 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spatial Reasoning in Large Language Models for Metal-Organic Frameworks Structure Prediction
Jan 14, 2026Metal-organic frameworks (MOFs) are porous crystalline materials with broad applications such as carbon capture and drug delivery, yet accurately predicting their 3D structures remains a significant challenge. While Large Language Models (LLMs) have shown promise in generating crystals, their application to MOFs is hindered by MOFs' high atomic complexity. Inspired by the success of block-wise paradigms in deep generative models, we pioneer the use of LLMs in this domain by introducing MOF-LLM, the first LLM framework specifically adapted for block-level MOF structure prediction. To effectively harness LLMs for this modular assembly task, our training paradigm integrates spatial-aware continual pre-training (CPT), structural supervised fine-tuning (SFT), and matching-driven reinforcement learning (RL). By incorporating explicit spatial priors and optimizing structural stability via Soft Adaptive Policy Optimization (SAPO), our approach substantially enhances the spatial reasoning capability of a Qwen-3 8B model for accurate MOF structure prediction. Comprehensive experiments demonstrate that MOF-LLM outperforms state-of-the-art denoising-based and LLM-based methods while exhibiting superior sampling efficiency.
Food-500 Cap: A Fine-Grained Food Caption Benchmark for Evaluating Vision-Language Models
Aug 06, 2023
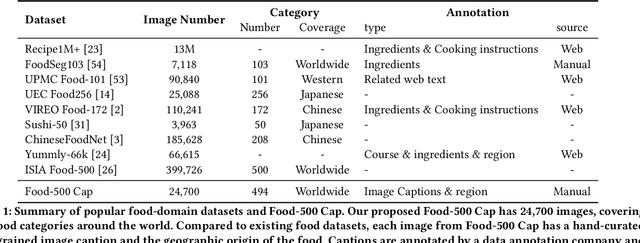
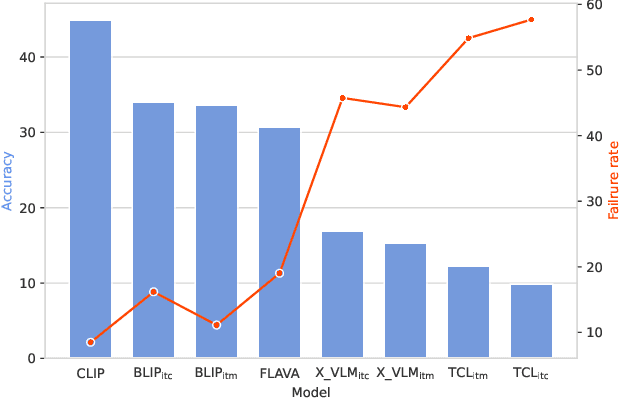
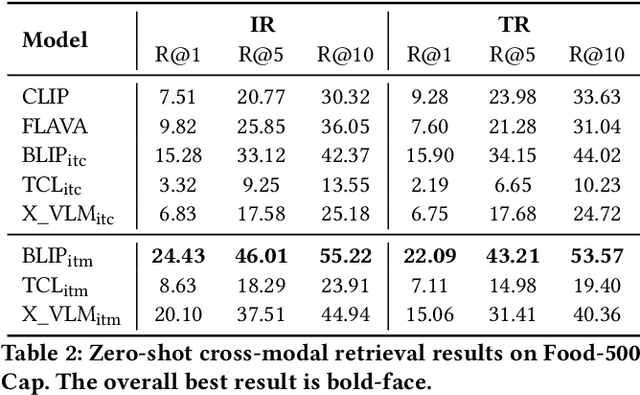
Vision-language models (VLMs) have shown impressive performance in substantial downstream multi-modal tasks. However, only comparing the fine-tuned performance on downstream tasks leads to the poor interpretability of VLMs, which is adverse to their future improvement. Several prior works have identified this issue and used various probing methods under a zero-shot setting to detect VLMs' limitations, but they all examine VLMs using general datasets instead of specialized ones. In practical applications, VLMs are usually applied to specific scenarios, such as e-commerce and news fields, so the generalization of VLMs in specific domains should be given more attention. In this paper, we comprehensively investigate the capabilities of popular VLMs in a specific field, the food domain. To this end, we build a food caption dataset, Food-500 Cap, which contains 24,700 food images with 494 categories. Each image is accompanied by a detailed caption, including fine-grained attributes of food, such as the ingredient, shape, and color. We also provide a culinary culture taxonomy that classifies each food category based on its geographic origin in order to better analyze the performance differences of VLM in different regions. Experiments on our proposed datasets demonstrate that popular VLMs underperform in the food domain compared with their performance in the general domain. Furthermore, our research reveals severe bias in VLMs' ability to handle food items from different geographic regions. We adopt diverse probing methods and evaluate nine VLMs belonging to different architectures to verify the aforementioned observations. We hope that our study will bring researchers' attention to VLM's limitations when applying them to the domain of food or culinary cultures, and spur further investigations to address this issue.
Probing Cross-modal Semantics Alignment Capability from the Textual Perspective
Oct 18, 2022

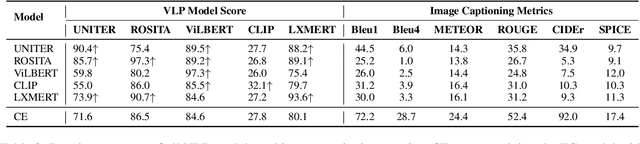
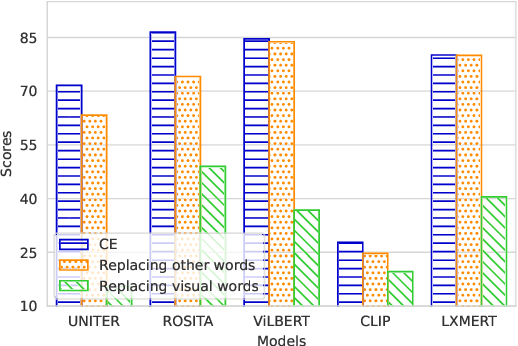
In recent years, vision and language pre-training (VLP) models have advanced the state-of-the-art results in a variety of cross-modal downstream tasks. Aligning cross-modal semantics is claimed to be one of the essential capabilities of VLP models. However, it still remains unclear about the inner working mechanism of alignment in VLP models. In this paper, we propose a new probing method that is based on image captioning to first empirically study the cross-modal semantics alignment of VLP models. Our probing method is built upon the fact that given an image-caption pair, the VLP models will give a score, indicating how well two modalities are aligned; maximizing such scores will generate sentences that VLP models believe are of good alignment. Analyzing these sentences thus will reveal in what way different modalities are aligned and how well these alignments are in VLP models. We apply our probing method to five popular VLP models, including UNITER, ROSITA, ViLBERT, CLIP, and LXMERT, and provide a comprehensive analysis of the generated captions guided by these models. Our results show that VLP models (1) focus more on just aligning objects with visual words, while neglecting global semantics; (2) prefer fixed sentence patterns, thus ignoring more important textual information including fluency and grammar; and (3) deem the captions with more visual words are better aligned with images. These findings indicate that VLP models still have weaknesses in cross-modal semantics alignment and we hope this work will draw researchers' attention to such problems when designing a new VLP model.