Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning Fine-Grained Disentangled Representations from Speech
Paper and Code
Aug 08, 2018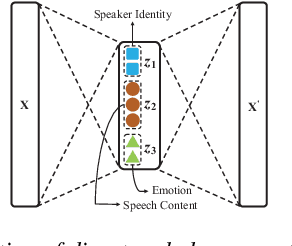

Learning disentangled representations of high-dimensional data is currently an active research area. However, compared to the field of computer vision, less work has been done for speech processing. In this paper, we provide a review of two representative efforts on this topic and propose the novel concept of fine-grained disentangled speech representation learning.
View paper on