 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedication Error Detection Using Contextual Language Models
Paper and Code
Jan 09, 2022
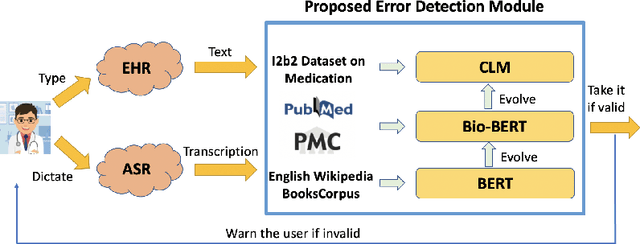
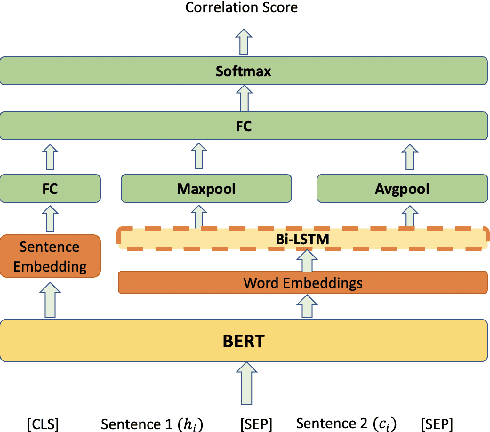
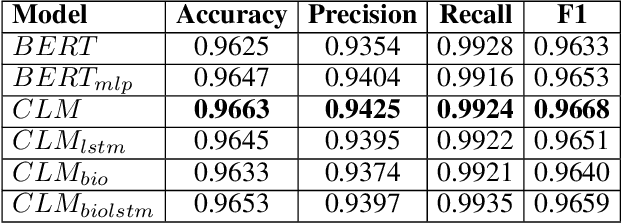
Medication errors most commonly occur at the ordering or prescribing stage, potentially leading to medical complications and poor health outcomes. While it is possible to catch these errors using different techniques; the focus of this work is on textual and contextual analysis of prescription information to detect and prevent potential medication errors. In this paper, we demonstrate how to use BERT-based contextual language models to detect anomalies in written or spoken text based on a data set extracted from real-world medical data of thousands of patient records. The proposed models are able to learn patterns of text dependency and predict erroneous output based on contextual information such as patient data. The experimental results yield accuracy up to 96.63% for text input and up to 79.55% for speech input, which is satisfactory for most real-world applications.