 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
An Actor-Critic-Attention Mechanism for Deep Reinforcement Learning in Multi-view Environments
Jul 19, 2019



In reinforcement learning algorithms, leveraging multiple views of the environment can improve the learning of complicated policies. In multi-view environments, due to the fact that the views may frequently suffer from partial observability, their level of importance are often different. In this paper, we propose a deep reinforcement learning method and an attention mechanism in a multi-view environment. Each view can provide various representative information about the environment. Through our attention mechanism, our method generates a single feature representation of environment given its multiple views. It learns a policy to dynamically attend to each view based on its importance in the decision-making process. Through experiments, we show that our method outperforms its state-of-the-art baselines on TORCS racing car simulator and three other complex 3D environments with obstacles. We also provide experimental results to evaluate the performance of our method on noisy conditions and partial observation settings.
Attention-based Deep Reinforcement Learning for Multi-view Environments
May 10, 2019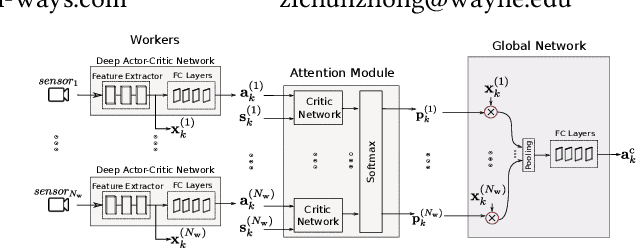
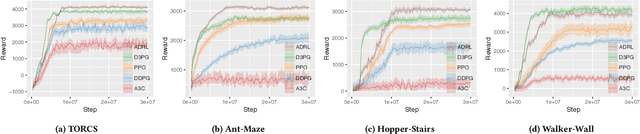
In reinforcement learning algorithms, it is a common practice to account for only a single view of the environment to make the desired decisions; however, utilizing multiple views of the environment can help to promote the learning of complicated policies. Since the views may frequently suffer from partial observability, their provided observation can have different levels of importance. In this paper, we present a novel attention-based deep reinforcement learning method in a multi-view environment in which each view can provide various representative information about the environment. Specifically, our method learns a policy to dynamically attend to views of the environment based on their importance in the decision-making process. We evaluate the performance of our method on TORCS racing car simulator and three other complex 3D environments with obstacles.
Optimizing Taxi Carpool Policies via Reinforcement Learning and Spatio-Temporal Mining
Nov 11, 2018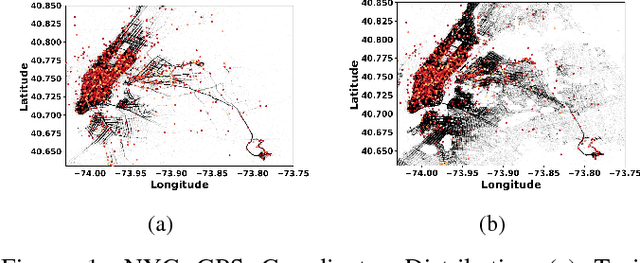
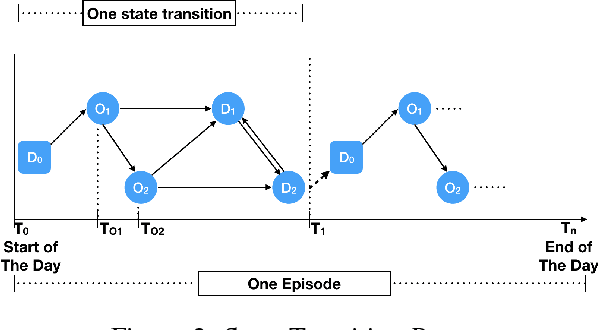

In this paper, we develop a reinforcement learning (RL) based system to learn an effective policy for carpooling that maximizes transportation efficiency so that fewer cars are required to fulfill the given amount of trip demand. For this purpose, first, we develop a deep neural network model, called ST-NN (Spatio-Temporal Neural Network), to predict taxi trip time from the raw GPS trip data. Secondly, we develop a carpooling simulation environment for RL training, with the output of ST-NN and using the NYC taxi trip dataset. In order to maximize transportation efficiency and minimize traffic congestion, we choose the effective distance covered by the driver on a carpool trip as the reward. Therefore, the more effective distance a driver achieves over a trip (i.e. to satisfy more trip demand) the higher the efficiency and the less will be the traffic congestion. We compared the performance of RL learned policy to a fixed policy (which always accepts carpool) as a baseline and obtained promising results that are interpretable and demonstrate the advantage of our RL approach. We also compare the performance of ST-NN to that of state-of-the-art travel time estimation methods and observe that ST-NN significantly improves the prediction performance and is more robust to outliers.
