 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseGaussian: Pose-Driven Novel View Synthesis for Robust 3D Human Reconstruction
Feb 05, 2026We propose PoseGaussian, a pose-guided Gaussian Splatting framework for high-fidelity human novel view synthesis. Human body pose serves a dual purpose in our design: as a structural prior, it is fused with a color encoder to refine depth estimation; as a temporal cue, it is processed by a dedicated pose encoder to enhance temporal consistency across frames. These components are integrated into a fully differentiable, end-to-end trainable pipeline. Unlike prior works that use pose only as a condition or for warping, PoseGaussian embeds pose signals into both geometric and temporal stages to improve robustness and generalization. It is specifically designed to address challenges inherent in dynamic human scenes, such as articulated motion and severe self-occlusion. Notably, our framework achieves real-time rendering at 100 FPS, maintaining the efficiency of standard Gaussian Splatting pipelines. We validate our approach on ZJU-MoCap, THuman2.0, and in-house datasets, demonstrating state-of-the-art performance in perceptual quality and structural accuracy (PSNR 30.86, SSIM 0.979, LPIPS 0.028).
Enhanced 3D Human Pose Estimation from Videos by using Attention-Based Neural Network with Dilated Convolutions
Mar 04, 2021
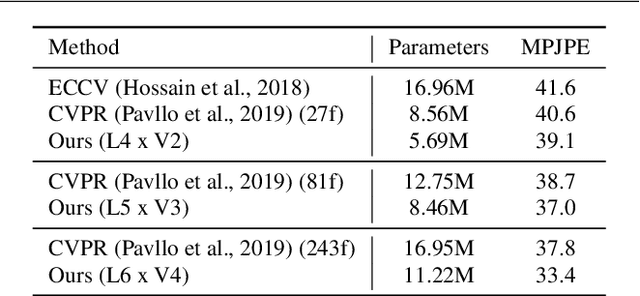
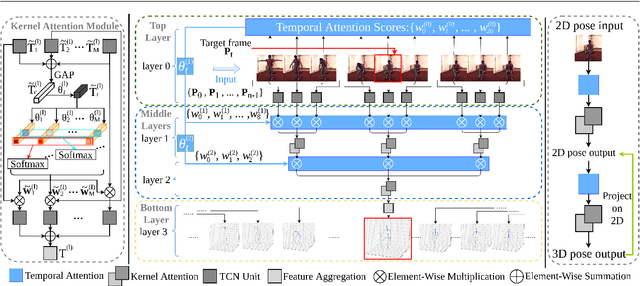
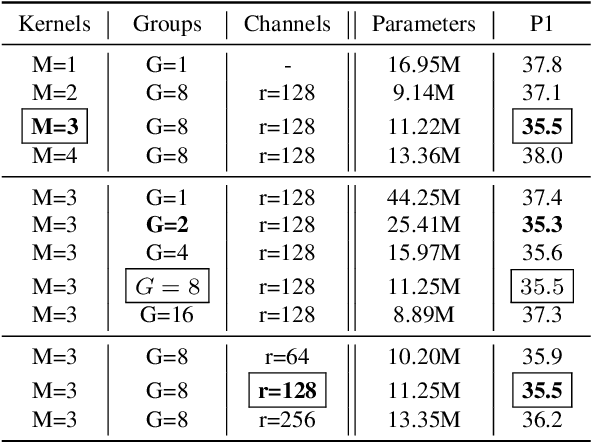
The attention mechanism provides a sequential prediction framework for learning spatial models with enhanced implicit temporal consistency. In this work, we show a systematic design (from 2D to 3D) for how conventional networks and other forms of constraints can be incorporated into the attention framework for learning long-range dependencies for the task of pose estimation. The contribution of this paper is to provide a systematic approach for designing and training of attention-based models for the end-to-end pose estimation, with the flexibility and scalability of arbitrary video sequences as input. We achieve this by adapting temporal receptive field via a multi-scale structure of dilated convolutions. Besides, the proposed architecture can be easily adapted to a causal model enabling real-time performance. Any off-the-shelf 2D pose estimation systems, e.g. Mocap libraries, can be easily integrated in an ad-hoc fashion. Our method achieves the state-of-the-art performance and outperforms existing methods by reducing the mean per joint position error to 33.4 mm on Human3.6M dataset.
