 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Personalization of Amplification in Hearing Aids via Multi-band Bayesian Machine Learning
Jun 13, 2024



Personalization of the amplification function of hearing aids has been shown to be of benefit to hearing aid users in previous studies. Several machine learning-based personalization approaches have been introduced in the literature. This paper presents a machine learning personalization approach with the advantage of being efficient in its training based on paired comparisons which makes it practical and field deployable. The training efficiency of this approach is the result of treating frequency bands independent of one another and by simultaneously carrying out Bayesian machine learning in each band across all of the frequency bands. Simulation results indicate that this approach leads to an estimated hearing preference function close to the true hearing preference function in fewer number of paired comparisons relative to the previous machine learning approaches. In addition, a clinical experiment conducted on eight subjects with hearing impairment indicate that this training efficient personalization approach provides personalized gain settings which are on average six times more preferred over the standard prescriptive gain settings.
Probabilistic Neural Network to Quantify Uncertainty of Wind Power Estimation
Jun 04, 2021
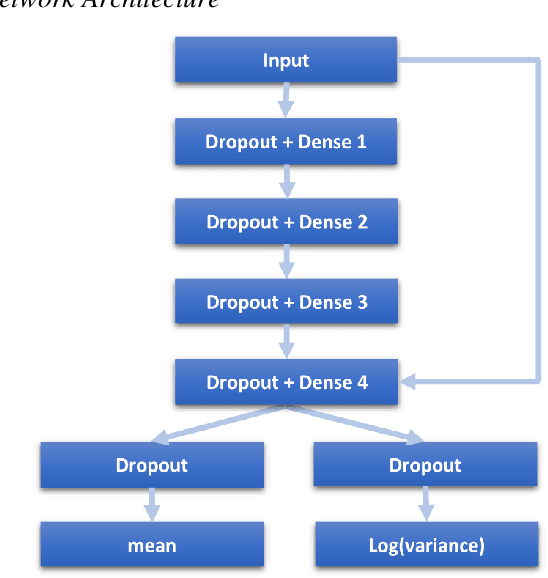
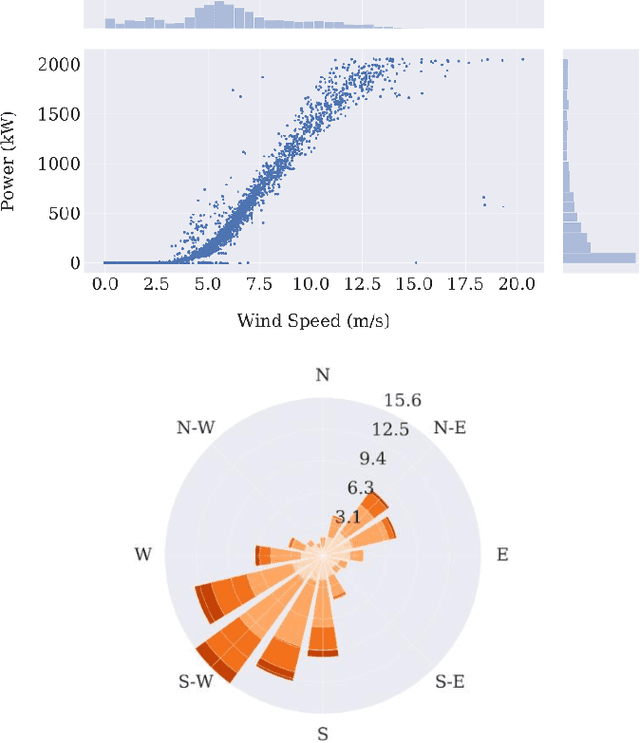
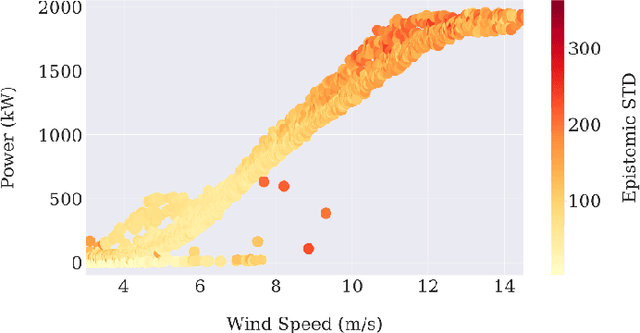
Each year a growing number of wind farms are being added to power grids to generate electricity. The power curve of a wind turbine, which exhibits the relationship between generated power and wind speed, plays a major role in assessing the performance of a wind farm. Neural networks have been used for power curve estimation. However, they do not produce a confidence measure for their output, unless computationally prohibitive Bayesian methods are used. In this paper, a probabilistic neural network with Monte Carlo dropout is considered to quantify the model (epistemic) uncertainty of the power curve estimation. This approach offers a minimal increase in computational complexity over deterministic approaches. Furthermore, by incorporating a probabilistic loss function, the noise or aleatoric uncertainty in the data is estimated. The developed network captures both model and noise uncertainty which is found to be useful tools in assessing performance. Also, the developed network is compared with existing ones across a public domain dataset showing superior performance in terms of prediction accuracy.
