Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling Based Multi-modal Depression Detection
Paper and Code
Mar 28, 2018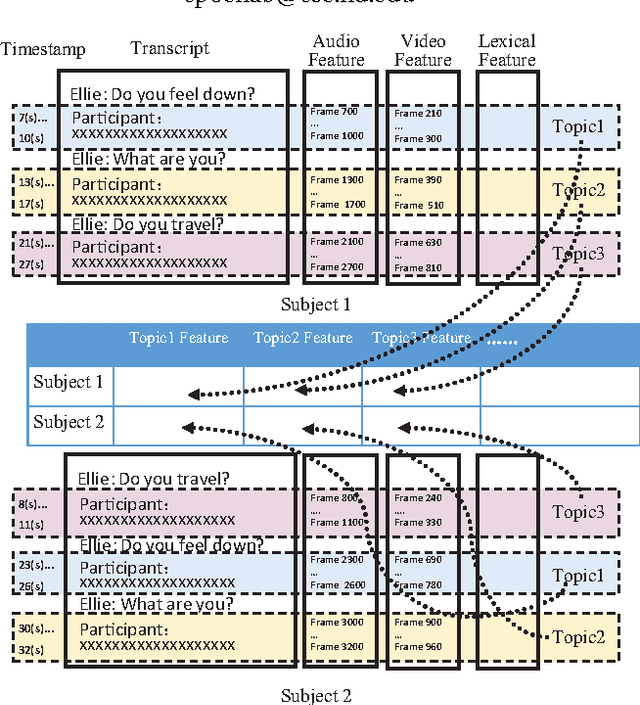
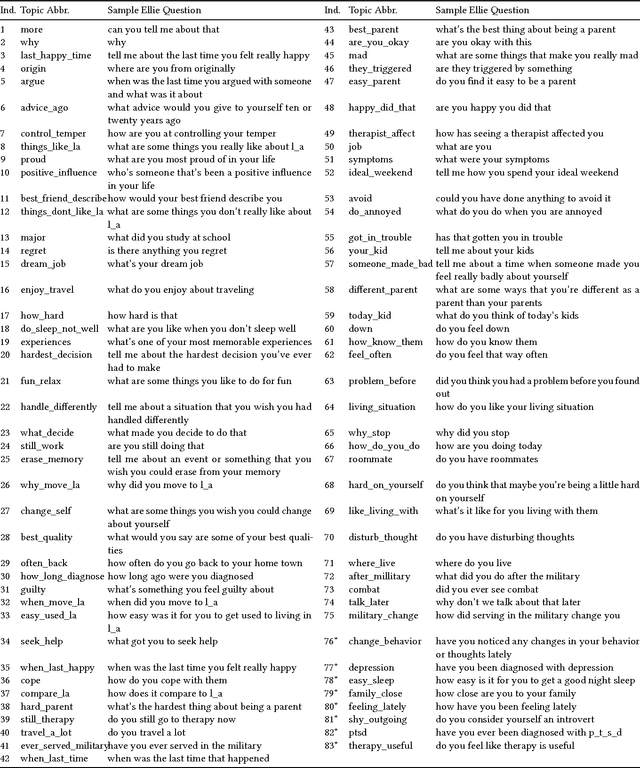


Major depressive disorder is a common mental disorder that affects almost 7% of the adult U.S. population. The 2017 Audio/Visual Emotion Challenge (AVEC) asks participants to build a model to predict depression levels based on the audio, video, and text of an interview ranging between 7-33 minutes. Since averaging features over the entire interview will lose most temporal information, how to discover, capture, and preserve useful temporal details for such a long interview are significant challenges. Therefore, we propose a novel topic modeling based approach to perform context-aware analysis of the recording. Our experiments show that the proposed approach outperforms context-unaware methods and the challenge baselines for all metrics.
* Proceedings of the 7th Audio/Visual Emotion Challenge and Workshop
(AVEC). (Official Depression Challenge Winner)
View paper on