 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking Explained: A Statistical Phenomenon
Feb 03, 2025



Grokking, or delayed generalization, is an intriguing learning phenomenon where test set loss decreases sharply only after a model's training set loss has converged. This challenges conventional understanding of the training dynamics in deep learning networks. In this paper, we formalize and investigate grokking, highlighting that a key factor in its emergence is a distribution shift between training and test data. We introduce two synthetic datasets specifically designed to analyze grokking. One dataset examines the impact of limited sampling, and the other investigates transfer learning's role in grokking. By inducing distribution shifts through controlled imbalanced sampling of sub-categories, we systematically reproduce the phenomenon, demonstrating that while small-sampling is strongly associated with grokking, it is not its cause. Instead, small-sampling serves as a convenient mechanism for achieving the necessary distribution shift. We also show that when classes form an equivariant map, grokking can be explained by the model's ability to learn from similar classes or sub-categories. Unlike earlier work suggesting that grokking primarily arises from high regularization and sparse data, we demonstrate that it can also occur with dense data and minimal hyper-parameter tuning. Our findings deepen the understanding of grokking and pave the way for developing better stopping criteria in future training processes.
On the Evolution of A.I. and Machine Learning: Towards Measuring and Understanding Impact, Influence, and Leadership at Premier A.I. Conferences
May 26, 2022

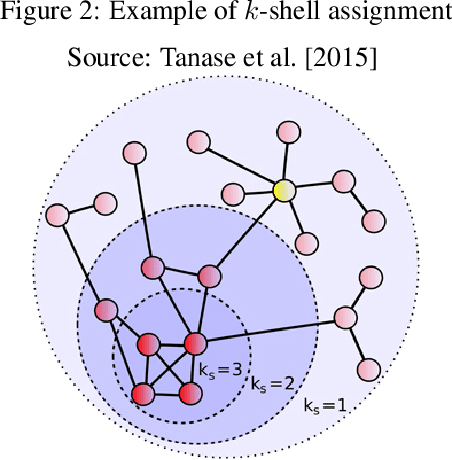
Artificial Intelligence is now recognized as a general-purpose technology with ample impact on human life. In this work, we aim to understand the evolution of AI and Machine learning over the years by analyzing researchers' impact, influence, and leadership over the last decades. This work also intends to shed new light on the history and evolution of AI by exploring the dynamics involved in the field's evolution through the lenses of the papers published on AI conferences since the first International Joint Conference on Artificial Intelligence (IJCAI) in 1969. AI development and evolution have led to increasing research output, reflected in the number of articles published over the last sixty years. We construct comprehensive citation-collaboration and paper-author datasets and compute corresponding centrality measures to carry out our analyses. These analyses allow a better