 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn LLM-generated Logic Programs and their Inference Execution Methods
Feb 13, 2025Large Language Models (LLMs) trained on petabytes of data are highly compressed repositories of a significant proportion of the knowledge accumulated and distilled so far. In this paper we study techniques to elicit this knowledge in the form of several classes of logic programs, including propositional Horn clauses, Dual Horn clauses, relational triplets and Definite Clause Grammars. Exposing this knowledge as logic programs enables sound reasoning methods that can verify alignment of LLM outputs to their intended uses and extend their inference capabilities. We study new execution methods for the generated programs, including soft-unification of abducible facts against LLM-generated content stored in a vector database as well as GPU-based acceleration of minimal model computation that supports inference with large LLM-generated programs.
* In Proceedings ICLP 2024, arXiv:2502.08453
Through the Looking Glass, and what Horn Clause Programs Found There
Jul 29, 2024Dual Horn clauses mirror key properties of Horn clauses. This paper explores the ``other side of the looking glass'' to reveal some expected and unexpected symmetries and their practical uses. We revisit Dual Horn clauses as enablers of a form of constructive negation that supports goal-driven forward reasoning and is valid both intuitionistically and classically. In particular, we explore the ability to falsify a counterfactual hypothesis in the context of a background theory expressed as a Dual Horn clause program. With Dual Horn clause programs, by contrast to negation as failure, the variable bindings in their computed answers provide explanations for the reasons why a statement is successfully falsified. Moreover, in the propositional case, by contrast to negation as failure as implemented with stable models semantics in ASP systems, and similarly to Horn clause programs, Dual Horn clause programs have polynomial complexity. After specifying their execution model with a metainterpreter, we devise a compilation scheme from Dual Horn clause programs to Horn clause programs, ensuring their execution with no performance penalty and we design the embedded SymLP language to support combined Horn clause and Dual Horn clause programs. As a (motivating) application, we cast LLM reasoning chains into propositional Horn and Dual Horn clauses that work together to constructively prove and disprove goals and enhance Generative AI with explainability of reasoning chains.
Natlog: Embedding Logic Programming into the Python Deep-Learning Ecosystem
Aug 30, 2023



Driven by expressiveness commonalities of Python and our Python-based embedded logic-based language Natlog, we design high-level interaction patterns between equivalent language constructs and data types on the two sides. By directly connecting generators and backtracking, nested tuples and terms, coroutines and first-class logic engines, reflection and meta-interpretation, we enable logic-based language constructs to access the full power of the Python ecosystem. We show the effectiveness of our design via Natlog apps working as orchestrators for JAX and Pytorch pipelines and as DCG-driven GPT3 and DALL.E prompt generators. Keyphrases: embedding of logic programming in the Python ecosystem, high-level inter-paradigm data exchanges, coroutining with logic engines, logic-based neuro-symbolic computing, logic grammars as prompt-generators for Large Language Models, logic-based neural network configuration and training.
* In Proceedings ICLP 2023, arXiv:2308.14898
Full Automation of Goal-driven LLM Dialog Threads with And-Or Recursors and Refiner Oracles
Jun 24, 2023We automate deep step-by step reasoning in an LLM dialog thread by recursively exploring alternatives (OR-nodes) and expanding details (AND-nodes) up to a given depth. Starting from a single succinct task-specific initiator we steer the automated dialog thread to stay focussed on the task by synthesizing a prompt that summarizes the depth-first steps taken so far. Our algorithm is derived from a simple recursive descent implementation of a Horn Clause interpreter, except that we accommodate our logic engine to fit the natural language reasoning patterns LLMs have been trained on. Semantic similarity to ground-truth facts or oracle advice from another LLM instance is used to restrict the search space and validate the traces of justification steps returned as answers. At the end, the unique minimal model of a generated Horn Clause program collects the results of the reasoning process. As applications, we sketch implementations of consequence predictions, causal explanations, recommendation systems and topic-focussed exploration of scientific literature.
