 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolution of Self-Attention Over Proto-Objects
Apr 30, 2025Proto-objects - image regions that share common visual properties - offer a promising alternative to traditional attention mechanisms based on rectangular-shaped image patches in neural networks. Although previous work demonstrated that evolving a patch-based hard-attention module alongside a controller network could achieve state-of-the-art performance in visual reinforcement learning tasks, our approach leverages image segmentation to work with higher-level features. By operating on proto-objects rather than fixed patches, we significantly reduce the representational complexity: each image decomposes into fewer proto-objects than regular patches, and each proto-object can be efficiently encoded as a compact feature vector. This enables a substantially smaller self-attention module that processes richer semantic information. Our experiments demonstrate that this proto-object-based approach matches or exceeds the state-of-the-art performance of patch-based implementations with 62% less parameters and 2.6 times less training time.
Python Agent in Ludii
Dec 18, 2024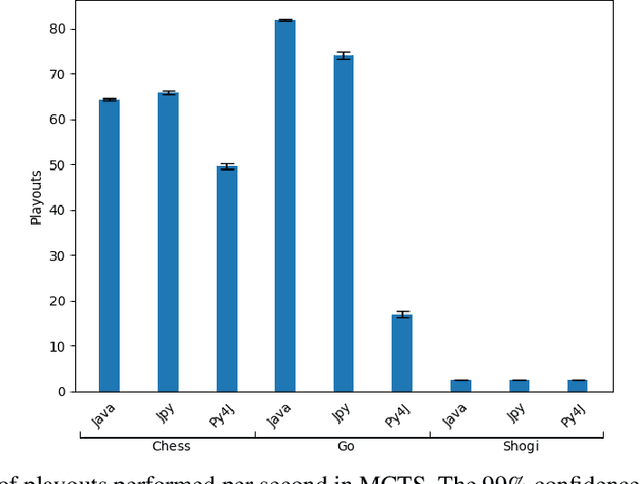

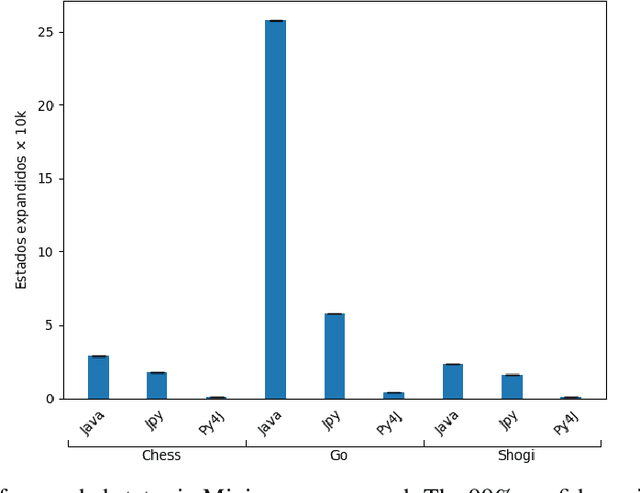

Ludii is a Java general game system with a considerable number of board games, with an API for developing new agents and a game description language to create new games. To improve versatility and ease development, we provide Python interfaces for agent programming. This allows the use of Python modules to implement general game playing agents. As a means of enabling Python for creating Ludii agents, the interfaces are implemented using different Java libraries: jpy and Py4J. The main goal of this work is to determine which version is faster. To do so, we conducted a performance analysis of two different GGP algorithms, Minimax adapted to GGP and MCTS. The analysis was performed across several combinatorial games with varying depth, branching factor, and ply time. For reproducibility, we provide tutorials and repositories. Our analysis includes predictive models using regression, which suggest that jpy is faster than Py4J, however slower than a native Java Ludii agent, as expected.
