 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Ordered Recent Event Volumes for Event Cameras
Mar 10, 2021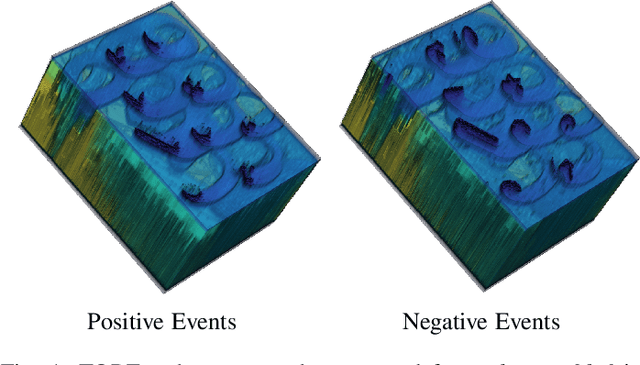

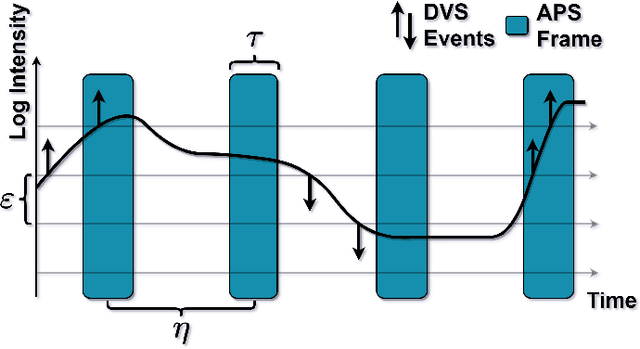
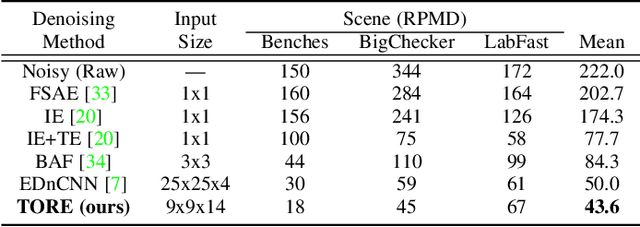
Event cameras are an exciting, new sensor modality enabling high-speed imaging with extremely low-latency and wide dynamic range. Unfortunately, most machine learning architectures are not designed to directly handle sparse data, like that generated from event cameras. Many state-of-the-art algorithms for event cameras rely on interpolated event representations - obscuring crucial timing information, increasing the data volume, and limiting overall network performance. This paper details an event representation called Time-Ordered Recent Event (TORE) volumes. TORE volumes are designed to compactly store raw spike timing information with minimal information loss. This bio-inspired design is memory efficient, computationally fast, avoids time-blocking (i.e. fixed and predefined frame rates), and contains "local memory" from past data. The design is evaluated on a wide range of challenging tasks (e.g. event denoising, image reconstruction, classification, and human pose estimation) and is shown to dramatically improve state-of-the-art performance. TORE volumes are an easy-to-implement replacement for any algorithm currently utilizing event representations.
Enhanced 3D Human Pose Estimation from Videos by using Attention-Based Neural Network with Dilated Convolutions
Mar 04, 2021
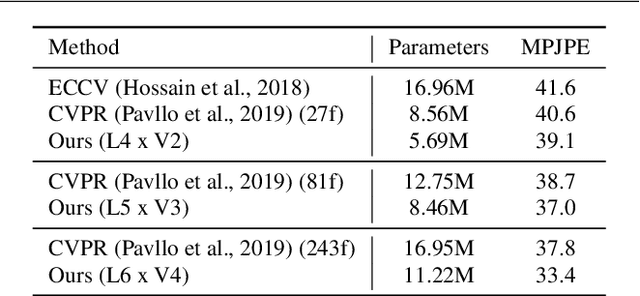
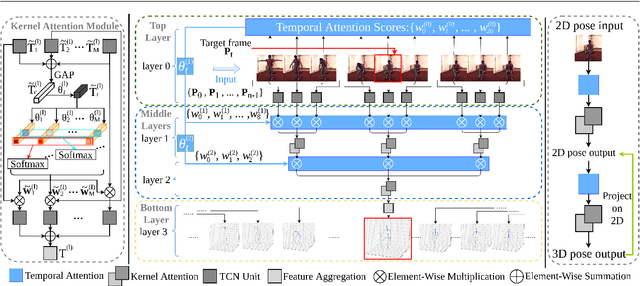
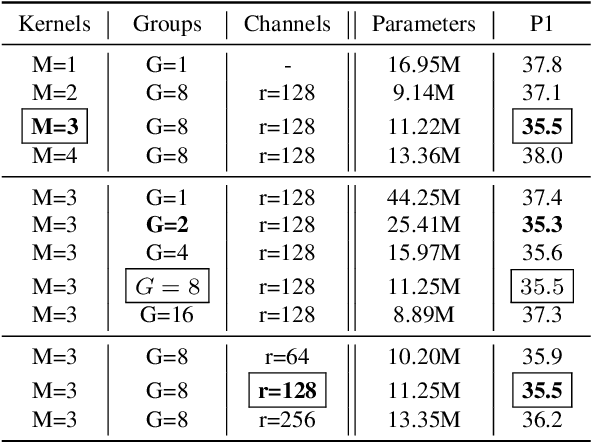
The attention mechanism provides a sequential prediction framework for learning spatial models with enhanced implicit temporal consistency. In this work, we show a systematic design (from 2D to 3D) for how conventional networks and other forms of constraints can be incorporated into the attention framework for learning long-range dependencies for the task of pose estimation. The contribution of this paper is to provide a systematic approach for designing and training of attention-based models for the end-to-end pose estimation, with the flexibility and scalability of arbitrary video sequences as input. We achieve this by adapting temporal receptive field via a multi-scale structure of dilated convolutions. Besides, the proposed architecture can be easily adapted to a causal model enabling real-time performance. Any off-the-shelf 2D pose estimation systems, e.g. Mocap libraries, can be easily integrated in an ad-hoc fashion. Our method achieves the state-of-the-art performance and outperforms existing methods by reducing the mean per joint position error to 33.4 mm on Human3.6M dataset.
