 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Multi-Site Clinical Data: A Federated Approach to Privacy-First Child Autism Behavior Analysis
Apr 03, 2026Automated recognition of autistic behaviors in children is essential for early intervention and objective clinical assessment. However, the development of robust models is severely hindered by strict privacy regulations (e.g., HIPAA) and the sensitive nature of pediatric data, which prevents the centralized aggregation of clinical datasets. Furthermore, individual clinical sites often suffer from data scarcity, making it difficult to learn generalized behavior patterns or tailor models to site-specific patient distributions. To address these challenges, we observe that Federated Learning (FL) can decouple model training from raw data access, enabling multi-site collaboration while maintaining strict data residency. In this paper, we present the first study exploring Federated Learning for pose-based child autism behavior recognition. Our framework employs a two-layer privacy protection mechanism: utilizing human skeletal abstraction to remove identifiable visual information from the raw RGB videos and FL to ensure sensitive pose data remains within the clinic. This approach leverages distributed clinical data to learn generalized representations while providing the flexibility for site-specific personalization. Experimental results on the MMASD benchmark demonstrate that our framework achieves high recognition accuracy, outperforming traditional federated baselines and providing a robust, privacy-first solution for multi-site clinical analysis.
KHMP: Frequency-Domain Kalman Refinement for High-Fidelity Human Motion Prediction
Mar 22, 2026Stochastic human motion prediction aims to generate diverse, plausible futures from observed sequences. Despite advances in generative modeling, existing methods often produce predictions corrupted by high-frequency jitter and temporal discontinuities. To address these challenges, we introduce KHMP, a novel framework featuring an adaptiveKalman filter applied in the DCT domain to generate high-fidelity human motion predictions. By treating high-frequency DCT coefficients as a frequency-indexed noisy signal, the Kalman filter recursively suppresses noise while preserving motion details. Notably, its noise parameters are dynamically adjusted based on estimated Signal-to-Noise Ratio (SNR), enabling aggressive denoising for jittery predictions and conservative filtering for clean motions. This refinement is complemented by training-time physical constraints (temporal smoothness and joint angle limits) that encode biomechanical principles into the generative model. Together, these innovations establish a new paradigm integrating adaptive signal processing with physics-informed learning. Experiments on the Human3.6M and HumanEva-I datasets demonstrate that KHMP achieves state-of-the-art accuracy, effectively mitigating jitter artifacts to produce smooth and physically plausible motions.
Monocular Models are Strong Learners for Multi-View Human Mesh Recovery
Mar 20, 2026Multi-view human mesh recovery (HMR) is broadly deployed in diverse domains where high accuracy and strong generalization are essential. Existing approaches can be broadly grouped into geometry-based and learning-based methods. However, geometry-based methods (e.g., triangulation) rely on cumbersome camera calibration, while learning-based approaches often generalize poorly to unseen camera configurations due to the lack of multi-view training data, limiting their performance in real-world scenarios. To enable calibration-free reconstruction that generalizes to arbitrary camera setups, we propose a training-free framework that leverages pretrained single-view HMR models as strong priors, eliminating the need for multi-view training data. Our method first constructs a robust and consistent multi-view initialization from single-view predictions, and then refines it via test-time optimization guided by multi-view consistency and anatomical constraints. Extensive experiments demonstrate state-of-the-art performance on standard benchmarks, surpassing multi-view models trained with explicit multi-view supervision.
Communication-Efficient Federated AUC Maximization with Cyclic Client Participation
Jan 04, 2026Federated AUC maximization is a powerful approach for learning from imbalanced data in federated learning (FL). However, existing methods typically assume full client availability, which is rarely practical. In real-world FL systems, clients often participate in a cyclic manner: joining training according to a fixed, repeating schedule. This setting poses unique optimization challenges for the non-decomposable AUC objective. This paper addresses these challenges by developing and analyzing communication-efficient algorithms for federated AUC maximization under cyclic client participation. We investigate two key settings: First, we study AUC maximization with a squared surrogate loss, which reformulates the problem as a nonconvex-strongly-concave minimax optimization. By leveraging the Polyak-Łojasiewicz (PL) condition, we establish a state-of-the-art communication complexity of $\widetilde{O}(1/ε^{1/2})$ and iteration complexity of $\widetilde{O}(1/ε)$. Second, we consider general pairwise AUC losses. We establish a communication complexity of $O(1/ε^3)$ and an iteration complexity of $O(1/ε^4)$. Further, under the PL condition, these bounds improve to communication complexity of $\widetilde{O}(1/ε^{1/2})$ and iteration complexity of $\widetilde{O}(1/ε)$. Extensive experiments on benchmark tasks in image classification, medical imaging, and fraud detection demonstrate the superior efficiency and effectiveness of our proposed methods.