PReLU: Yet Another Single-Layer Solution to the XOR Problem
Sep 17, 2024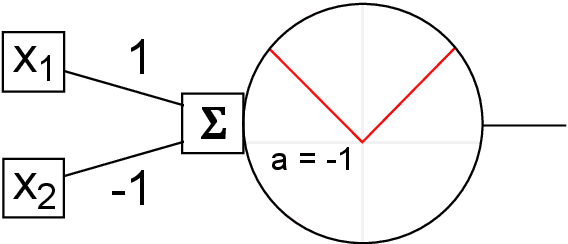
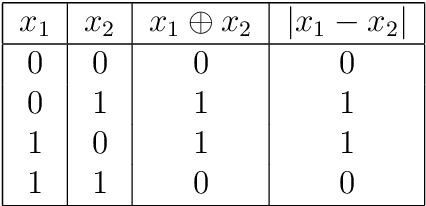
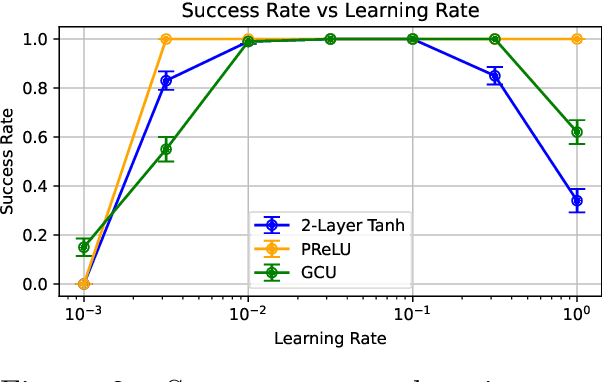
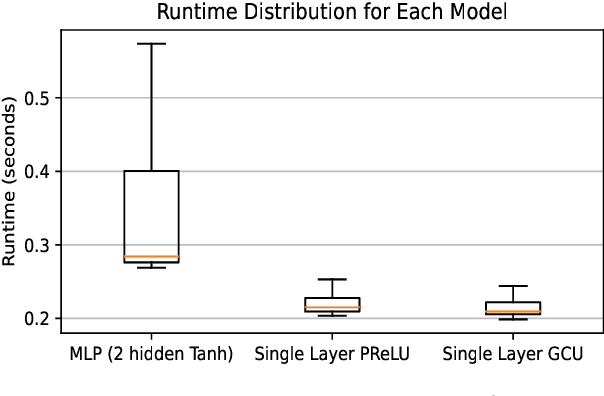
This paper demonstrates that a single-layer neural network using Parametric Rectified Linear Unit (PReLU) activation can solve the XOR problem, a simple fact that has been overlooked so far. We compare this solution to the multi-layer perceptron (MLP) and the Growing Cosine Unit (GCU) activation function and explain why PReLU enables this capability. Our results show that the single-layer PReLU network can achieve 100\% success rate in a wider range of learning rates while using only three learnable parameters.
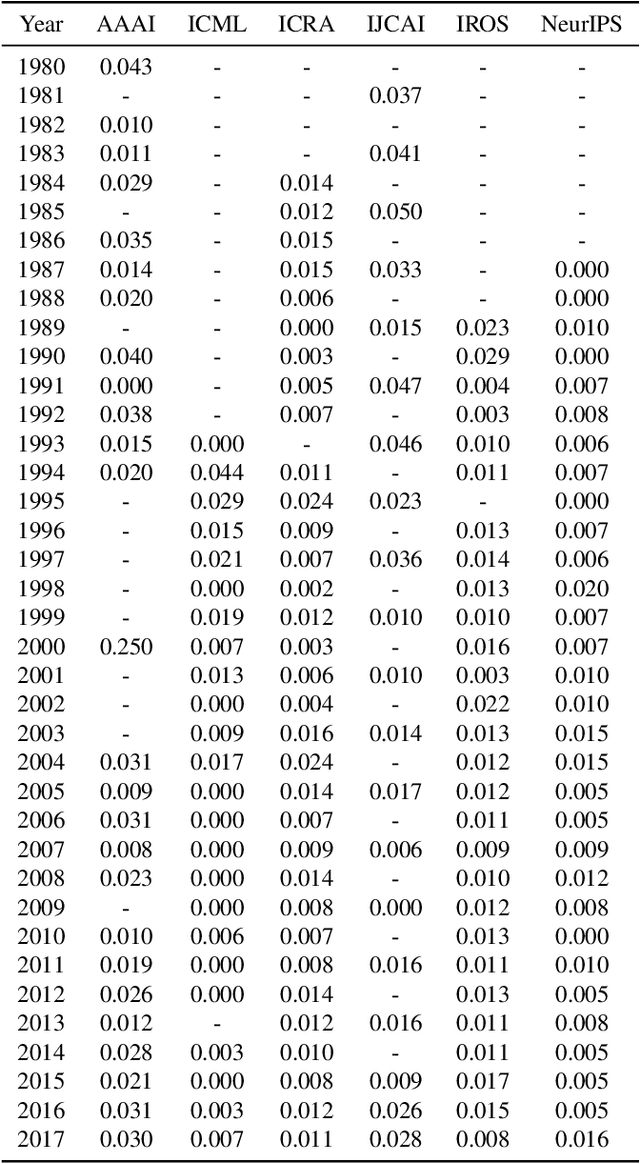
On the Evolution of A.I. and Machine Learning: Towards Measuring and Understanding Impact, Influence, and Leadership at Premier A.I. Conferences
May 26, 2022

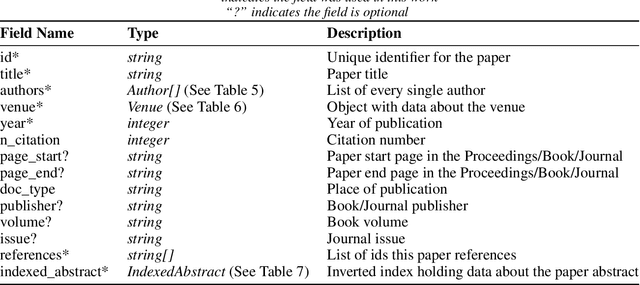
Artificial Intelligence is now recognized as a general-purpose technology with ample impact on human life. In this work, we aim to understand the evolution of AI and Machine learning over the years by analyzing researchers' impact, influence, and leadership over the last decades. This work also intends to shed new light on the history and evolution of AI by exploring the dynamics involved in the field's evolution through the lenses of the papers published on AI conferences since the first International Joint Conference on Artificial Intelligence (IJCAI) in 1969. AI development and evolution have led to increasing research output, reflected in the number of articles published over the last sixty years. We construct comprehensive citation-collaboration and paper-author datasets and compute corresponding centrality measures to carry out our analyses. These analyses allow a better understanding of how AI has reached its current state of affairs in research. Throughout the process, we correlate these datasets with the work of the ACM Turing Award winners and the so-called two AI winters the field has gone through. We also look at self-citation trends and new authors' behaviors. Finally, we present a novel way to infer the country of affiliation of a paper from its organization. Therefore, this work provides a deep analysis of Artificial Intelligence history from information gathered and analyzed from large technical venues datasets and suggests novel insights that can contribute to understanding and measuring AI's evolution.