A Unified Neural Network Approach for Estimating Travel Time and Distance for a Taxi Trip
Oct 12, 2017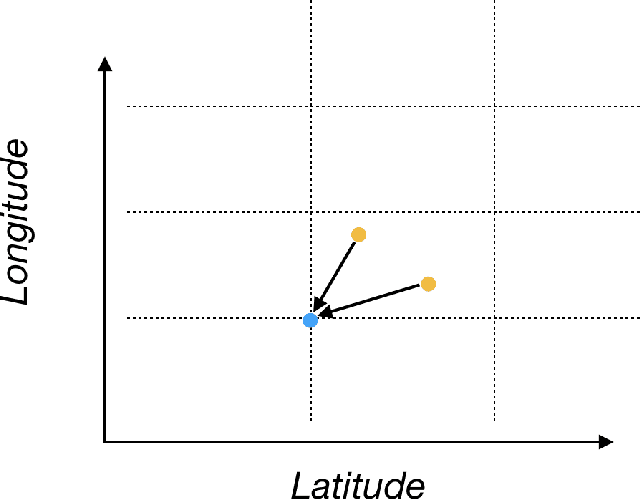
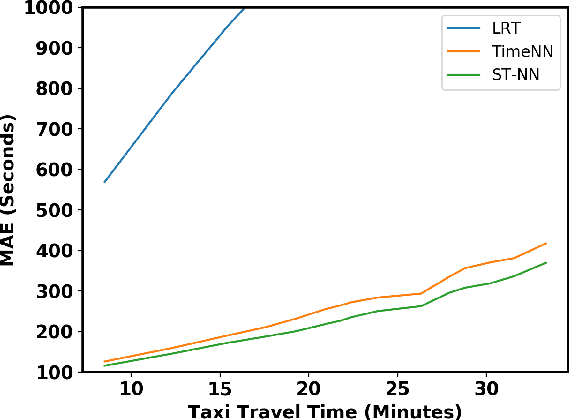
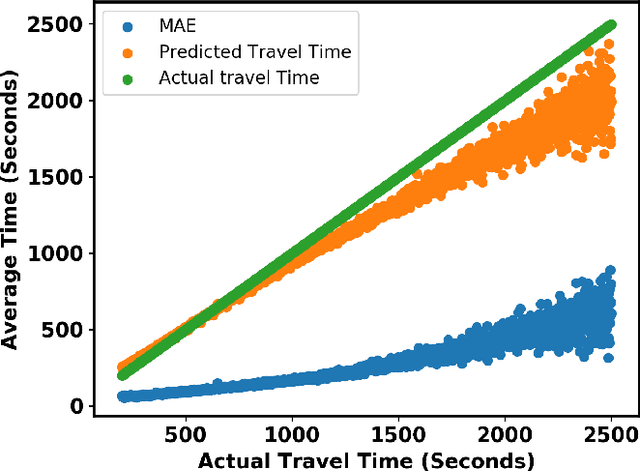
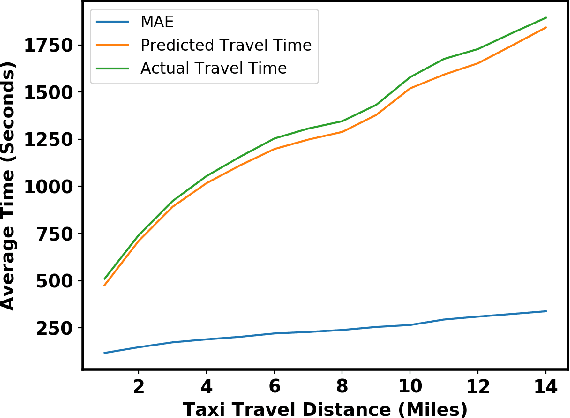
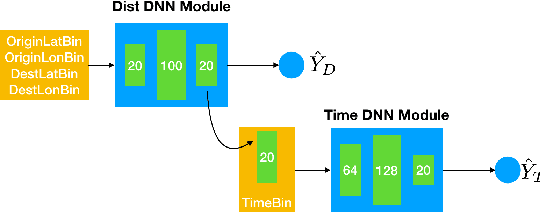
In building intelligent transportation systems such as taxi or rideshare services, accurate prediction of travel time and distance is crucial for customer experience and resource management. Using the NYC taxi dataset, which contains taxi trips data collected from GPS-enabled taxis [23], this paper investigates the use of deep neural networks to jointly predict taxi trip time and distance. We propose a model, called ST-NN (Spatio-Temporal Neural Network), which first predicts the travel distance between an origin and a destination GPS coordinate, then combines this prediction with the time of day to predict the travel time. The beauty of ST-NN is that it uses only the raw trips data without requiring further feature engineering and provides a joint estimate of travel time and distance. We compare the performance of ST-NN to that of state-of-the-art travel time estimation methods, and we observe that the proposed approach generalizes better than state-of-the-art methods. We show that ST-NN approach significantly reduces the mean absolute error for both predicted travel time and distance, about 17% for travel time prediction. We also observe that the proposed approach is more robust to outliers present in the dataset by testing the performance of ST-NN on the datasets with and without outliers.
