 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Baselines for Multiple Object Rearrangement Planning in Partially Observable Mapped Environments
Paper and Code
Jan 24, 2023
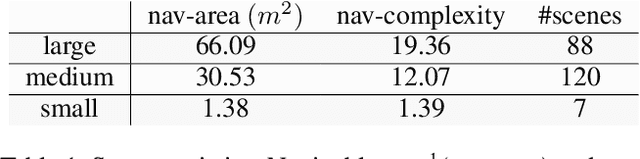

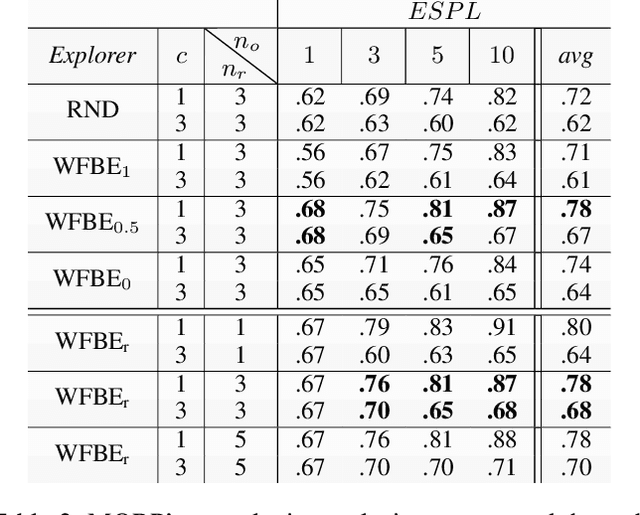
Many real-world tasks, from house-cleaning to cooking, can be formulated as multi-object rearrangement problems -- where an agent needs to get specific objects into appropriate goal states. For such problems, we focus on the setting that assumes a pre-specified goal state, availability of perfect manipulation and object recognition capabilities, and a static map of the environment but unknown initial location of objects to be rearranged. Our goal is to enable home-assistive intelligent agents to efficiently plan for rearrangement under such partial observability. This requires efficient trade-offs between exploration of the environment and planning for rearrangement, which is challenging because of long-horizon nature of the problem. To make progress on this problem, we first analyze the effects of various factors such as number of objects and receptacles, agent carrying capacity, environment layouts etc. on exploration and planning for rearrangement using classical methods. We then investigate both monolithic and modular deep reinforcement learning (DRL) methods for planning in our setting. We find that monolithic DRL methods do not succeed at long-horizon planning needed for multi-object rearrangement. Instead, modular greedy approaches surprisingly perform reasonably well and emerge as competitive baselines for planning with partial observability in multi-object rearrangement problems. We also show that our greedy modular agents are empirically optimal when the objects that need to be rearranged are uniformly distributed in the environment -- thereby contributing baselines with strong performance for future work on multi-object rearrangement planning in partially observable settings.