REMISVFU: Vertical Federated Unlearning via Representation Misdirection for Intermediate Output Feature
Dec 11, 2025
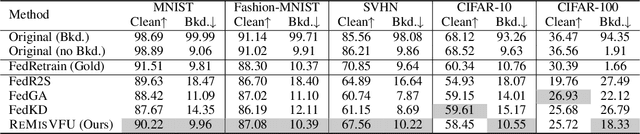


Data-protection regulations such as the GDPR grant every participant in a federated system a right to be forgotten. Federated unlearning has therefore emerged as a research frontier, aiming to remove a specific party's contribution from the learned model while preserving the utility of the remaining parties. However, most unlearning techniques focus on Horizontal Federated Learning (HFL), where data are partitioned by samples. In contrast, Vertical Federated Learning (VFL) allows organizations that possess complementary feature spaces to train a joint model without sharing raw data. The resulting feature-partitioned architecture renders HFL-oriented unlearning methods ineffective. In this paper, we propose REMISVFU, a plug-and-play representation misdirection framework that enables fast, client-level unlearning in splitVFL systems. When a deletion request arrives, the forgetting party collapses its encoder output to a randomly sampled anchor on the unit sphere, severing the statistical link between its features and the global model. To maintain utility for the remaining parties, the server jointly optimizes a retention loss and a forgetting loss, aligning their gradients via orthogonal projection to eliminate destructive interference. Evaluations on public benchmarks show that REMISVFU suppresses back-door attack success to the natural class-prior level and sacrifices only about 2.5% points of clean accuracy, outperforming state-of-the-art baselines.
UniSTFormer: Unified Spatio-Temporal Lightweight Transformer for Efficient Skeleton-Based Action Recognition
Aug 12, 2025



Skeleton-based action recognition (SAR) has achieved impressive progress with transformer architectures. However, existing methods often rely on complex module compositions and heavy designs, leading to increased parameter counts, high computational costs, and limited scalability. In this paper, we propose a unified spatio-temporal lightweight transformer framework that integrates spatial and temporal modeling within a single attention module, eliminating the need for separate temporal modeling blocks. This approach reduces redundant computations while preserving temporal awareness within the spatial modeling process. Furthermore, we introduce a simplified multi-scale pooling fusion module that combines local and global pooling pathways to enhance the model's ability to capture fine-grained local movements and overarching global motion patterns. Extensive experiments on benchmark datasets demonstrate that our lightweight model achieves a superior balance between accuracy and efficiency, reducing parameter complexity by over 58% and lowering computational cost by over 60% compared to state-of-the-art transformer-based baselines, while maintaining competitive recognition performance.
FreqMixFormerV2: Lightweight Frequency-aware Mixed Transformer for Human Skeleton Action Recognition
Dec 29, 2024Transformer-based human skeleton action recognition has been developed for years. However, the complexity and high parameter count demands of these models hinder their practical applications, especially in resource-constrained environments. In this work, we propose FreqMixForemrV2, which was built upon the Frequency-aware Mixed Transformer (FreqMixFormer) for identifying subtle and discriminative actions with pioneered frequency-domain analysis. We design a lightweight architecture that maintains robust performance while significantly reducing the model complexity. This is achieved through a redesigned frequency operator that optimizes high-frequency and low-frequency parameter adjustments, and a simplified frequency-aware attention module. These improvements result in a substantial reduction in model parameters, enabling efficient deployment with only a minimal sacrifice in accuracy. Comprehensive evaluations of standard datasets (NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets) demonstrate that the proposed model achieves a superior balance between efficiency and accuracy, outperforming state-of-the-art methods with only 60% of the parameters.