Deep Learning-Based Human Pose Estimation: A Survey
Jan 02, 2021
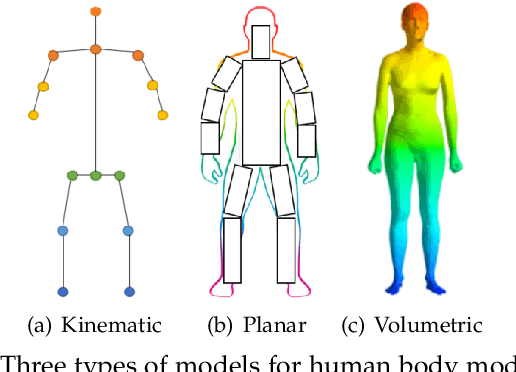
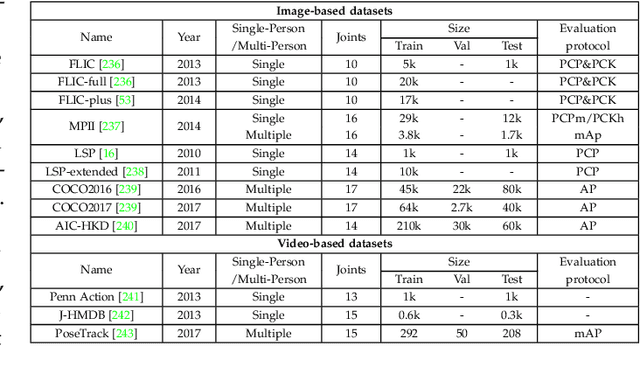
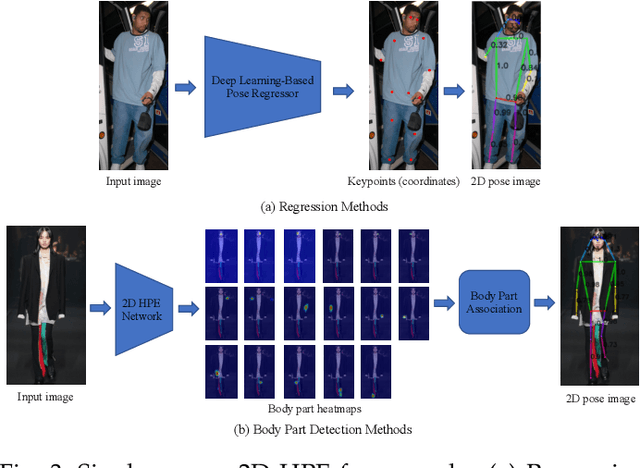
Human pose estimation aims to locate the human body parts and build human body representation (e.g., body skeleton) from input data such as images and videos. It has drawn increasing attention during the past decade and has been utilized in a wide range of applications including human-computer interaction, motion analysis, augmented reality, and virtual reality. Although the recently developed deep learning-based solutions have achieved high performance in human pose estimation, there still remain challenges due to insufficient training data, depth ambiguities, and occlusion. The goal of this survey paper is to provide a comprehensive review of recent deep learning-based solutions for both 2D and 3D pose estimation via a systematic analysis and comparison of these solutions based on their input data and inference procedures. More than 240 research papers since 2014 are covered in this survey. Furthermore, 2D and 3D human pose estimation datasets and evaluation metrics are included. Quantitative performance comparisons of the reviewed methods on popular datasets are summarized and discussed. Finally, the challenges involved, applications, and future research directions are concluded. We also provide a regularly updated project page: \url{https://github.com/zczcwh/DL-HPE}
An Immersive Telepresence System using RGB-D Sensors and Head Mounted Display
Nov 21, 2015
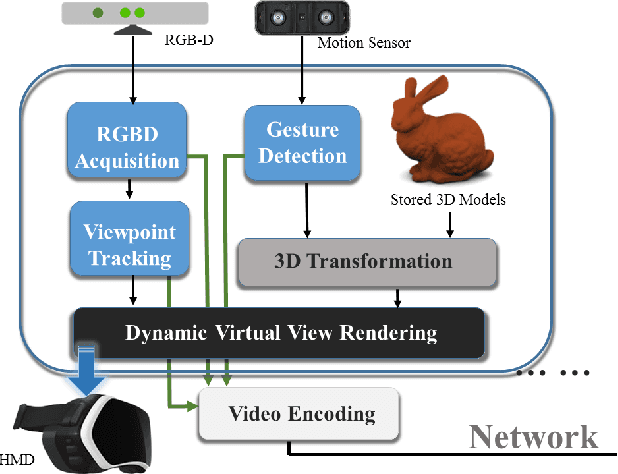


We present a tele-immersive system that enables people to interact with each other in a virtual world using body gestures in addition to verbal communication. Beyond the obvious applications, including general online conversations and gaming, we hypothesize that our proposed system would be particularly beneficial to education by offering rich visual contents and interactivity. One distinct feature is the integration of egocentric pose recognition that allows participants to use their gestures to demonstrate and manipulate virtual objects simultaneously. This functionality enables the instructor