 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking Explained: A Statistical Phenomenon
Feb 03, 2025



Grokking, or delayed generalization, is an intriguing learning phenomenon where test set loss decreases sharply only after a model's training set loss has converged. This challenges conventional understanding of the training dynamics in deep learning networks. In this paper, we formalize and investigate grokking, highlighting that a key factor in its emergence is a distribution shift between training and test data. We introduce two synthetic datasets specifically designed to analyze grokking. One dataset examines the impact of limited sampling, and the other investigates transfer learning's role in grokking. By inducing distribution shifts through controlled imbalanced sampling of sub-categories, we systematically reproduce the phenomenon, demonstrating that while small-sampling is strongly associated with grokking, it is not its cause. Instead, small-sampling serves as a convenient mechanism for achieving the necessary distribution shift. We also show that when classes form an equivariant map, grokking can be explained by the model's ability to learn from similar classes or sub-categories. Unlike earlier work suggesting that grokking primarily arises from high regularization and sparse data, we demonstrate that it can also occur with dense data and minimal hyper-parameter tuning. Our findings deepen the understanding of grokking and pave the way for developing better stopping criteria in future training processes.
Automated, LLM enabled extraction of synthesis details for reticular materials from scientific literature
Nov 05, 2024



Automated knowledge extraction from scientific literature can potentially accelerate materials discovery. We have investigated an approach for extracting synthesis protocols for reticular materials from scientific literature using large language models (LLMs). To that end, we introduce a Knowledge Extraction Pipeline (KEP) that automatizes LLM-assisted paragraph classification and information extraction. By applying prompt engineering with in-context learning (ICL) to a set of open-source LLMs, we demonstrate that LLMs can retrieve chemical information from PDF documents, without the need for fine-tuning or training and at a reduced risk of hallucination. By comparing the performance of five open-source families of LLMs in both paragraph classification and information extraction tasks, we observe excellent model performance even if only few example paragraphs are included in the ICL prompts. The results show the potential of the KEP approach for reducing human annotations and data curation efforts in automated scientific knowledge extraction.
Graph-based Neural Modules to Inspect Attention-based Architectures: A Position Paper
Oct 13, 2022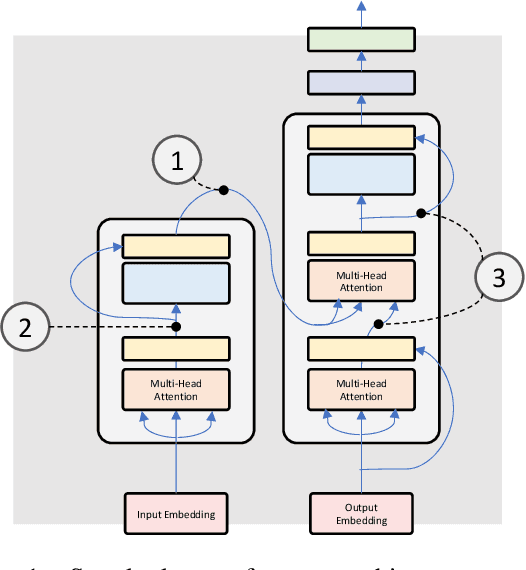
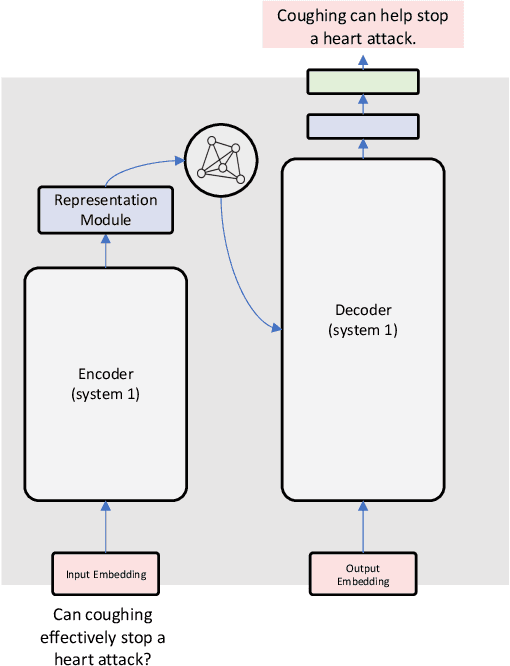
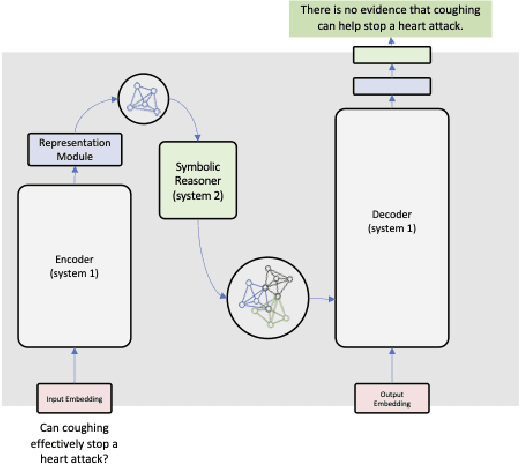
Encoder-decoder architectures are prominent building blocks of state-of-the-art solutions for tasks across multiple fields where deep learning (DL) or foundation models play a key role. Although there is a growing community working on the provision of interpretation for DL models as well as considerable work in the neuro-symbolic community seeking to integrate symbolic representations and DL, many open questions remain around the need for better tools for visualization of the inner workings of DL architectures. In particular, encoder-decoder models offer an exciting opportunity for visualization and editing by humans of the knowledge implicitly represented in model weights. In this work, we explore ways to create an abstraction for segments of the network as a two-way graph-based representation. Changes to this graph structure should be reflected directly in the underlying tensor representations. Such two-way graph representation enables new neuro-symbolic systems by leveraging the pattern recognition capabilities of the encoder-decoder along with symbolic reasoning carried out on the graphs. The approach is expected to produce new ways of interacting with DL models but also to improve performance as a result of the combination of learning and reasoning capabilities.