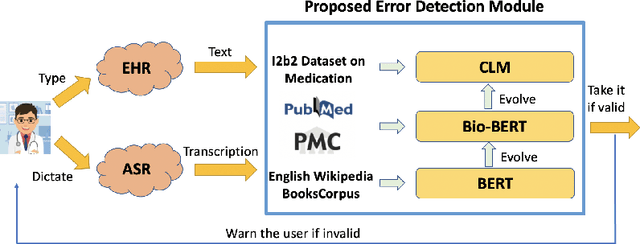
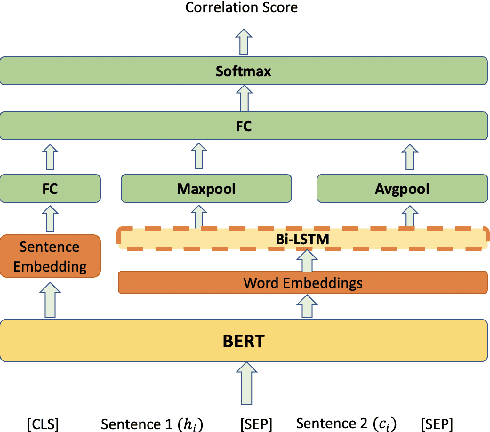
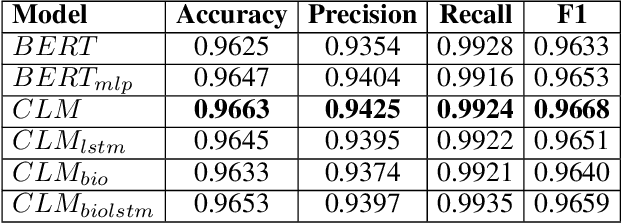
Medication errors most commonly occur at the ordering or prescribing stage, potentially leading to medical complications and poor health outcomes. While it is possible to catch these errors using different techniques; the focus of this work is on textual and contextual analysis of prescription information to detect and prevent potential medication errors. In this paper, we demonstrate how to use BERT-based contextual language models to detect anomalies in written or spoken text based on a data set extracted from real-world medical data of thousands of patient records. The proposed models are able to learn patterns of text dependency and predict erroneous output based on contextual information such as patient data. The experimental results yield accuracy up to 96.63% for text input and up to 79.55% for speech input, which is satisfactory for most real-world applications.
Detecting Replay Attacks Using Multi-Channel Audio: A Neural Network-Based Method
Mar 18, 2020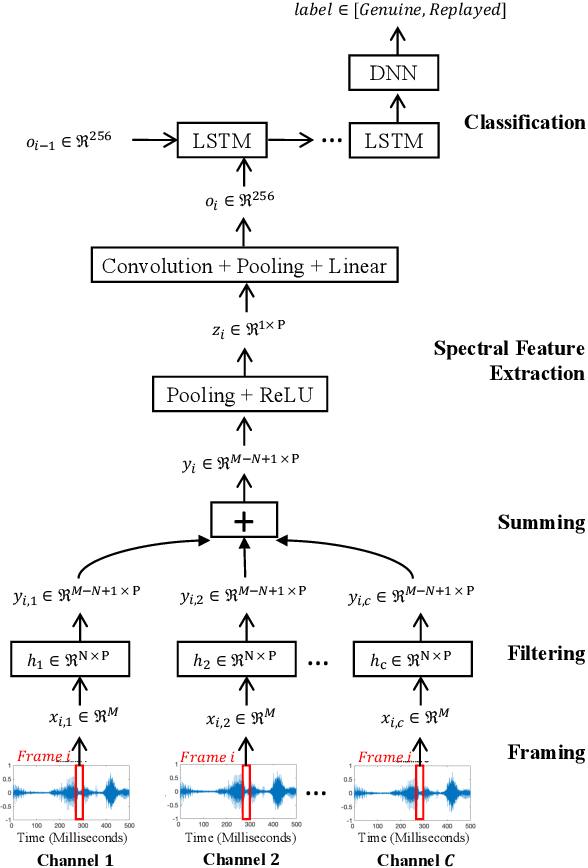
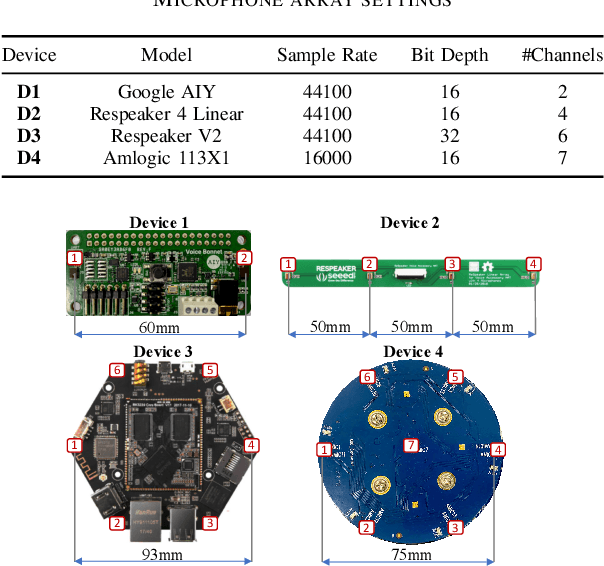
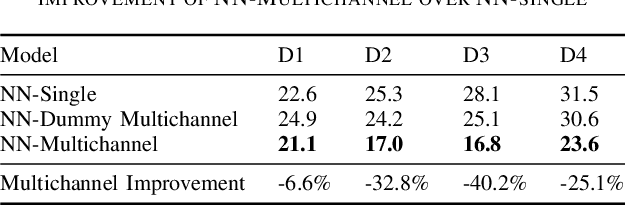

With the rapidly growing number of security-sensitive systems that use voice as the primary input, it becomes increasingly important to address these systems' potential vulnerability to replay attacks. Previous efforts to address this concern have focused primarily on single-channel audio. In this paper, we introduce a novel neural network-based replay attack detection model that further leverages spatial information of multi-channel audio and is able to significantly improve the replay attack detection performance.
Second-order Non-local Attention Networks for Person Re-identification
Aug 31, 2019



Recent efforts have shown promising results for person re-identification by designing part-based architectures to allow a neural network to learn discriminative representations from semantically coherent parts. Some efforts use soft attention to reallocate distant outliers to their most similar parts, while others adjust part granularity to incorporate more distant positions for learning the relationships. Others seek to generalize part-based methods by introducing a dropout mechanism on consecutive regions of the feature map to enhance distant region relationships. However, only few prior efforts model the distant or non-local positions of the feature map directly for the person re-ID task. In this paper, we propose a novel attention mechanism to directly model long-range relationships via second-order feature statistics. When combined with a generalized DropBlock module, our method performs equally to or better than state-of-the-art results for mainstream person re-identification datasets, including Market1501, CUHK03, and DukeMTMC-reID.
