 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Unified Real-time Personalized and Non-Personalized Speech Enhancement
Feb 23, 2023



In this study, we present an approach to train a single speech enhancement network that can perform both personalized and non-personalized speech enhancement. This is achieved by incorporating a frame-wise conditioning input that specifies the type of enhancement output. To improve the quality of the enhanced output and mitigate oversuppression, we experiment with re-weighting frames by the presence or absence of speech activity and applying augmentations to speaker embeddings. By training under a multi-task learning setting, we empirically show that the proposed unified model obtains promising results on both personalized and non-personalized speech enhancement benchmarks and reaches similar performance to models that are trained specialized for either task. The strong performance of the proposed method demonstrates that the unified model is a more economical alternative compared to keeping separate task-specific models during inference.
Attacking Compressed Vision Transformers
Sep 28, 2022
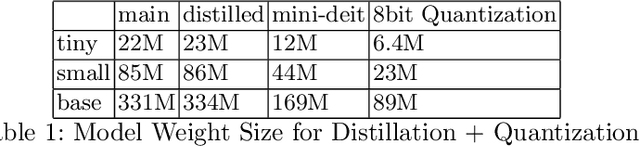

Vision Transformers are increasingly embedded in industrial systems due to their superior performance, but their memory and power requirements make deploying them to edge devices a challenging task. Hence, model compression techniques are now widely used to deploy models on edge devices as they decrease the resource requirements and make model inference very fast and efficient. But their reliability and robustness from a security perspective is another major issue in safety-critical applications. Adversarial attacks are like optical illusions for ML algorithms and they can severely impact the accuracy and reliability of models. In this work we investigate the transferability of adversarial samples across the SOTA Vision Transformer models across 3 SOTA compressed versions and infer the effects different compression techniques have on adversarial attacks.
Adversarial training in communication constrained federated learning
Mar 01, 2021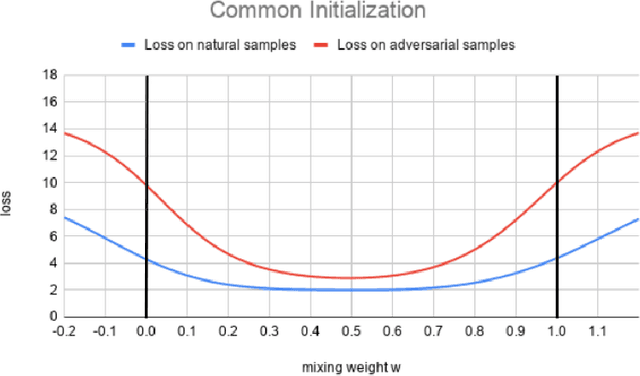
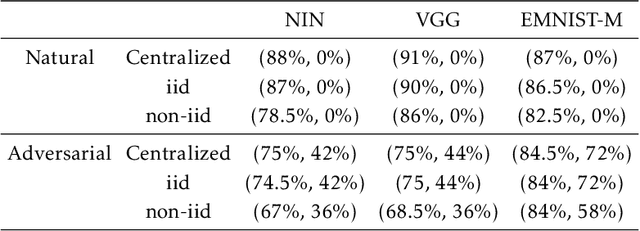
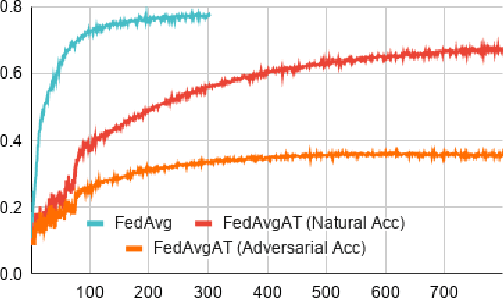
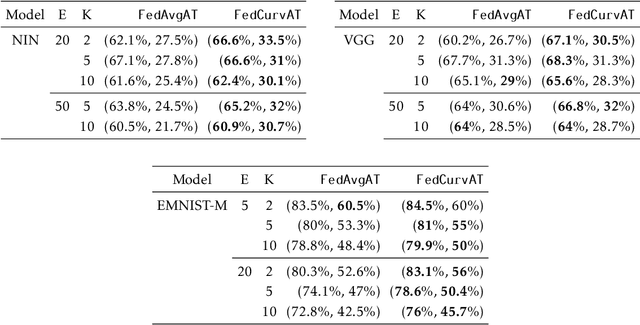
Federated learning enables model training over a distributed corpus of agent data. However, the trained model is vulnerable to adversarial examples, designed to elicit misclassification. We study the feasibility of using adversarial training (AT) in the federated learning setting. Furthermore, we do so assuming a fixed communication budget and non-iid data distribution between participating agents. We observe a significant drop in both natural and adversarial accuracies when AT is used in the federated setting as opposed to centralized training. We attribute this to the number of epochs of AT performed locally at the agents, which in turn effects (i) drift between local models; and (ii) convergence time (measured in number of communication rounds). Towards this end, we propose FedDynAT, a novel algorithm for performing AT in federated setting. Through extensive experimentation we show that FedDynAT significantly improves both natural and adversarial accuracy, as well as model convergence time by reducing the model drift.