 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBFTrainer: Low-Cost Training of Neural Networks on Unfillable Supercomputer Nodes
Paper and Code
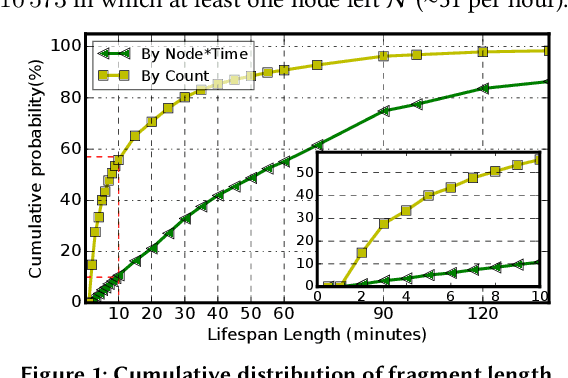
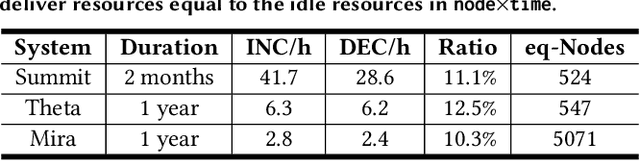
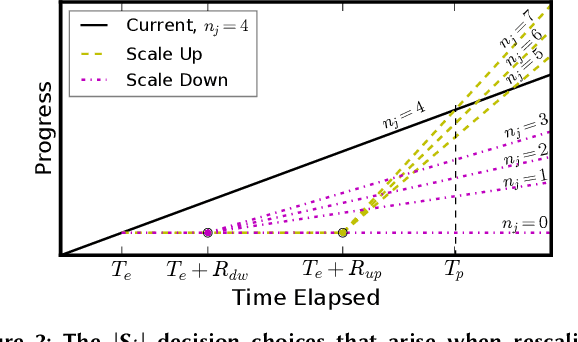
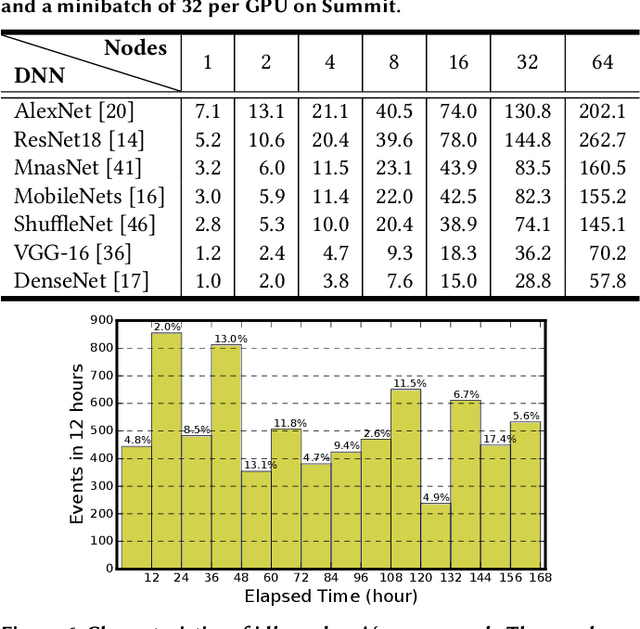
Supercomputer FCFS-based scheduling policies result in many transient idle nodes, a phenomenon that is only partially alleviated by backfill scheduling methods that promote small jobs to run before large jobs. Here we describe how to realize a novel use for these otherwise wasted resources, namely, deep neural network (DNN) training. This important workload is easily organized as many small fragments that can be configured dynamically to fit essentially any node*time hole in a supercomputer's schedule. We describe how the task of rescaling suitable DNN training tasks to fit dynamically changing holes can be formulated as a deterministic mixed integer linear programming (MILP)-based resource allocation algorithm, and show that this MILP problem can be solved efficiently at run time. We show further how this MILP problem can be adapted to optimize for administrator- or user-defined metrics. We validate our method with supercomputer scheduler logs and different DNN training scenarios, and demonstrate efficiencies of up to 93% compared with running the same training tasks on dedicated nodes. Our method thus enables substantial supercomputer resources to be allocated to DNN training with no impact on other applications.