The power of dynamic social networks to predict individuals' mental health
Aug 06, 2019
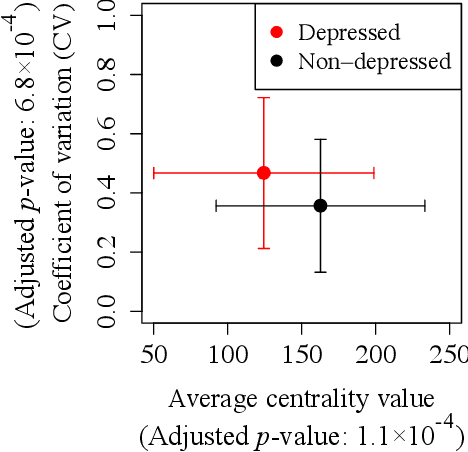
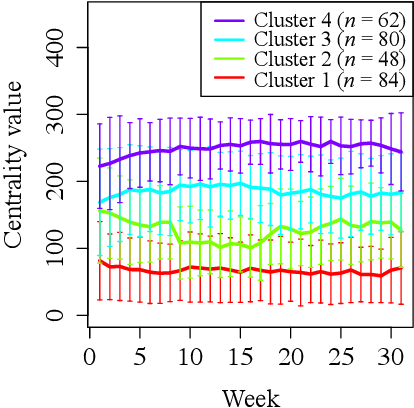
Precision medicine has received attention both in and outside the clinic. We focus on the latter, by exploiting the relationship between individuals' social interactions and their mental health to develop a predictive model of one's likelihood to be depressed or anxious from rich dynamic social network data. To our knowledge, we are the first to do this. Existing studies differ from our work in at least one aspect: they do not model social interaction data as a network; they do so but analyze static network data; they examine "correlation" between social networks and health but without developing a predictive model; or they study other individual traits but not mental health. In a systematic and comprehensive evaluation, we show that our predictive model that uses dynamic social network data is superior to its static network as well as non-network equivalents when run on the same data.
Heterogeneous network approach to predict individuals' mental health
Jun 11, 2019
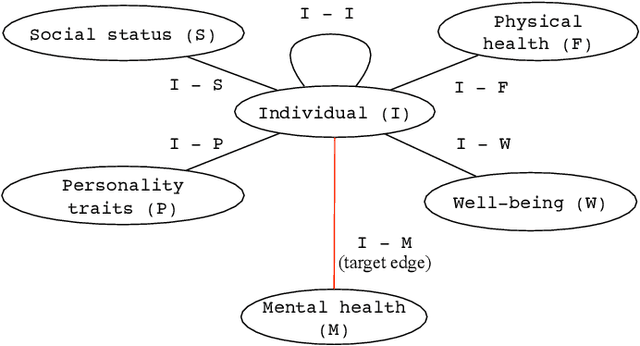

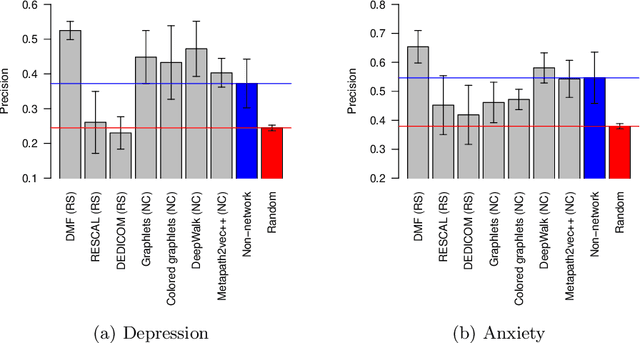
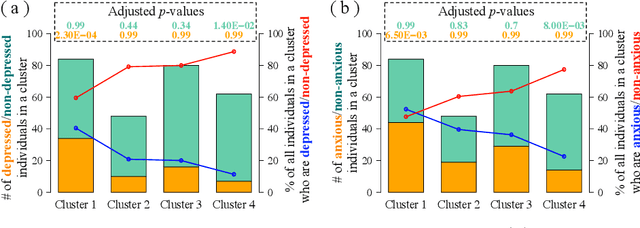
Depression and anxiety are critical public health issues affecting millions of people around the world. To identify individuals who are vulnerable to depression and anxiety, predictive models have been built that typically utilize data from one source. Unlike these traditional models, in this study, we leverage a rich heterogeneous data set from the University of Notre Dame's NetHealth study that collected individuals' (student participants') social interaction data via smartphones, health-related behavioral data via wearables (Fitbit), and trait data from surveys. To integrate the different types of information, we model the NetHealth data as a heterogeneous information network (HIN). Then, we redefine the problem of predicting individuals' mental health conditions (depression or anxiety) in a novel manner, as applying to our HIN a popular paradigm of a recommender system (RS), which is typically used to predict the preference that a person would give to an item (e.g., a movie or book). In our case, the items are the individuals' different mental health states. We evaluate three state-of-the-art RS approaches. Also, we model the prediction of individuals' mental health as another problem type -- that of node classification (NC) in our HIN, evaluating in the process four node features under logistic regression as a proof-of-concept classifier. We find that our RS and NC network methods produce more accurate predictions than a logistic regression model using the same NetHealth data in the traditional non-network fashion as well as a random-approach. Also, we find that RS outperforms NC. This is the first study to integrate smartphone, wearable sensor, and survey data in an HIN manner and use RS or NC on the HIN to predict individuals' mental health conditions.
