 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Entities: Corpora and Benchmarks
Jun 17, 2024Mathematics is a highly specialized domain with its own unique set of challenges. Despite this, there has been relatively little research on natural language processing for mathematical texts, and there are few mathematical language resources aimed at NLP. In this paper, we aim to provide annotated corpora that can be used to study the language of mathematics in different contexts, ranging from fundamental concepts found in textbooks to advanced research mathematics. We preprocess the corpora with a neural parsing model and some manual intervention to provide part-of-speech tags, lemmas, and dependency trees. In total, we provide 182397 sentences across three corpora. We then aim to test and evaluate several noteworthy natural language processing models using these corpora, to show how well they can adapt to the domain of mathematics and provide useful tools for exploring mathematical language. We evaluate several neural and symbolic models against benchmarks that we extract from the corpus metadata to show that terminology extraction and definition extraction do not easily generalize to mathematics, and that additional work is needed to achieve good performance on these metrics. Finally, we provide a learning assistant that grants access to the content of these corpora in a context-sensitive manner, utilizing text search and entity linking. Though our corpora and benchmarks provide useful metrics for evaluating mathematical language processing, further work is necessary to adapt models to mathematics in order to provide more effective learning assistants and apply NLP methods to different mathematical domains.
Parmesan: mathematical concept extraction for education
Jul 17, 2023Mathematics is a highly specialized domain with its own unique set of challenges that has seen limited study in natural language processing. However, mathematics is used in a wide variety of fields and multidisciplinary research in many different domains often relies on an understanding of mathematical concepts. To aid researchers coming from other fields, we develop a prototype system for searching for and defining mathematical concepts in context, focusing on the field of category theory. This system, Parmesan, depends on natural language processing components including concept extraction, relation extraction, definition extraction, and entity linking. In developing this system, we show that existing techniques cannot be applied directly to the category theory domain, and suggest hybrid techniques that do perform well, though we expect the system to evolve over time. We also provide two cleaned mathematical corpora that power the prototype system, which are based on journal articles and wiki pages, respectively. The corpora have been annotated with dependency trees, lemmas, and part-of-speech tags.
Extracting Mathematical Concepts from Text
Aug 29, 2022

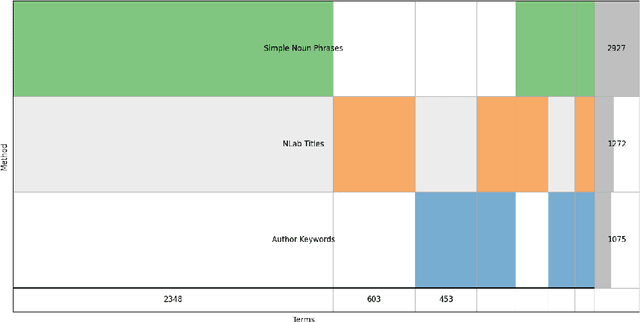
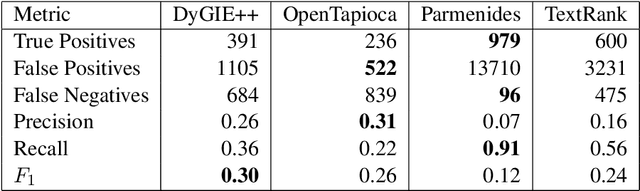
We investigate different systems for extracting mathematical entities from English texts in the mathematical field of category theory as a first step for constructing a mathematical knowledge graph. We consider four different term extractors and compare their results. This small experiment showcases some of the issues with the construction and evaluation of terms extracted from noisy domain text. We also make available two open corpora in research mathematics, in particular in category theory: a small corpus of 755 abstracts from the journal TAC (3188 sentences), and a larger corpus from the nLab community wiki (15,000 sentences).