 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasi-symbolic explanatory NLI via disentanglement: A geometrical examination
Paper and Code

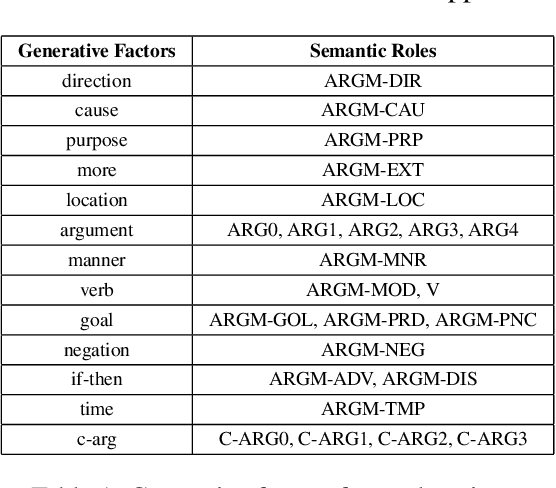
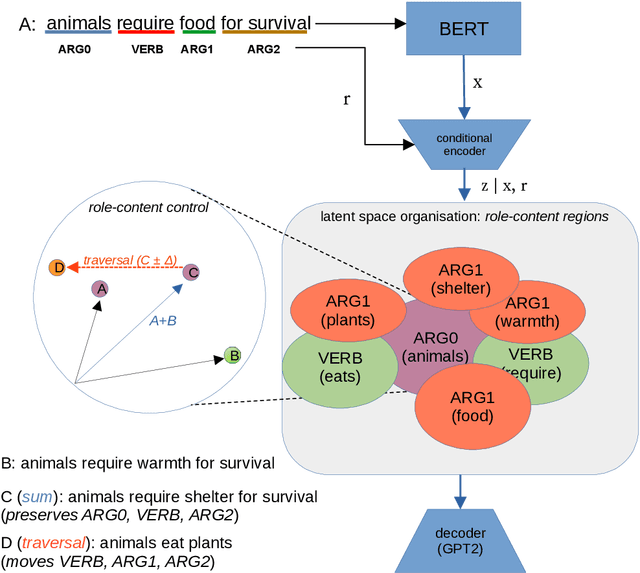
Disentangling the encodings of neural models is a fundamental aspect for improving interpretability, semantic control, and understanding downstream task performance in Natural Language Processing. The connection points between disentanglement and downstream tasks, however, remains underexplored from a explanatory standpoint. This work presents a methodology for assessment of geometrical properties of the resulting latent space w.r.t. vector operations and semantic disentanglement in quantitative and qualitative terms, based on a VAE-based supervised framework. Empirical results indicate that the role-contents of explanations, such as \textit{ARG0-animal}, are disentangled in the latent space, which provides us a chance for controlling the explanation generation by manipulating the traversal of vector over latent space.