 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Calibration as a Function of the Evolution of Uncertainty in Knowledge Generation: A Survey
Sep 09, 2022User trust is a crucial consideration in designing robust visual analytics systems that can guide users to reasonably sound conclusions despite inevitable biases and other uncertainties introduced by the human, the machine, and the data sources which paint the canvas upon which knowledge emerges. A multitude of factors emerge upon studied consideration which introduce considerable complexity and exacerbate our understanding of how trust relationships evolve in visual analytics systems, much as they do in intelligent sociotechnical systems. A visual analytics system, however, does not by its nature provoke exactly the same phenomena as its simpler cousins, nor are the phenomena necessarily of the same exact kind. Regardless, both application domains present the same root causes from which the need for trustworthiness arises: Uncertainty and the assumption of risk. In addition, visual analytics systems, even more than the intelligent systems which (traditionally) tend to be closed to direct human input and direction during processing, are influenced by a multitude of cognitive biases that further exacerbate an accounting of the uncertainties that may afflict the user's confidence, and ultimately trust in the system. In this article we argue that accounting for the propagation of uncertainty from data sources all the way through extraction of information and hypothesis testing is necessary to understand how user trust in a visual analytics system evolves over its lifecycle, and that the analyst's selection of visualization parameters affords us a simple means to capture the interactions between uncertainty and cognitive bias as a function of the attributes of the search tasks the analyst executes while evaluating explanations. We sample a broad cross-section of the literature from visual analytics, human cognitive theory, and uncertainty, and attempt to synthesize a useful perspective.
YouTube and Science: Models for Research Impact
Sep 01, 2022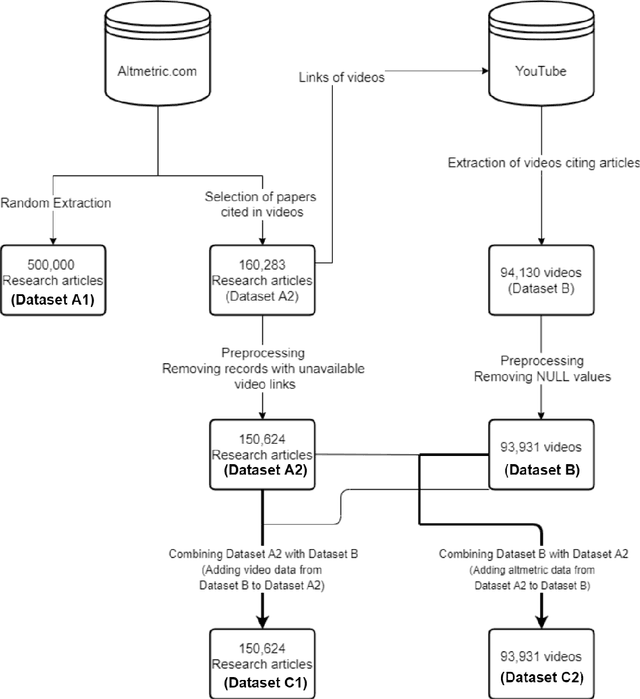
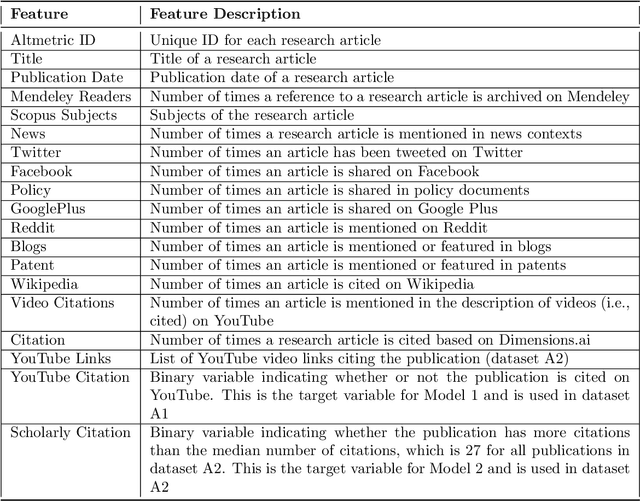

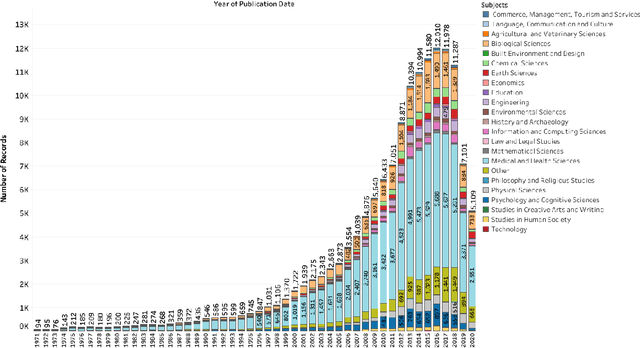
Video communication has been rapidly increasing over the past decade, with YouTube providing a medium where users can post, discover, share, and react to videos. There has also been an increase in the number of videos citing research articles, especially since it has become relatively commonplace for academic conferences to require video submissions. However, the relationship between research articles and YouTube videos is not clear, and the purpose of the present paper is to address this issue. We created new datasets using YouTube videos and mentions of research articles on various online platforms. We found that most of the articles cited in the videos are related to medicine and biochemistry. We analyzed these datasets through statistical techniques and visualization, and built machine learning models to predict (1) whether a research article is cited in videos, (2) whether a research article cited in a video achieves a level of popularity, and (3) whether a video citing a research article becomes popular. The best models achieved F1 scores between 80% and 94%. According to our results, research articles mentioned in more tweets and news coverage have a higher chance of receiving video citations. We also found that video views are important for predicting citations and increasing research articles' popularity and public engagement with science.