Multitasking Deep Learning Model for Detection of Five Stages of Diabetic Retinopathy
Mar 06, 2021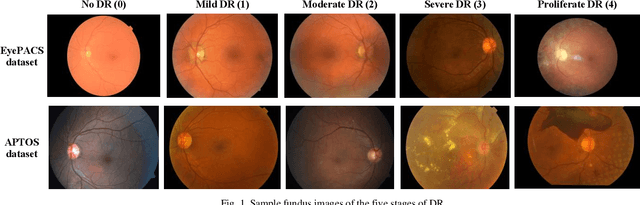
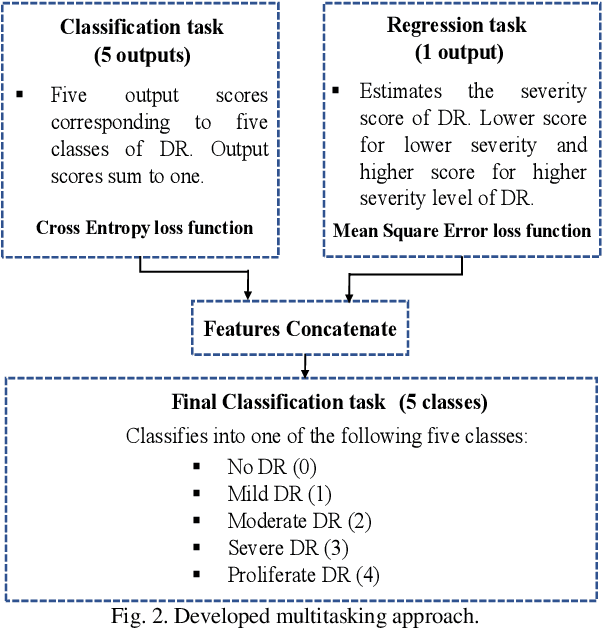
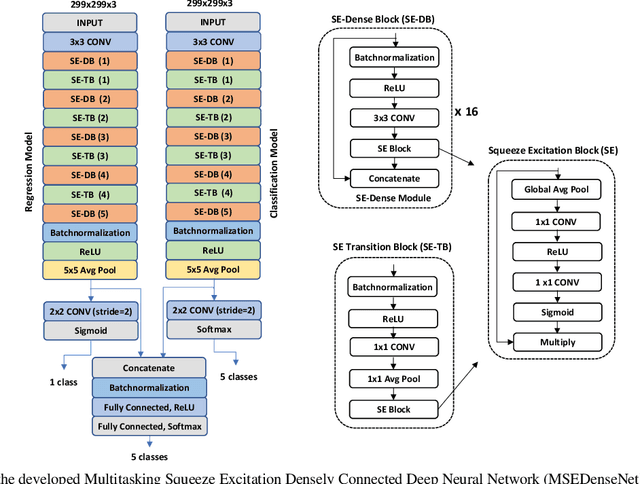
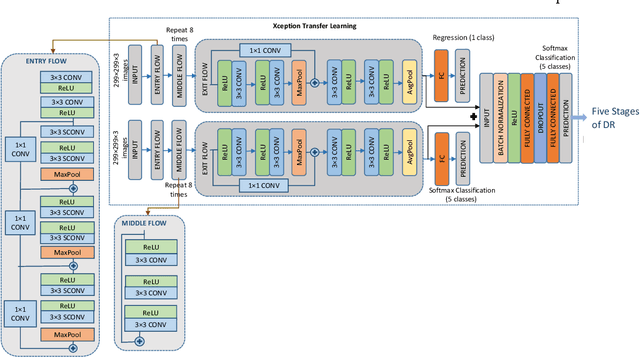
This paper presents a multitask deep learning model to detect all the five stages of diabetic retinopathy (DR) consisting of no DR, mild DR, moderate DR, severe DR, and proliferate DR. This multitask model consists of one classification model and one regression model, each with its own loss function. Noting that a higher severity level normally occurs after a lower severity level, this dependency is taken into consideration by concatenating the classification and regression models. The regression model learns the inter-dependency between the stages and outputs a score corresponding to the severity level of DR generating a higher score for a higher severity level. After training the regression model and the classification model separately, the features extracted by these two models are concatenated and inputted to a multilayer perceptron network to classify the five stages of DR. A modified Squeeze Excitation Densely Connected deep neural network is developed to implement this multitasking approach. The developed multitask model is then used to detect the five stages of DR by examining the two large Kaggle datasets of APTOS and EyePACS. A multitasking transfer learning model based on Xception network is also developed to evaluate the proposed approach by classifying DR into five stages. It is found that the developed model achieves a weighted Kappa score of 0.90 and 0.88 for the APTOS and EyePACS datasets, respectively, higher than any existing methods for detection of the five stages of DR
A Generative Model Method for Unsupervised Multispectral Image Fusion in Remote Sensing