Real-Time Adversarial Attacks
May 31, 2019


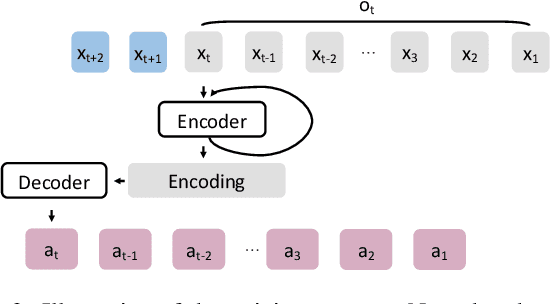
In recent years, many efforts have demonstrated that modern machine learning algorithms are vulnerable to adversarial attacks, where small, but carefully crafted, perturbations on the input can make them fail. While these attack methods are very effective, they only focus on scenarios where the target model takes static input, i.e., an attacker can observe the entire original sample and then add a perturbation at any point of the sample. These attack approaches are not applicable to situations where the target model takes streaming input, i.e., an attacker is only able to observe past data points and add perturbations to the remaining (unobserved) data points of the input. In this paper, we propose a real-time adversarial attack scheme for machine learning models with streaming inputs.
ReMASC: Realistic Replay Attack Corpus for Voice Controlled Systems
Apr 06, 2019
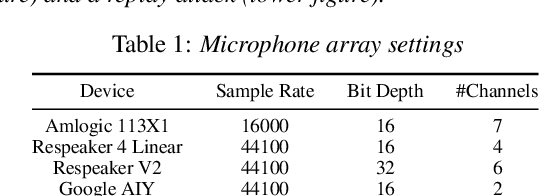

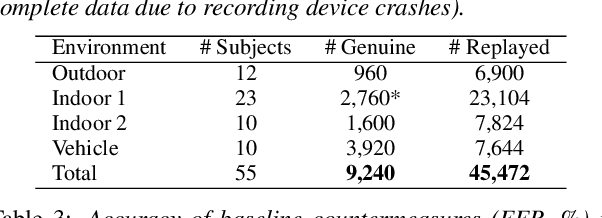
This paper introduces a new database of voice recordings with the goal of supporting research on vulnerabilities and protection of voice-controlled systems (VCSs). In contrast to prior efforts, the proposed database contains both genuine voice commands and replayed recordings of such commands, collected in realistic VCSs usage scenarios and using modern voice assistant development kits. Specifically, the database contains recordings from four systems (each with a different microphone array) in a variety of environmental conditions with different forms of background noise and relative positions between speaker and device. To the best of our knowledge, this is the first publicly available database that has been specifically designed for the protection of state-of-the-art voice-controlled systems against various replay attacks in various conditions and environments.
Towards Learning Fine-Grained Disentangled Representations from Speech
Aug 08, 2018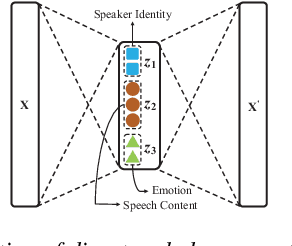

Learning disentangled representations of high-dimensional data is currently an active research area. However, compared to the field of computer vision, less work has been done for speech processing. In this paper, we provide a review of two representative efforts on this topic and propose the novel concept of fine-grained disentangled speech representation learning.