 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriplet Interaction Improves Graph Transformers: Accurate Molecular Graph Learning with Triplet Graph Transformers
Feb 07, 2024



Graph transformers typically lack direct pair-to-pair communication, instead forcing neighboring pairs to exchange information via a common node. We propose the Triplet Graph Transformer (TGT) that enables direct communication between two neighboring pairs in a graph via novel triplet attention and aggregation mechanisms. TGT is applied to molecular property prediction by first predicting interatomic distances from 2D graphs and then using these distances for downstream tasks. A novel three-stage training procedure and stochastic inference further improve training efficiency and model performance. Our model achieves new state-of-the-art (SOTA) results on open challenge benchmarks PCQM4Mv2 and OC20 IS2RE. We also obtain SOTA results on QM9, MOLPCBA, and LIT-PCBA molecular property prediction benchmarks via transfer learning. We also demonstrate the generality of TGT with SOTA results on the traveling salesman problem (TSP).
The Information Pathways Hypothesis: Transformers are Dynamic Self-Ensembles
Jun 02, 2023



Transformers use the dense self-attention mechanism which gives a lot of flexibility for long-range connectivity. Over multiple layers of a deep transformer, the number of possible connectivity patterns increases exponentially. However, very few of these contribute to the performance of the network, and even fewer are essential. We hypothesize that there are sparsely connected sub-networks within a transformer, called information pathways which can be trained independently. However, the dynamic (i.e., input-dependent) nature of these pathways makes it difficult to prune dense self-attention during training. But the overall distribution of these pathways is often predictable. We take advantage of this fact to propose Stochastically Subsampled self-Attention (SSA) - a general-purpose training strategy for transformers that can reduce both the memory and computational cost of self-attention by 4 to 8 times during training while also serving as a regularization method - improving generalization over dense training. We show that an ensemble of sub-models can be formed from the subsampled pathways within a network, which can achieve better performance than its densely attended counterpart. We perform experiments on a variety of NLP, computer vision and graph learning tasks in both generative and discriminative settings to provide empirical evidence for our claims and show the effectiveness of the proposed method.
Edge-augmented Graph Transformers: Global Self-attention is Enough for Graphs
Aug 07, 2021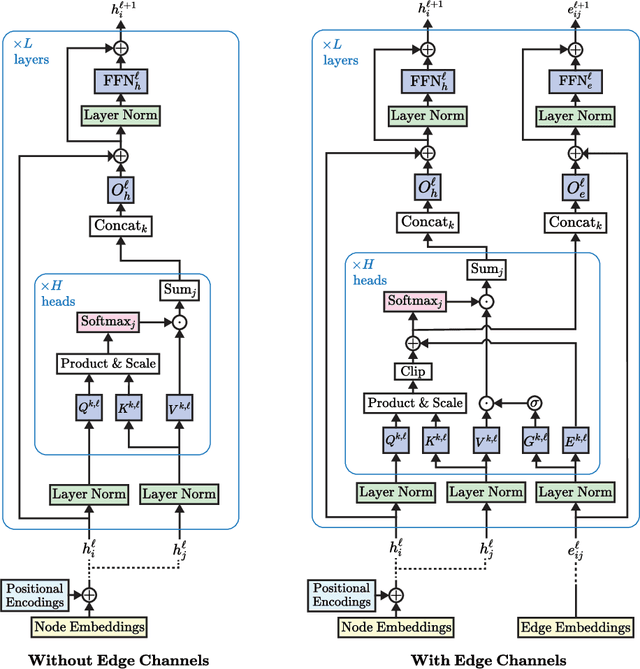

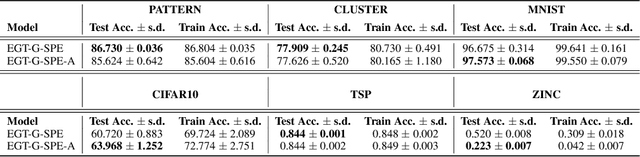
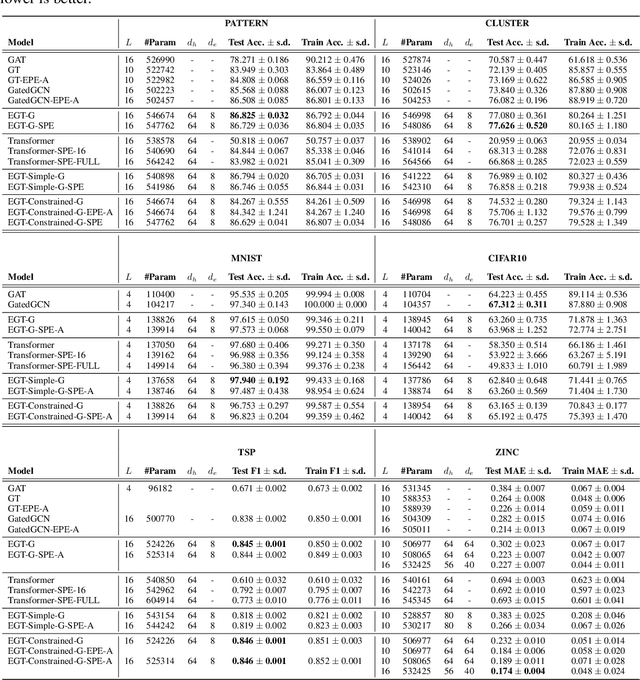
Transformer neural networks have achieved state-of-the-art results for unstructured data such as text and images but their adoption for graph-structured data has been limited. This is partly due to the difficulty in incorporating complex structural information in the basic transformer framework. We propose a simple yet powerful extension to the transformer - residual edge channels. The resultant framework, which we call Edge-augmented Graph Transformer (EGT), can directly accept, process and output structural information as well as node information. This simple addition allows us to use global self-attention, the key element of transformers, directly for graphs and comes with the benefit of long-range interaction among nodes. Moreover, the edge channels allow the structural information to evolve from layer to layer, and prediction tasks on edges can be derived directly from these channels. In addition to that, we introduce positional encodings based on Singular Value Decomposition which can improve the performance of EGT. Our framework, which relies on global node feature aggregation, achieves better performance compared to Graph Convolutional Networks (GCN), which rely on local feature aggregation within a neighborhood. We verify the performance of EGT in a supervised learning setting on a wide range of experiments on benchmark datasets. Our findings indicate that convolutional aggregation is not an essential inductive bias for graphs and global self-attention can serve as a flexible and adaptive alternative to graph convolution.