Feb 07, 2021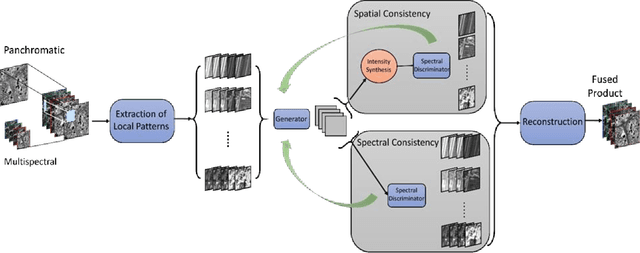



This paper presents a generative model method for multispectral image fusion in remote sensing which is trained without supervision. This method eases the supervision of learning and it also considers a multi-objective loss function to achieve image fusion. The loss function incorporates both spectral and spatial distortions. Two discriminators are designed to minimize the spectral and spatial distortions of the generative output. Extensive experimentations are conducted using three public domain datasets. The comparison results across four reduced-resolution and three full-resolution objective metrics show the superiority of the developed method over several recently developed methods.
Deep Learning-Based Detail Map Estimation for MultiSpectral Image Fusion in Remote Sensing
Feb 07, 2021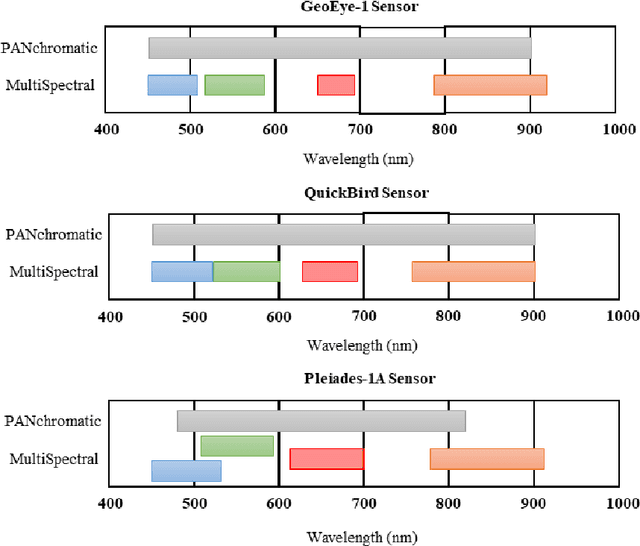
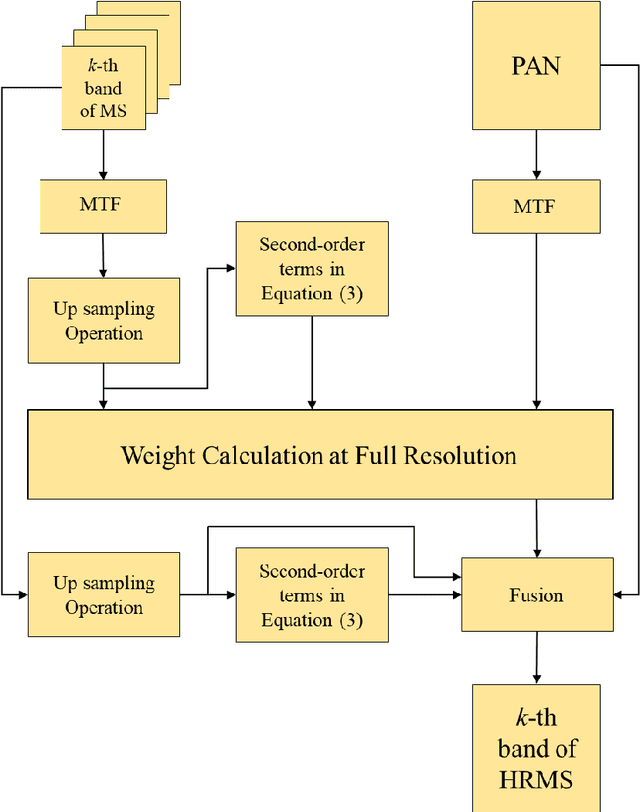
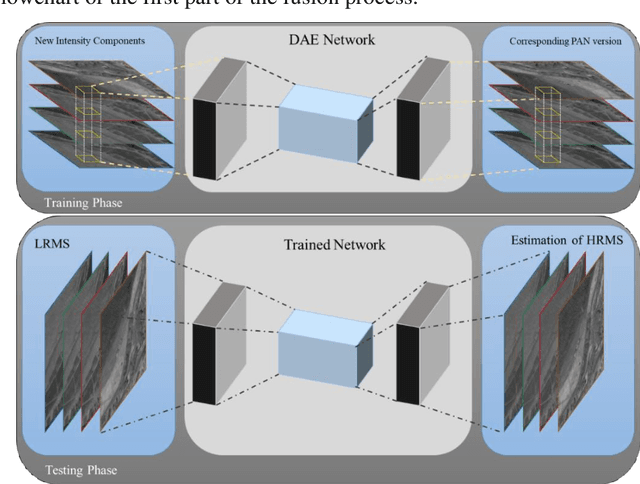

This paper presents a deep learning-based estimation of the intensity component of MultiSpectral bands by considering joint multiplication of the neighbouring spectral bands. This estimation is conducted as part of the component substitution approach for fusion of PANchromatic and MultiSpectral images in remote sensing. After computing the band dependent intensity components, a deep neural network is trained to learn the nonlinear relationship between a PAN image and its nonlinear intensity components. Low Resolution MultiSpectral bands are then fed into the trained network to obtain an estimate of High Resolution MultiSpectral bands. Experiments conducted on three datasets show that the developed deep learning-based estimation approach provides improved performance compared to the existing methods based on three objective metrics.