to ef- fectively and efficiently explain and illustrate complex concepts or sophisticated problems in an intuitive manner. The highly interactive and flexible environment can capture and sustain more student attention than the traditional classroom setting and, thus, delivers a compelling experience to the students. Our main focus here is to investigate possible solutions for the system design and implementation and devise strategies for fast, efficient computation suitable for visual data processing and network transmission. We describe the technique and experiments in details and provide quantitative performance results, demonstrating our system can be run comfortably and reliably for different application scenarios. Our preliminary results are promising and demonstrate the potential for more compelling directions in cyberlearning.
Automatic Objects Removal for Scene Completion
Jan 23, 2015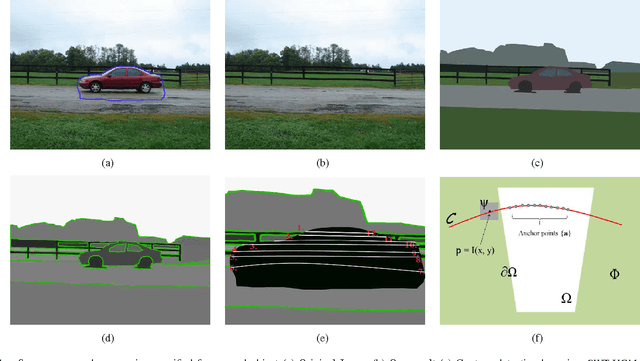

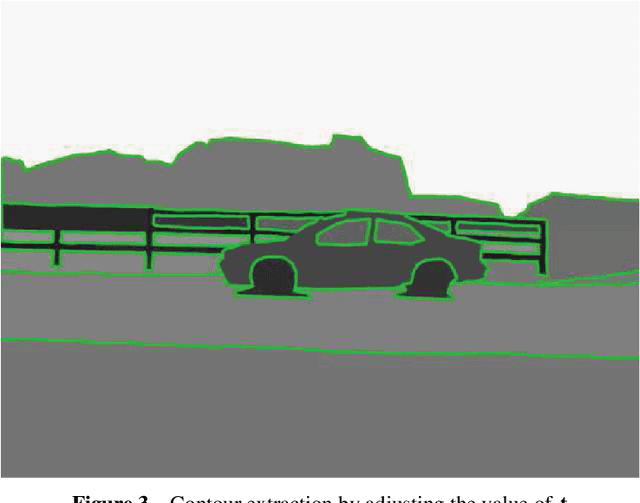
With the explosive growth of web-based cameras and mobile devices, billions of photographs are uploaded to the internet. We can trivially collect a huge number of photo streams for various goals, such as 3D scene reconstruction and other big data applications. However, this is not an easy task due to the fact the retrieved photos are neither aligned nor calibrated. Furthermore, with the occlusion of unexpected foreground objects like people, vehicles, it is even more challenging to find feature correspondences and reconstruct realistic scenes. In this paper, we propose a structure based image completion algorithm for object removal that produces visually plausible content with consistent structure and scene texture. We use an edge matching technique to infer the potential structure of the unknown region. Driven by the estimated structure, texture synthesis is performed automatically along the estimated curves. We evaluate the proposed method on different types of images: from highly structured indoor environment to the natural scenes. Our experimental results demonstrate satisfactory performance that can be potentially used for subsequent big data processing: 3D scene reconstruction and location recognition.