Frequency Guidance Matters: Skeletal Action Recognition by Frequency-Aware Mixed Transformer
Jul 17, 2024Recently, transformers have demonstrated great potential for modeling long-term dependencies from skeleton sequences and thereby gained ever-increasing attention in skeleton action recognition. However, the existing transformer-based approaches heavily rely on the naive attention mechanism for capturing the spatiotemporal features, which falls short in learning discriminative representations that exhibit similar motion patterns. To address this challenge, we introduce the Frequency-aware Mixed Transformer (FreqMixFormer), specifically designed for recognizing similar skeletal actions with subtle discriminative motions. First, we introduce a frequency-aware attention module to unweave skeleton frequency representations by embedding joint features into frequency attention maps, aiming to distinguish the discriminative movements based on their frequency coefficients. Subsequently, we develop a mixed transformer architecture to incorporate spatial features with frequency features to model the comprehensive frequency-spatial patterns. Additionally, a temporal transformer is proposed to extract the global correlations across frames. Extensive experiments show that FreqMiXFormer outperforms SOTA on 3 popular skeleton action recognition datasets, including NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
DevBench: A Comprehensive Benchmark for Software Development
Mar 15, 2024



Recent advancements in large language models (LLMs) have significantly enhanced their coding capabilities. However, existing benchmarks predominantly focused on simplified or isolated aspects of programming, such as single-file code generation or repository issue debugging, falling short of measuring the full spectrum of challenges raised by real-world programming activities. To this end, we propose DevBench, a comprehensive benchmark that evaluates LLMs across various stages of the software development lifecycle, including software design, environment setup, implementation, acceptance testing, and unit testing. DevBench features a wide range of programming languages and domains, high-quality data collection, and carefully designed and verified metrics for each task. Empirical studies show that current LLMs, including GPT-4-Turbo, fail to solve the challenges presented within DevBench. Analyses reveal that models struggle with understanding the complex structures in the repository, managing the compilation process, and grasping advanced programming concepts. Our findings offer actionable insights for the future development of LLMs toward real-world programming applications. Our benchmark is available at https://github.com/open-compass/DevBench
Food-500 Cap: A Fine-Grained Food Caption Benchmark for Evaluating Vision-Language Models
Aug 06, 2023
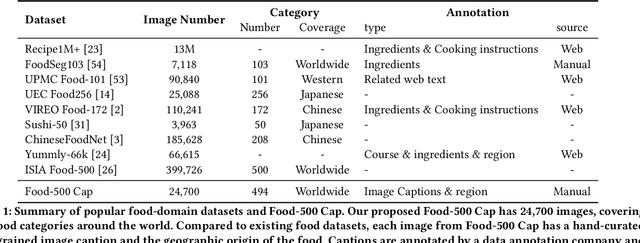
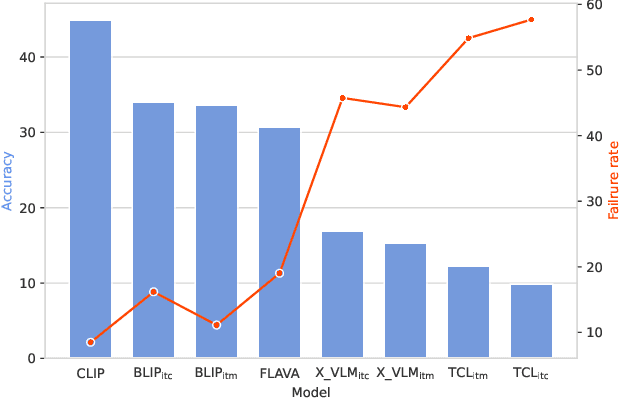
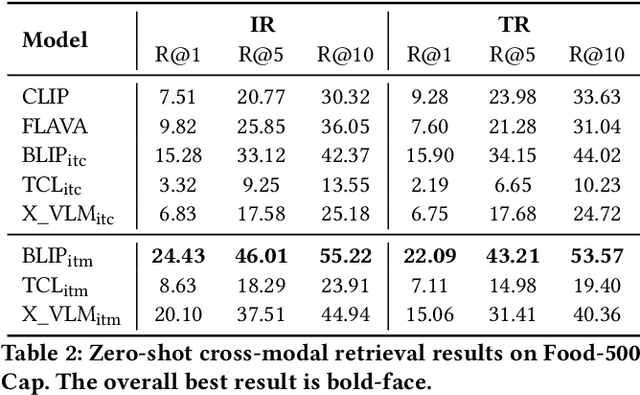
Vision-language models (VLMs) have shown impressive performance in substantial downstream multi-modal tasks. However, only comparing the fine-tuned performance on downstream tasks leads to the poor interpretability of VLMs, which is adverse to their future improvement. Several prior works have identified this issue and used various probing methods under a zero-shot setting to detect VLMs' limitations, but they all examine VLMs using general datasets instead of specialized ones. In practical applications, VLMs are usually applied to specific scenarios, such as e-commerce and news fields, so the generalization of VLMs in specific domains should be given more attention. In this paper, we comprehensively investigate the capabilities of popular VLMs in a specific field, the food domain. To this end, we build a food caption dataset, Food-500 Cap, which contains 24,700 food images with 494 categories. Each image is accompanied by a detailed caption, including fine-grained attributes of food, such as the ingredient, shape, and color. We also provide a culinary culture taxonomy that classifies each food category based on its geographic origin in order to better analyze the performance differences of VLM in different regions. Experiments on our proposed datasets demonstrate that popular VLMs underperform in the food domain compared with their performance in the general domain. Furthermore, our research reveals severe bias in VLMs' ability to handle food items from different geographic regions. We adopt diverse probing methods and evaluate nine VLMs belonging to different architectures to verify the aforementioned observations. We hope that our study will bring researchers' attention to VLM's limitations when applying them to the domain of food or culinary cultures, and spur further investigations to address this issue.