 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-augmented Graph Transformers: Global Self-attention is Enough for Graphs
Paper and Code
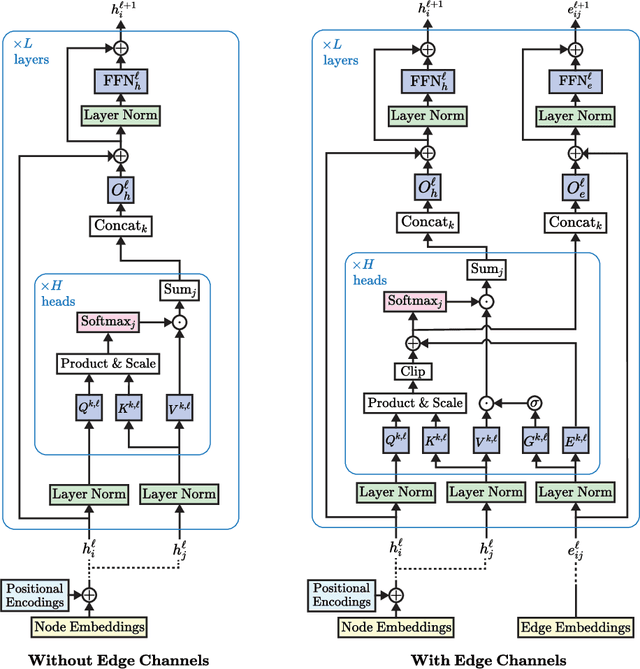

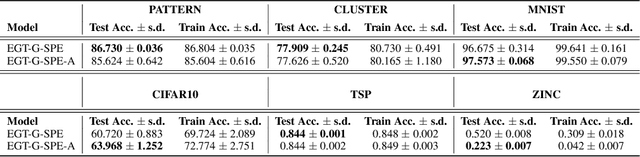
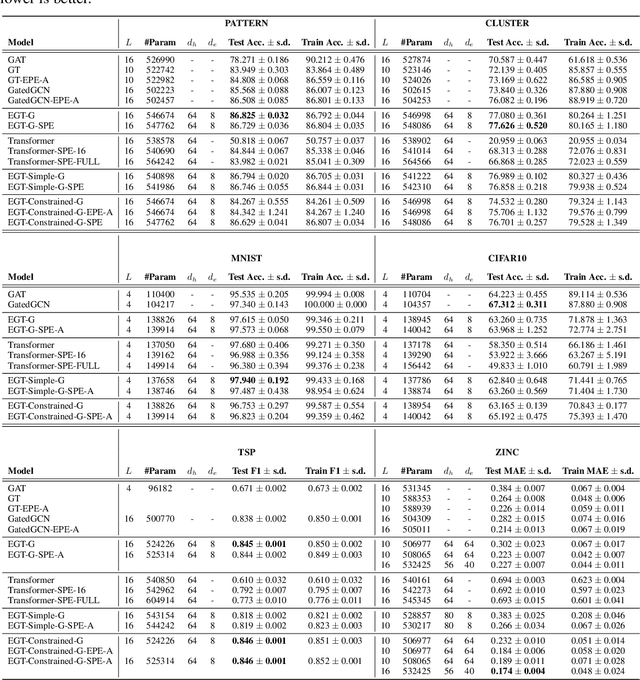
Transformer neural networks have achieved state-of-the-art results for unstructured data such as text and images but their adoption for graph-structured data has been limited. This is partly due to the difficulty in incorporating complex structural information in the basic transformer framework. We propose a simple yet powerful extension to the transformer - residual edge channels. The resultant framework, which we call Edge-augmented Graph Transformer (EGT), can directly accept, process and output structural information as well as node information. This simple addition allows us to use global self-attention, the key element of transformers, directly for graphs and comes with the benefit of long-range interaction among nodes. Moreover, the edge channels allow the structural information to evolve from layer to layer, and prediction tasks on edges can be derived directly from these channels. In addition to that, we introduce positional encodings based on Singular Value Decomposition which can improve the performance of EGT. Our framework, which relies on global node feature aggregation, achieves better performance compared to Graph Convolutional Networks (GCN), which rely on local feature aggregation within a neighborhood. We verify the performance of EGT in a supervised learning setting on a wide range of experiments on benchmark datasets. Our findings indicate that convolutional aggregation is not an essential inductive bias for graphs and global self-attention can serve as a flexible and adaptive alternative to graph convolution.