Deep Learning-Based Human Pose Estimation: A Survey
Jan 02, 2021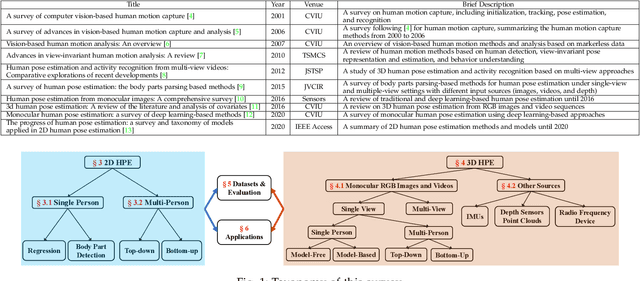
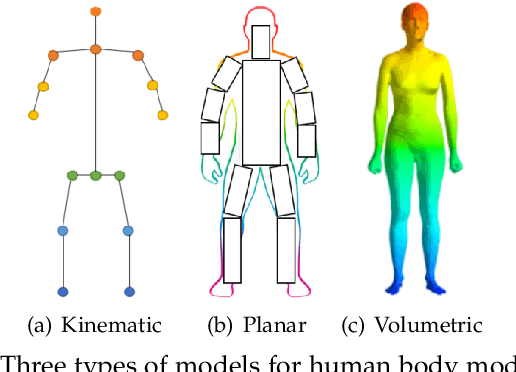
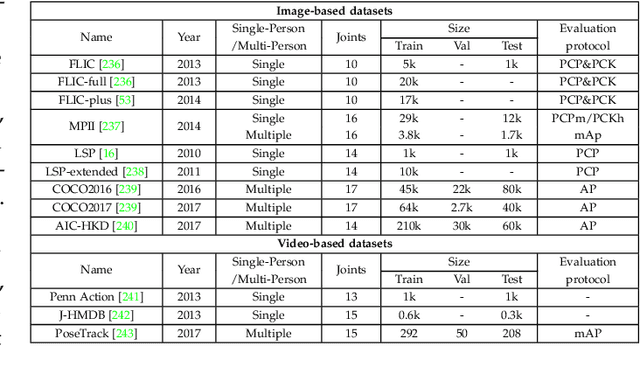
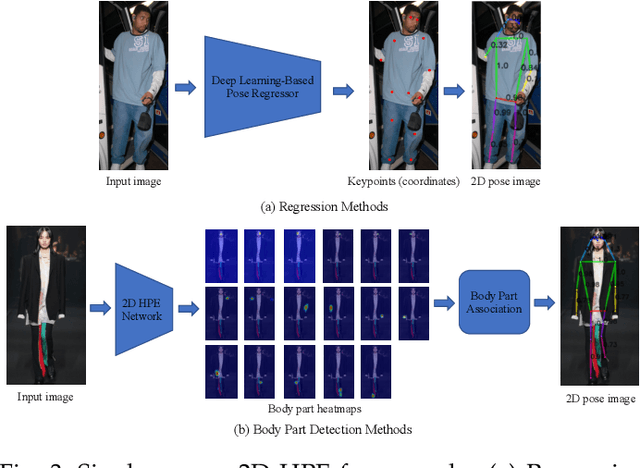
Human pose estimation aims to locate the human body parts and build human body representation (e.g., body skeleton) from input data such as images and videos. It has drawn increasing attention during the past decade and has been utilized in a wide range of applications including human-computer interaction, motion analysis, augmented reality, and virtual reality. Although the recently developed deep learning-based solutions have achieved high performance in human pose estimation, there still remain challenges due to insufficient training data, depth ambiguities, and occlusion. The goal of this survey paper is to provide a comprehensive review of recent deep learning-based solutions for both 2D and 3D pose estimation via a systematic analysis and comparison of these solutions based on their input data and inference procedures. More than 240 research papers since 2014 are covered in this survey. Furthermore, 2D and 3D human