Large-scale Datasets: Faces with Partial Occlusions and Pose Variations in the Wild
Jun 27, 2017


Face detection methods have relied on face datasets for training. However, existing face datasets tend to be in small scales for face learning in both constrained and unconstrained environments. In this paper, we first introduce our large-scale image datasets, Large-scale Labeled Face (LSLF) and noisy Large-scale Labeled Non-face (LSLNF). Our LSLF dataset consists of a large number of unconstrained multi-view and partially occluded faces. The faces have many variations in color and grayscale, image quality, image resolution, image illumination, image background, image illusion, human face, cartoon face, facial expression, light and severe partial facial occlusion, make up, gender, age, and race. Many of these faces are partially occluded with accessories such as tattoos, hats, glasses, sunglasses, hands, hair, beards, scarves, microphones, or other objects or persons. The LSLF dataset is currently the largest labeled face image dataset in the literature in terms of the number of labeled images and the number of individuals compared to other existing labeled face image datasets. Second, we introduce our CrowedFaces and CrowedNonFaces image datasets. The crowedFaces and CrowedNonFaces datasets include faces and non-faces images from crowed scenes. These datasets essentially aim for researchers to provide a large number of training examples with many variations for large scale face learning and face recognition tasks.
Learning Deep Networks from Noisy Labels with Dropout Regularization
May 09, 2017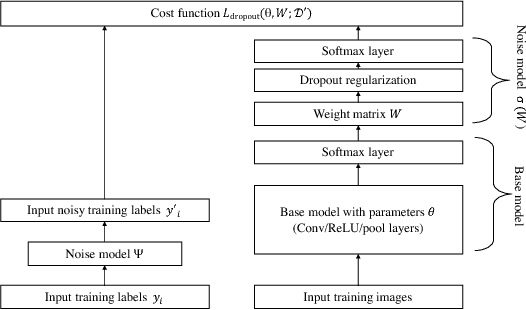


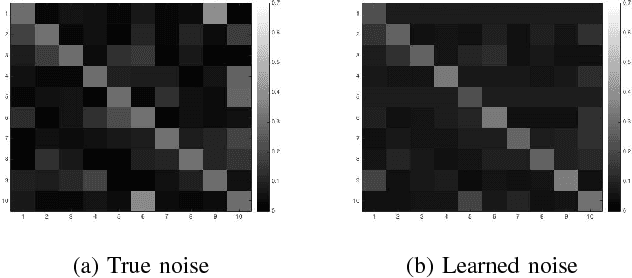
Large datasets often have unreliable labels-such as those obtained from Amazon's Mechanical Turk or social media platforms-and classifiers trained on mislabeled datasets often exhibit poor performance. We present a simple, effective technique for accounting for label noise when training deep neural networks. We augment a standard deep network with a softmax layer that models the label noise statistics. Then, we train the deep network and noise model jointly via end-to-end stochastic gradient descent on the (perhaps mislabeled) dataset. The augmented model is overdetermined, so in order to encourage the learning of a non-trivial noise model, we apply dropout regularization to the weights of the noise model during training. Numerical experiments on noisy versions of the CIFAR-10 and MNIST datasets show that the proposed dropout technique outperforms state-of-the-art methods.