A Gaze into the Internal Logic of Graph Neural Networks, with Logic
Aug 05, 2022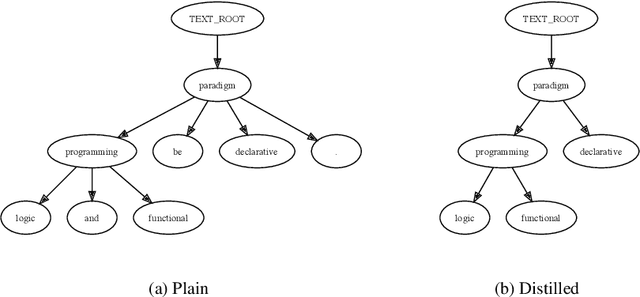

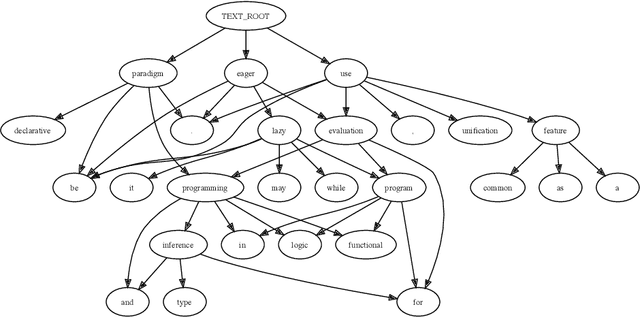

Graph Neural Networks share with Logic Programming several key relational inference mechanisms. The datasets on which they are trained and evaluated can be seen as database facts containing ground terms. This makes possible modeling their inference mechanisms with equivalent logic programs, to better understand not just how they propagate information between the entities involved in the machine learning process but also to infer limits on what can be learned from a given dataset and how well that might generalize to unseen test data. This leads us to the key idea of this paper: modeling with the help of a logic program the information flows involved in learning to infer from the link structure of a graph and the information content of its nodes properties of new nodes, given their known connections to nodes with possibly similar properties. The problem is known as graph node property prediction and our approach will consist in emulating with help of a Prolog program the key information propagation steps of a Graph Neural Network's training and inference stages. We test our a approach on the ogbn-arxiv node property inference benchmark. To infer class labels for nodes representing papers in a citation network, we distill the dependency trees of the text associated to each node into directed acyclic graphs that we encode as ground Prolog terms. Together with the set of their references to other papers, they become facts in a database on which we reason with help of a Prolog program that mimics the information propagation in graph neural networks predicting node properties. In the process, we invent ground term similarity relations that help infer labels in the test set by propagating node properties from similar nodes in the training set and we evaluate their effectiveness in comparison with that of the graph's link structure. Finally, we implement explanation generators that unveil performance upper bounds inherent to the dataset. As a practical outcome, we obtain a logic program, that, when seen as machine learning algorithm, performs close to the state of the art on the node property prediction benchmark.
* In Proceedings ICLP 2022, arXiv:2208.02685
Natlog: a Lightweight Logic Programming Language with a Neuro-symbolic Touch
Sep 17, 2021We introduce Natlog, a lightweight Logic Programming language, sharing Prolog's unification-driven execution model, but with a simplified syntax and semantics. Our proof-of-concept Natlog implementation is tightly embedded in the Python-based deep-learning ecosystem with focus on content-driven indexing of ground term datasets. As an overriding of our symbolic indexing algorithm, the same function can be delegated to a neural network, serving ground facts to Natlog's resolution engine. Our open-source implementation is available as a Python package at https://pypi.org/project/natlog/ .
* In Proceedings ICLP 2021, arXiv:2109.07914
Deriving Theorems in Implicational Linear Logic, Declaratively
Sep 22, 2020The problem we want to solve is how to generate all theorems of a given size in the implicational fragment of propositional intuitionistic linear logic. We start by filtering for linearity the proof terms associated by our Prolog-based theorem prover for Implicational Intuitionistic Logic. This works, but using for each formula a PSPACE-complete algorithm limits it to very small formulas. We take a few walks back and forth over the bridge between proof terms and theorems, provided by the Curry-Howard isomorphism, and derive step-by-step an efficient algorithm requiring a low polynomial effort per generated theorem. The resulting Prolog program runs in O(N) space for terms of size N and generates in a few hours 7,566,084,686 theorems in the implicational fragment of Linear Intuitionistic Logic together with their proof terms in normal form. As applications, we generate datasets for correctness and scalability testing of linear logic theorem provers and training data for neural networks working on theorem proving challenges. The results in the paper, organized as a literate Prolog program, are fully replicable. Keywords: combinatorial generation of provable formulas of a given size, intuitionistic and linear logic theorem provers, theorems of the implicational fragment of propositional linear intuitionistic logic, Curry-Howard isomorphism, efficient generation of linear lambda terms in normal form, Prolog programs for lambda term generation and theorem proving.