pose estimation datasets and evaluation metrics are included. Quantitative performance comparisons of the reviewed methods on popular datasets are summarized and discussed. Finally, the challenges involved, applications, and future research directions are concluded. We also provide a regularly updated project page: \url{https://github.com/zczcwh/DL-HPE}
Vision and Inertial Sensing Fusion for Human Action Recognition : A Review
Aug 02, 2020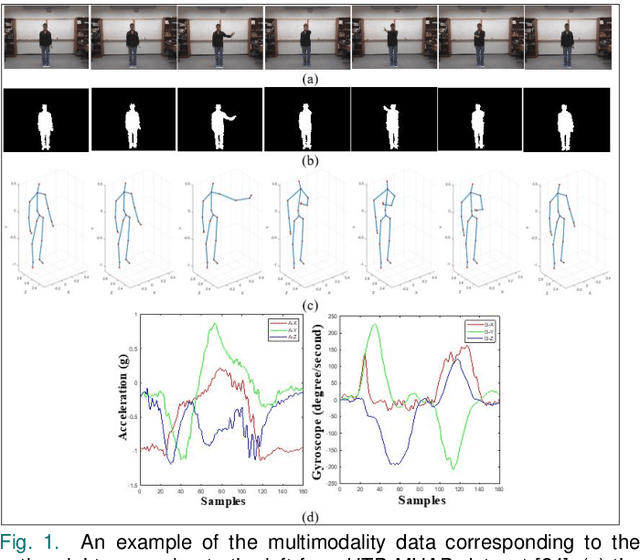
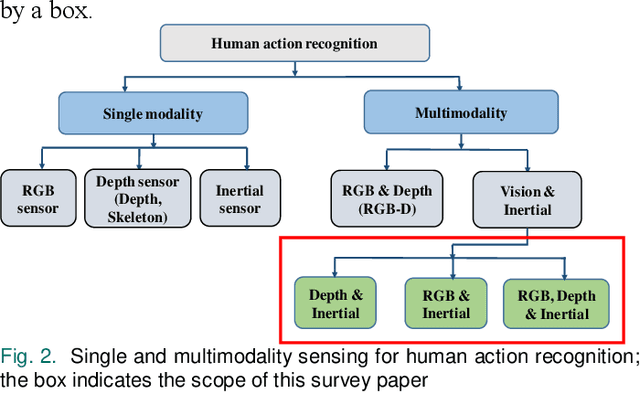
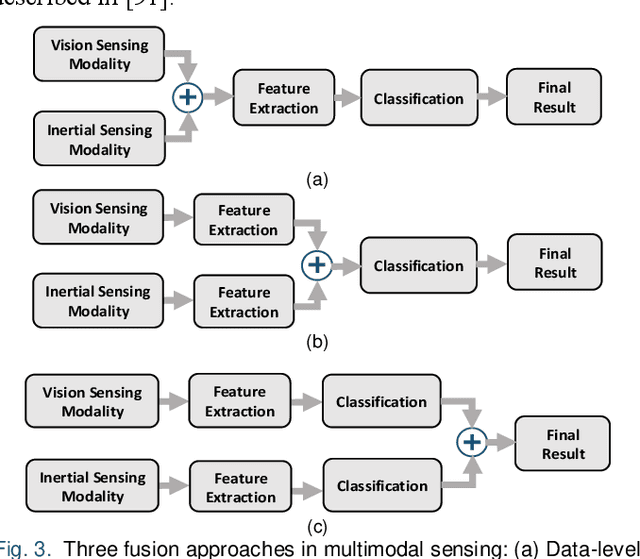
Human action recognition is used in many applications such as video surveillance, human computer interaction, assistive living, and gaming. Many papers have appeared in the literature showing that the fusion of vision and inertial sensing improves recognition accuracies compared to the situations when each sensing modality is used individually. This paper provides a survey of the papers in which vision and inertial sensing are used simultaneously within a fusion framework in order to perform human action recognition. The surveyed papers are categorized in terms of fusion