Structure Preserving Large Imagery Reconstruction
Sep 13, 2014
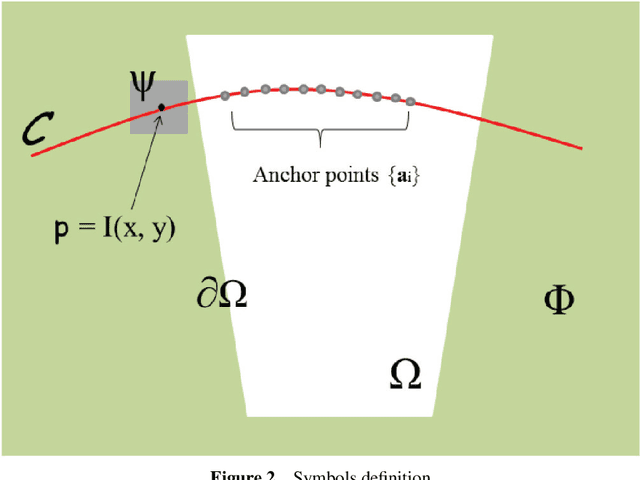

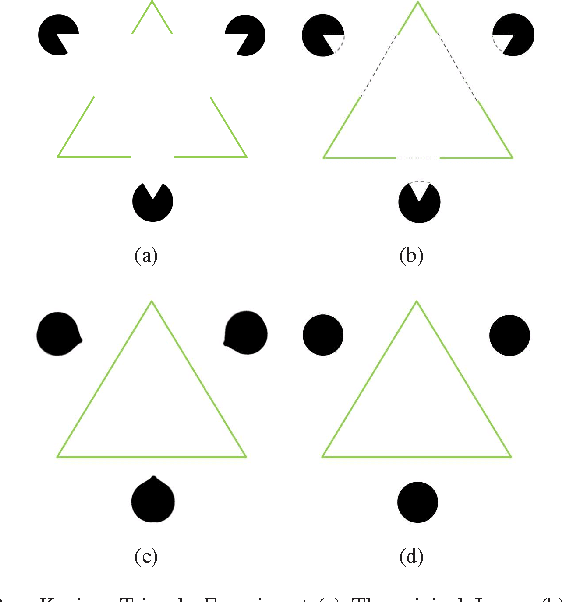
With the explosive growth of web-based cameras and mobile devices, billions of photographs are uploaded to the internet. We can trivially collect a huge number of photo streams for various goals, such as image clustering, 3D scene reconstruction, and other big data applications. However, such tasks are not easy due to the fact the retrieved photos can have large variations in their view perspectives, resolutions, lighting, noises, and distortions. Fur-thermore, with the occlusion of unexpected objects like people, vehicles, it is even more challenging to find feature correspondences and reconstruct re-alistic scenes. In this paper, we propose a structure-based image completion algorithm for object removal that produces visually plausible content with consistent structure and scene texture. We use an edge matching technique to infer the potential structure of the unknown region. Driven by the estimated structure, texture synthesis is performed automatically along the estimated curves. We evaluate the proposed method on different types of images: from highly structured indoor environment to natural scenes. Our experimental results demonstrate satisfactory performance that can be potentially used for subsequent big data processing, such as image localization, object retrieval, and scene reconstruction. Our experiments show that this approach achieves favorable results that outperform existing state-of-the-art techniques.