* In Proceedings ICLP 2020, arXiv:2009.09158
Interactive Text Graph Mining with a Prolog-based Dialog Engine
Jul 31, 2020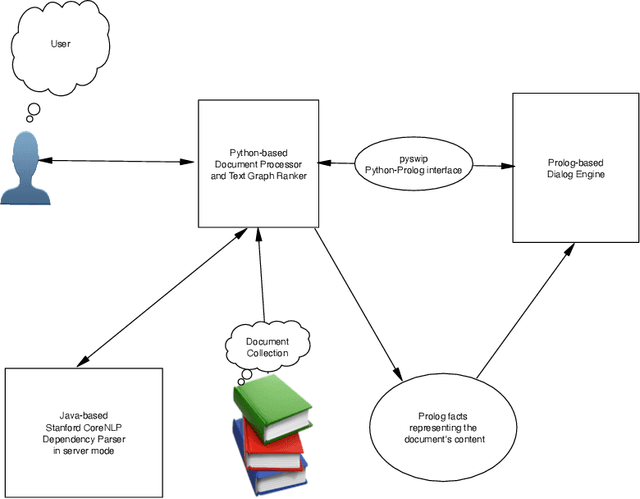
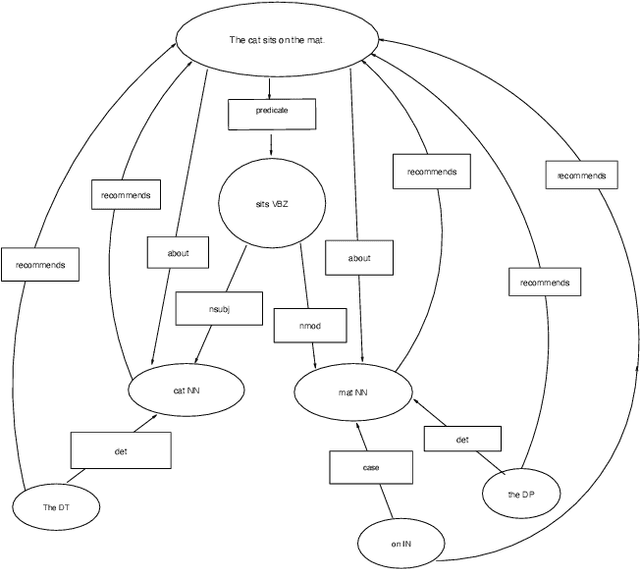
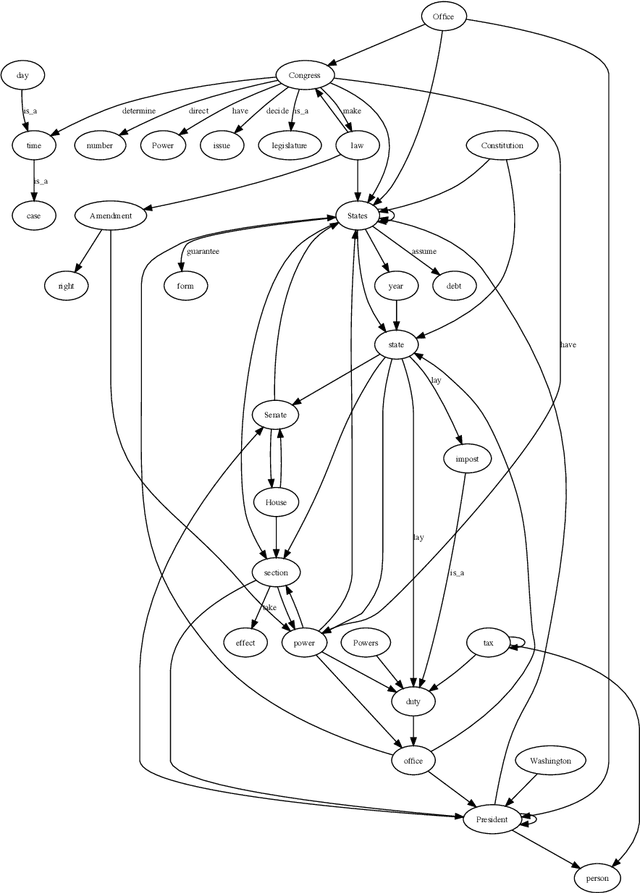
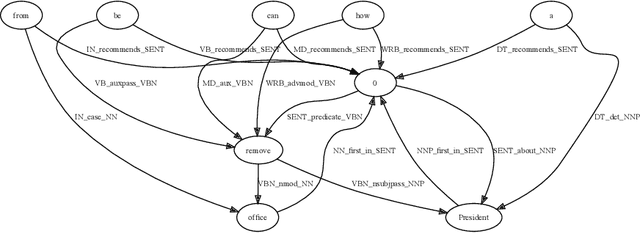
On top of a neural network-based dependency parser and a graph-based natural language processing module we design a Prolog-based dialog engine that explores interactively a ranked fact database extracted from a text document. We reorganize dependency graphs to focus on the most relevant content elements of a sentence and integrate sentence identifiers as graph nodes. Additionally, after ranking the graph we take advantage of the implicit semantic information that dependency links and WordNet bring in the form of subject-verb-object, is-a and part-of relations. Working on the Prolog facts and their inferred consequences, the dialog engine specializes the text graph with respect to a query and reveals interactively the document's most relevant content elements. The open-source code of the integrated system is available at https://github.com/ptarau/DeepRank . Under consideration in Theory and Practice of Logic Programming (TPLP).
