 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaging Human-computer Dialogs: An Application of the Futamura Projections
Nov 13, 2018



We demonstrate an application of the Futamura Projections to human-computer interaction, and particularly to staging human-computer dialogs. Specifically, by providing staging analogs to the classical Futamura Projections, we demonstrate that the Futamura Projections can be applied to the staging of human-computer dialogs in addition to the execution of programs.
Specifying and Staging Mixed-Initiative Dialogs with Program Generation and Transformation
Dec 21, 2015



Specifying and implementing flexible human-computer dialogs, such as those used in kiosks and smart phone apps, is challenging because of the numerous and varied directions in which each user might steer a dialog. The objective of this research is to improve dialog specification and implementation. To do so we enriched a notation based on concepts from programming languages, especially partial evaluation, for specifying a variety of unsolicited reporting, mixed-initiative dialogs in a concise representation that serves as a design for dialog implementation. We also built a dialog mining system that extracts a specification in this notation from requirements. To demonstrate that such a specification provides a design for dialog implementation, we built a system that automatically generates an implementation of the dialog, called a stager, from it. These two components constitute a dialog modeling toolkit that automates dialog specification and implementation. These results provide a proof of concept and demonstrate the study of dialog specification and implementation from a programming languages perspective. The ubiquity of dialogs in domains such as travel, education, and health care combined with the demand for smart phone apps provide a landscape for further investigation of these results.
An Immersive Telepresence System using RGB-D Sensors and Head Mounted Display
Nov 21, 2015
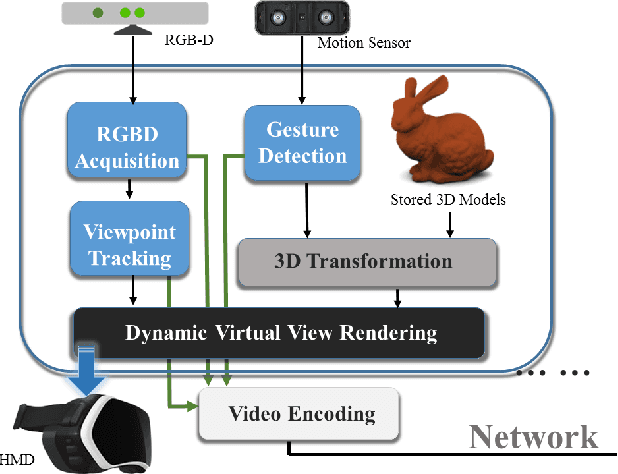


We present a tele-immersive system that enables people to interact with each other in a virtual world using body gestures in addition to verbal communication. Beyond the obvious applications, including general online conversations and gaming, we hypothesize that our proposed system would be particularly beneficial to education by offering rich visual contents and interactivity. One distinct feature is the integration of egocentric pose recognition that allows participants to use their gestures to demonstrate and manipulate virtual objects simultaneously. This functionality enables the instructor to ef- fectively and efficiently explain and illustrate complex concepts or sophisticated problems in an intuitive manner. The highly interactive and flexible environment can capture and sustain more student attention than the traditional classroom setting and, thus, delivers a compelling experience to the students. Our main focus here is to investigate possible solutions for the system design and implementation and devise strategies for fast, efficient computation suitable for visual data processing and network transmission. We describe the technique and experiments in details and provide quantitative performance results, demonstrating our system can be run comfortably and reliably for different application scenarios. Our preliminary results are promising and demonstrate the potential for more compelling directions in cyberlearning.