understanding of how AI has reached its current state of affairs in research. Throughout the process, we correlate these datasets with the work of the ACM Turing Award winners and the so-called two AI winters the field has gone through. We also look at self-citation trends and new authors' behaviors. Finally, we present a novel way to infer the country of affiliation of a paper from its organization. Therefore, this work provides a deep analysis of Artificial Intelligence history from information gathered and analyzed from large technical venues datasets and suggests novel insights that can contribute to understanding and measuring AI's evolution.
Measuring Ethics in AI with AI: A Methodology and Dataset Construction
Jul 26, 2021
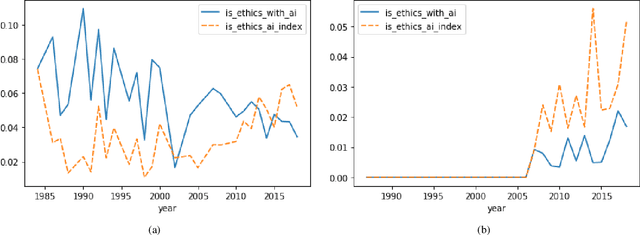
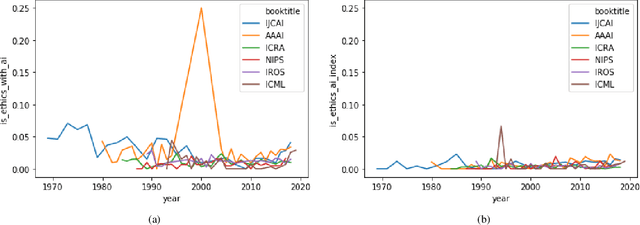
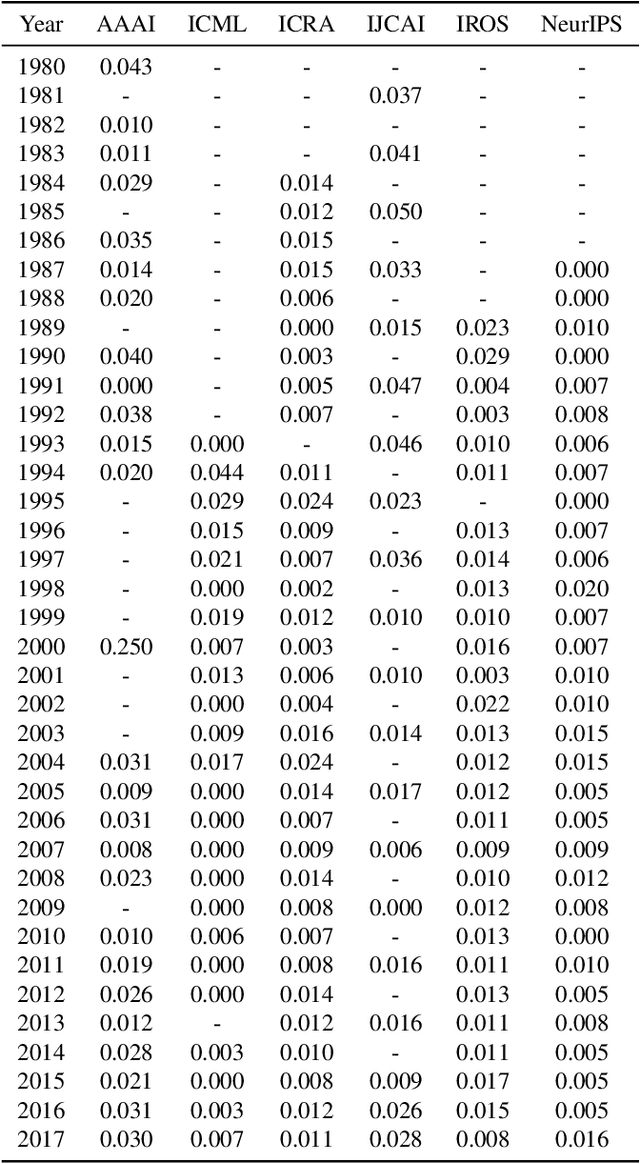
Recently, the use of sound measures and metrics in Artificial Intelligence has become the subject of interest of academia, government, and industry. Efforts towards measuring different phenomena have gained traction in the AI community, as illustrated by the publication of several influential field reports and policy documents. These metrics are designed to help decision takers to inform themselves about the fast-moving and impacting influences of key advances in Artificial Intelligence in general and Machine Learning in particular. In this paper we propose to use such newfound capabilities of AI technologies to augment our AI measuring capabilities. We do so by training a model to classify publications related to ethical issues and concerns. In our methodology we use an expert, manually curated dataset as the training set and then evaluate a large set of research papers. Finally, we highlight the implications of AI metrics, in particular their contribution towards developing trustful and fair AI-based tools and technologies. Keywords: AI Ethics; AI Fairness; AI Measurement. Ethics in Computer Science.
Superpixel Image Classification with Graph Attention Networks
Feb 13, 2020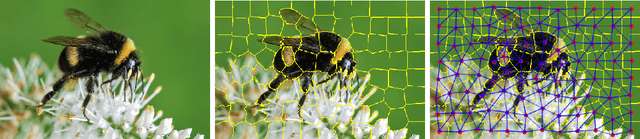
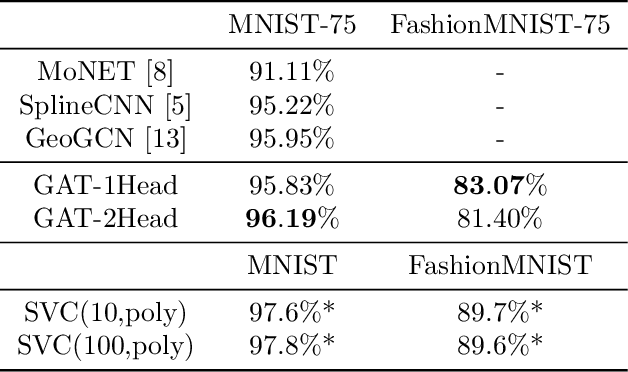
This document reports the use of Graph Attention Networks for classifying oversegmented images, as well as a general procedure for generating oversegmented versions of image-based datasets. The code and learnt models for/from the experiments are available on github. The experiments were ran from June 2019 until December 2019. We obtained better results than the baseline models that uses geometric distance-based attention by using instead self attention, in a more sparsely connected graph network.