Measuring Ethics in AI with AI: A Methodology and Dataset Construction
Jul 26, 2021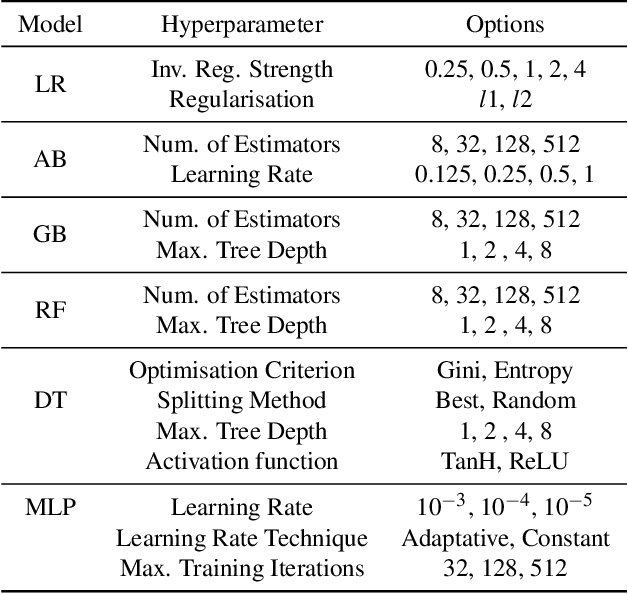
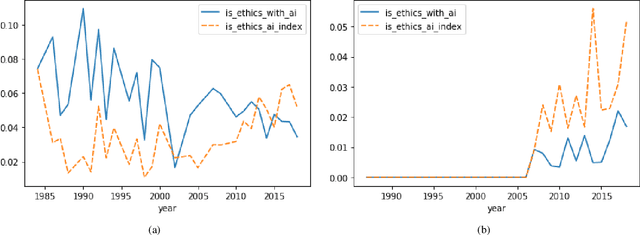
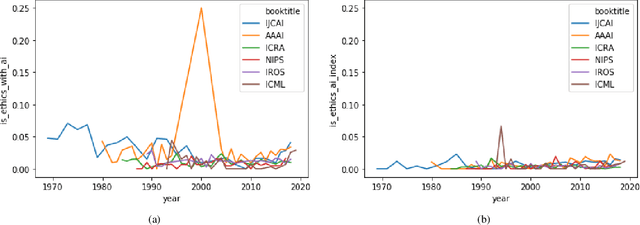
Recently, the use of sound measures and metrics in Artificial Intelligence has become the subject of interest of academia, government, and industry. Efforts towards measuring different phenomena have gained traction in the AI community, as illustrated by the publication of several influential field reports and policy documents. These metrics are designed to help decision takers to inform themselves about the fast-moving and impacting influences of key advances in Artificial Intelligence in general and Machine Learning in particular. In this paper we propose to use such newfound capabilities of AI technologies to augment our AI measuring capabilities. We do so by training a model to classify publications related to ethical issues and concerns. In our methodology we use an expert, manually curated dataset as the training set and then evaluate a large set of research papers. Finally, we highlight the implications of AI metrics, in particular their contribution towards developing trustful and fair AI-based tools and technologies. Keywords: AI Ethics; AI Fairness; AI Measurement. Ethics in Computer Science.
Understanding Boolean Function Learnability on Deep Neural Networks
Sep 13, 2020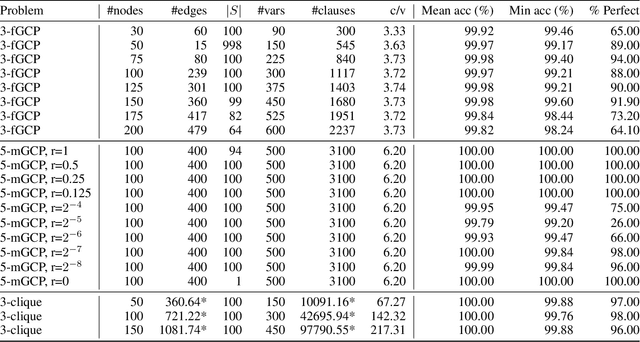
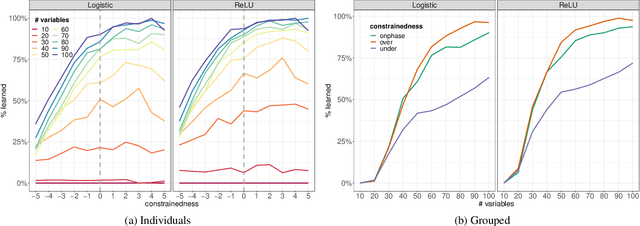
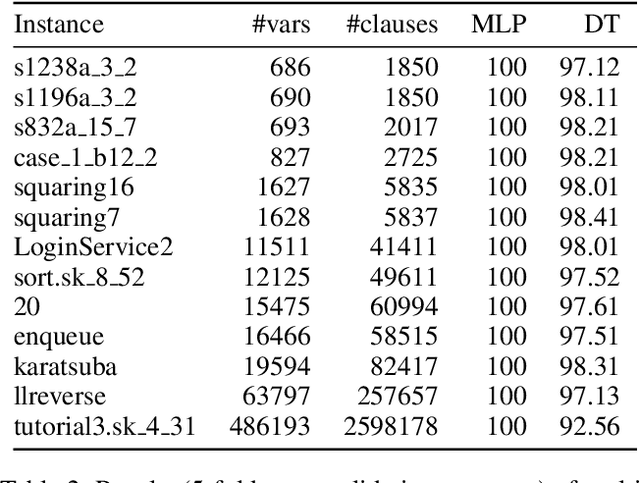
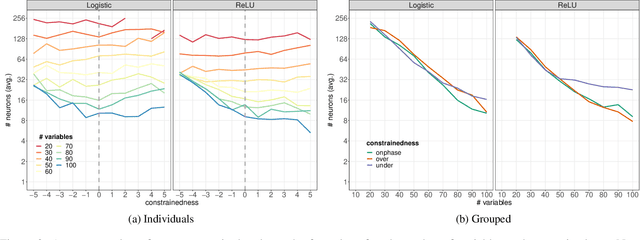
