 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Baselines for Multiple Object Rearrangement Planning in Partially Observable Mapped Environments
Jan 24, 2023

Many real-world tasks, from house-cleaning to cooking, can be formulated as multi-object rearrangement problems -- where an agent needs to get specific objects into appropriate goal states. For such problems, we focus on the setting that assumes a pre-specified goal state, availability of perfect manipulation and object recognition capabilities, and a static map of the environment but unknown initial location of objects to be rearranged. Our goal is to enable home-assistive intelligent agents to efficiently plan for rearrangement under such partial observability. This requires efficient trade-offs between exploration of the environment and planning for rearrangement, which is challenging because of long-horizon nature of the problem. To make progress on this problem, we first analyze the effects of various factors such as number of objects and receptacles, agent carrying capacity, environment layouts etc. on exploration and planning for rearrangement using classical methods. We then investigate both monolithic and modular deep reinforcement learning (DRL) methods for planning in our setting. We find that monolithic DRL methods do not succeed at long-horizon planning needed for multi-object rearrangement. Instead, modular greedy approaches surprisingly perform reasonably well and emerge as competitive baselines for planning with partial observability in multi-object rearrangement problems. We also show that our greedy modular agents are empirically optimal when the objects that need to be rearranged are uniformly distributed in the environment -- thereby contributing baselines with strong performance for future work on multi-object rearrangement planning in partially observable settings.
An Actor-Critic-Attention Mechanism for Deep Reinforcement Learning in Multi-view Environments
Jul 19, 2019



In reinforcement learning algorithms, leveraging multiple views of the environment can improve the learning of complicated policies. In multi-view environments, due to the fact that the views may frequently suffer from partial observability, their level of importance are often different. In this paper, we propose a deep reinforcement learning method and an attention mechanism in a multi-view environment. Each view can provide various representative information about the environment. Through our attention mechanism, our method generates a single feature representation of environment given its multiple views. It learns a policy to dynamically attend to each view based on its importance in the decision-making process. Through experiments, we show that our method outperforms its state-of-the-art baselines on TORCS racing car simulator and three other complex 3D environments with obstacles. We also provide experimental results to evaluate the performance of our method on noisy conditions and partial observation settings.
Attention-based Deep Reinforcement Learning for Multi-view Environments
May 10, 2019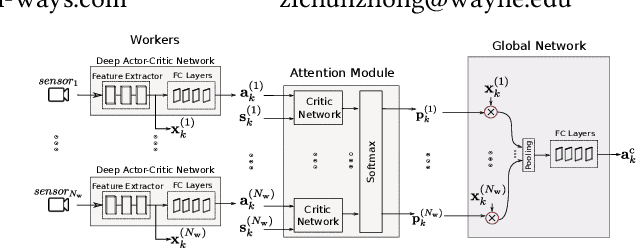
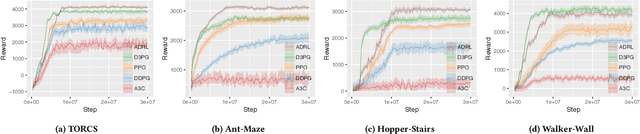
In reinforcement learning algorithms, it is a common practice to account for only a single view of the environment to make the desired decisions; however, utilizing multiple views of the environment can help to promote the learning of complicated policies. Since the views may frequently suffer from partial observability, their provided observation can have different levels of importance. In this paper, we present a novel attention-based deep reinforcement learning method in a multi-view environment in which each view can provide various representative information about the environment. Specifically, our method learns a policy to dynamically attend to views of the environment based on their importance in the decision-making process. We evaluate the performance of our method on TORCS racing car simulator and three other complex 3D environments with obstacles.
Long-term face tracking in the wild using deep learning
May 19, 2018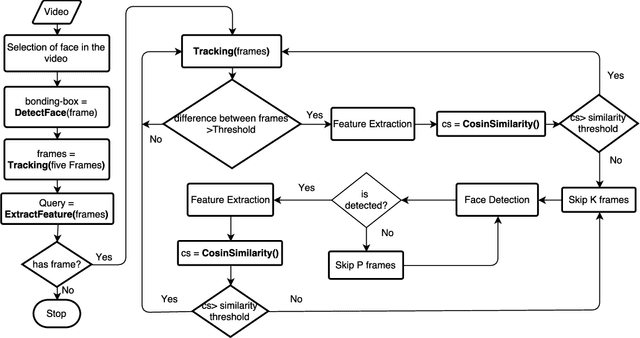
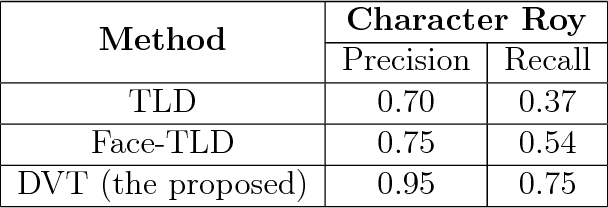


This paper investigates long-term face tracking of a specific person given his/her face image in a single frame as a query in a video stream. Through taking advantage of pre-trained deep learning models on big data, a novel system is developed for accurate video face tracking in the unconstrained environments depicting various people and objects moving in and out of the frame. In the proposed system, we present a detection-verification-tracking method (dubbed as 'DVT') which accomplishes the long-term face tracking task through the collaboration of face detection, face verification, and (short-term) face tracking. An offline trained detector based on cascaded convolutional neural networks localizes all faces appeared in the frames, and an offline trained face verifier based on deep convolutional neural networks and similarity metric learning decides if any face or which face corresponds to the queried person. An online trained tracker follows the face from frame to frame. When validated on a sitcom episode and a TV show, the DVT method outperforms tracking-learning-detection (TLD) and face-TLD in terms of recall and precision. The proposed system is also tested on many other types of videos and shows very promising results.