approaches, features, classifiers, as well as multimodality datasets considered. Challenges as well as possible future directions are also stated for deploying the fusion of these two sensing modalities under realistic conditions.
Personalization of Hearing Aid Compression by Human-In-Loop Deep Reinforcement Learning
Jul 01, 2020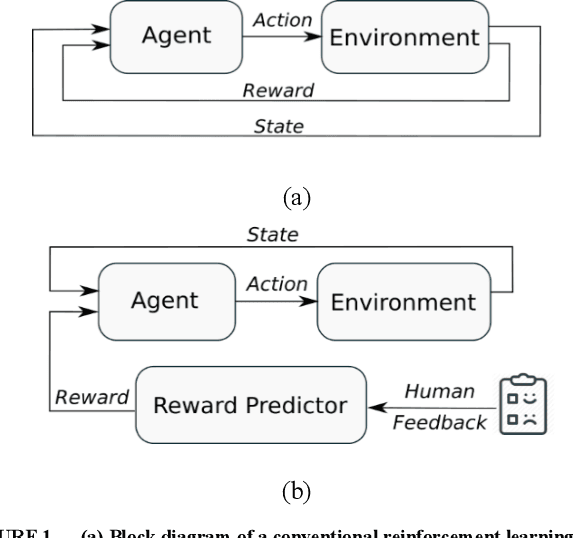
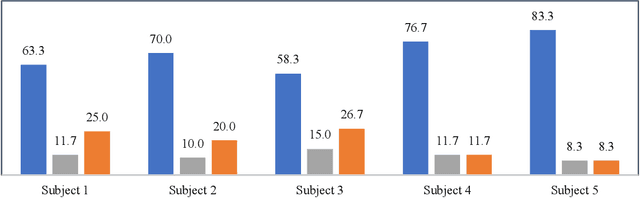

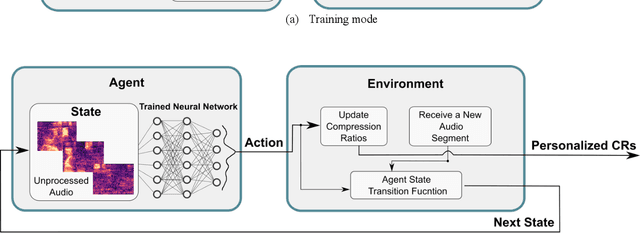
Existing prescriptive compression strategies used in hearing aid fitting are designed based on gain averages from a group of users which are not necessarily optimal for a specific user. Nearly half of hearing aid users prefer settings that differ from the commonly prescribed settings. This paper presents a human-in-loop deep reinforcement learning approach that personalizes hearing aid compression to achieve improved hearing perception. The developed approach is designed to learn a specific user's hearing preferences in order to optimize compression based on the user's feedbacks. Both simulation and subject testing results are reported which demonstrate the effectiveness of the developed personalized compression.