Computational learning theory states that many classes of boolean formulas are learnable in polynomial time. This paper addresses the understudied subject of how, in practice, such formulas can be learned by deep neural networks. Specifically, we analyse boolean formulas associated with the decision version of combinatorial optimisation problems, model sampling benchmarks, and random 3-CNFs with varying degrees of constrainedness. Our extensive experiments indicate that: (i) regardless of the combinatorial optimisation problem, relatively small and shallow neural networks are very good approximators of the associated formulas; (ii) smaller formulas seem harder to learn, possibly due to the fewer positive (satisfying) examples available; and (iii) interestingly, underconstrained 3-CNF formulas are more challenging to learn than overconstrained ones. Source code and relevant datasets are publicly available (https://github.com/machine-reasoning-ufrgs/mlbf).
Superpixel Image Classification with Graph Attention Networks
Feb 13, 2020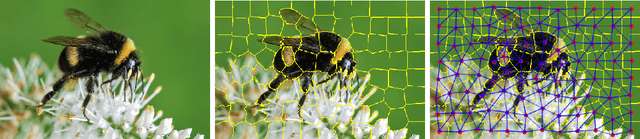
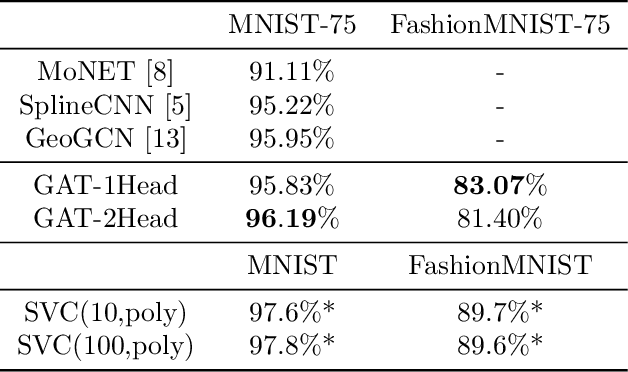
This document reports the use of Graph Attention Networks for classifying oversegmented images, as well as a general procedure for generating oversegmented versions of image-based datasets. The code and learnt models for/from the experiments are available on github. The experiments were ran from June 2019 until December 2019. We obtained better results than the baseline models that uses geometric distance-based attention by using instead self attention, in a more sparsely connected graph network.