Deep Learning-Based Human Pose Estimation: A Survey
Jan 02, 2021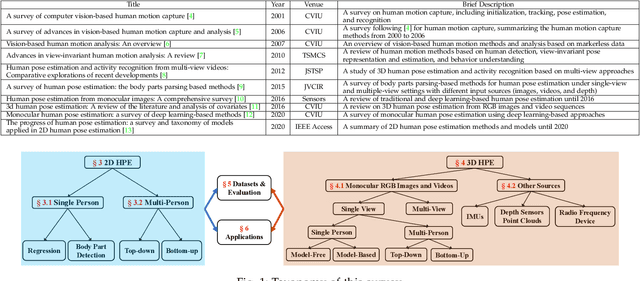
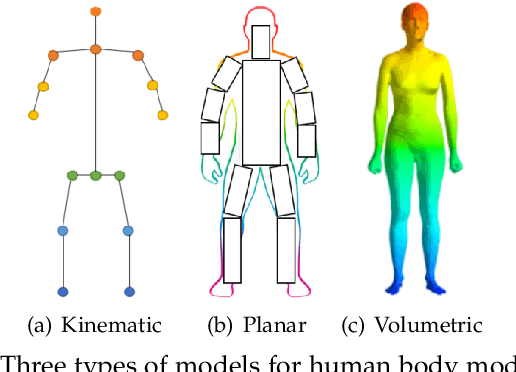
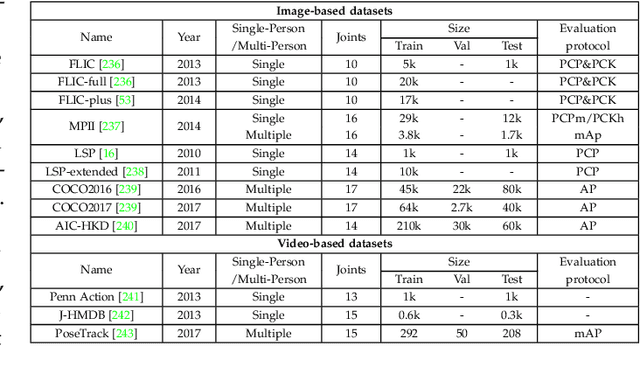
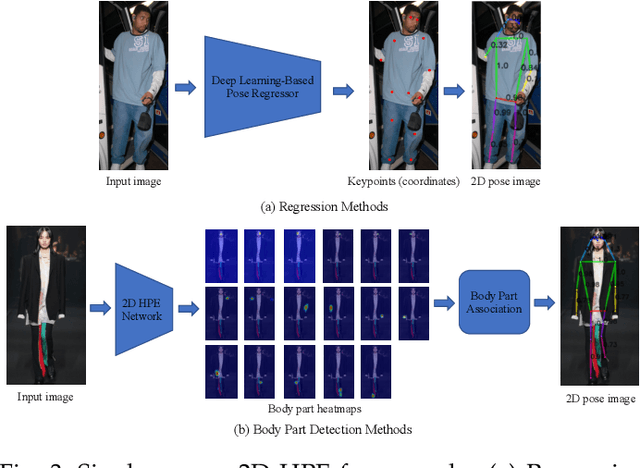
Human pose estimation aims to locate the human body parts and build human body representation (e.g., body skeleton) from input data such as images and videos. It has drawn increasing attention during the past decade and has been utilized in a wide range of applications including human-computer interaction, motion analysis, augmented reality, and virtual reality. Although the recently developed deep learning-based solutions have achieved high performance in human pose estimation, there still remain challenges due to insufficient training data, depth ambiguities, and occlusion. The goal of this survey paper is to provide a comprehensive review of recent deep learning-based solutions for both 2D and 3D pose estimation via a systematic analysis and comparison of these solutions based on their input data and inference procedures. More than 240 research papers since 2014 are covered in this survey. Furthermore, 2D and 3D human pose estimation datasets and evaluation metrics are included. Quantitative performance comparisons of the reviewed methods on popular datasets are summarized and discussed. Finally, the challenges involved, applications, and future research directions are concluded. We also provide a regularly updated project page: \url{https://github.com/zczcwh/DL-HPE}