Automatic exposure selection and fusion for high-dynamic-range photography via smartphones
Apr 22, 2020


High-dynamic-range (HDR) photography involves fusing a bracket of images taken at different exposure settings in order to compensate for the low dynamic range of digital cameras such as the ones used in smartphones. In this paper, a method for automatically selecting the exposure settings of such images is introduced based on the camera characteristic function. In addition, a new fusion method is introduced based on an optimization formulation and weighted averaging. Both of these methods are implemented on a smartphone platform as an HDR app to demonstrate the practicality of the introduced methods. Comparison results with several existing methods are presented indicating the effectiveness as well as the computational efficiency of the introduced solution.
Image Segmentation Using Deep Learning: A Survey
Jan 18, 2020
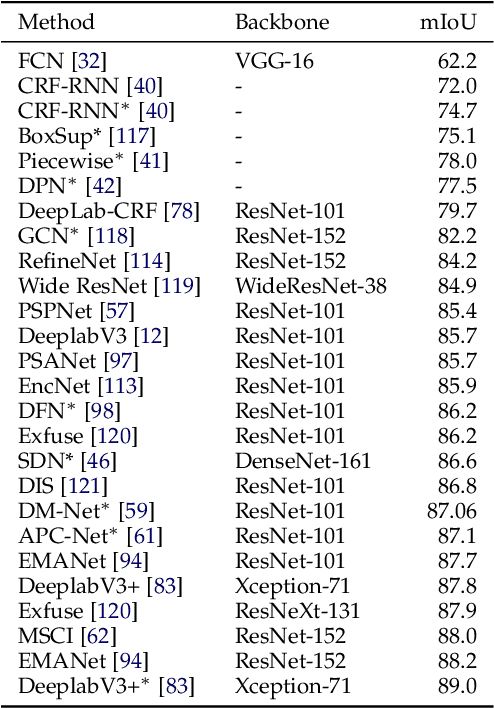
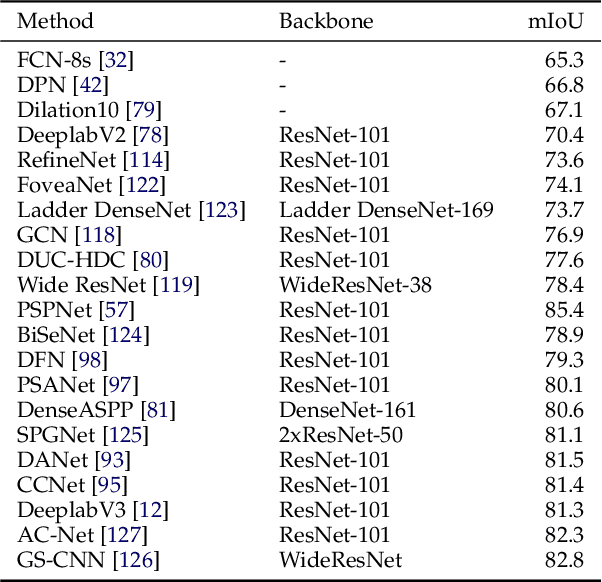
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.