Discrete and Continuous Deep Residual Learning Over Graphs
Nov 26, 2019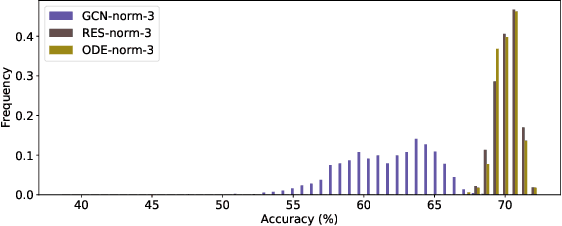
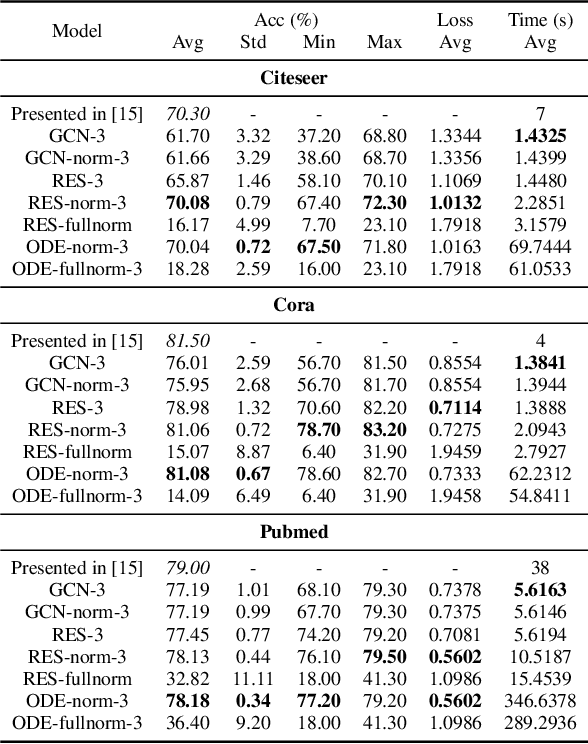
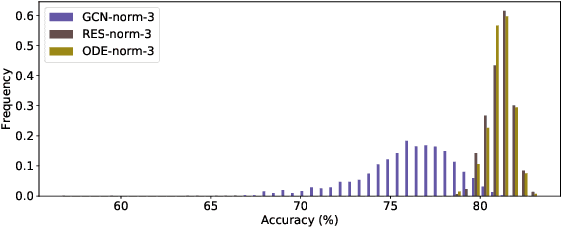
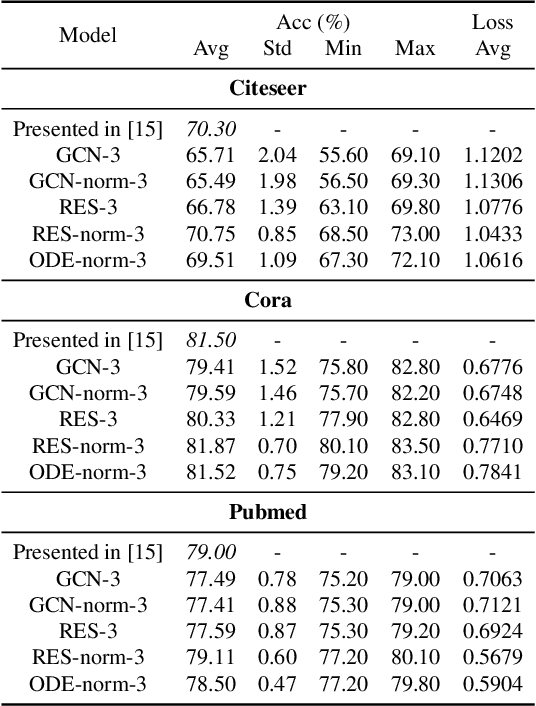
In this paper we propose the use of continuous residual modules for graph kernels in Graph Neural Networks. We show how both discrete and continuous residual layers allow for more robust training, being that continuous residual layers are those which are applied by integrating through an Ordinary Differential Equation (ODE) solver to produce their output. We experimentally show that these residuals achieve better results than the ones with non-residual modules when multiple layers are used, mitigating the low-pass filtering effect of GCN-based models. Finally, we apply and analyse the behaviour of these techniques and give pointers to how this technique can be useful in other domains by allowing more predictable behaviour under dynamic times of computation.