Dependency-based Text Graphs for Keyphrase and Summary Extraction with Applications to Interactive Content Retrieval
Sep 20, 2019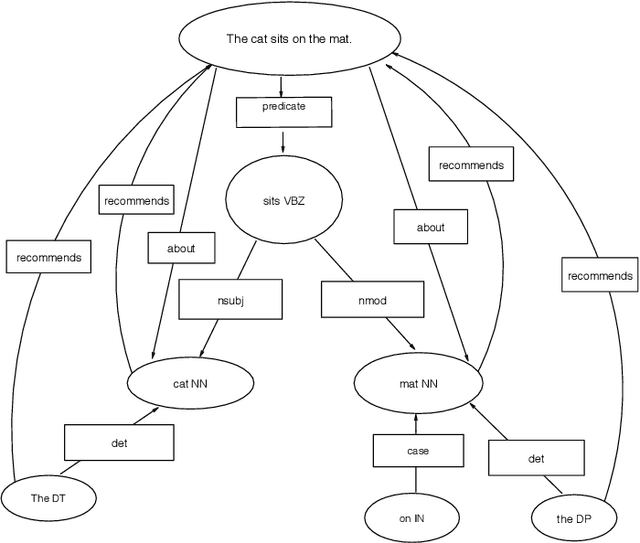
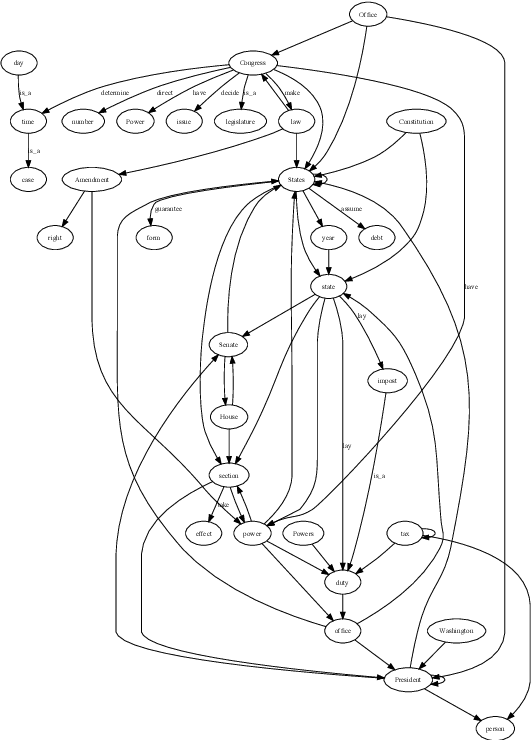


We build a bridge between neural network-based machine learning and graph-based natural language processing and introduce a unified approach to keyphrase, summary and relation extraction by aggregating dependency graphs from links provided by a deep-learning based dependency parser. We reorganize dependency graphs to focus on the most relevant content elements of a sentence, integrate sentence identifiers as graph nodes and after ranking the graph, we extract our keyphrases and summaries from its largest strongly-connected component. We take advantage of the implicit structural information that dependency links bring to extract subject-verb-object, is-a and part-of relations. We put it all together into a proof-of-concept dialog engine that specializes the text graph with respect to a query and reveals interactively the document's most relevant content elements. The open-source code of the integrated system is available at https://github.com/ptarau/DeepRank . Keywords: graph-based natural language processing, dependency graphs, keyphrase, summary and relation extraction, query-driven salient sentence extraction, logic-based dialog engine, synergies between neural and symbolic processing.
Treating Coordination with Datalog Grammars
May 03, 1995In previous work we studied a new type of DCGs, Datalog grammars, which are inspired on database theory. Their efficiency was shown to be better than that of their DCG counterparts under (terminating) OLDT-resolution. In this article we motivate a variant of Datalog grammars which allows us a meta-grammatical treatment of coordination. This treatment improves in some respects over previous work on coordination in logic grammars, although more research is needed for testing it in other respects.