 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Discrete Flow Matching for Graph Generation
Mar 31, 2026Denoising-based models, including diffusion and flow matching, have led to substantial advances in graph generation. Despite this progress, such models remain constrained by two fundamental limitations: a computational cost that scales quadratically with the number of nodes and a large number of function evaluations required during generation. In this work, we introduce a novel hierarchical generative framework that reduces the number of node pairs that must be evaluated and adopts discrete flow matching to significantly decrease the number of denoising iterations. We empirically demonstrate that our approach more effectively captures graph distributions while substantially reducing generation time.
Unrestrained Simplex Denoising for Discrete Data. A Non-Markovian Approach Applied to Graph Generation
Mar 30, 2026Denoising models such as Diffusion or Flow Matching have recently advanced generative modeling for discrete structures, yet most approaches either operate directly in the discrete state space, causing abrupt state changes. We introduce simplex denoising, a simple yet effective generative framework that operates on the probability simplex. The key idea is a non-Markovian noising scheme in which, for a given clean data point, noisy representations at different times are conditionally independent. While preserving the theoretical guarantees of denoising-based generative models, our method removes unnecessary constraints, thereby improving performance and simplifying the formulation. Empirically, \emph{unrestrained simplex denoising} surpasses strong discrete diffusion and flow-matching baselines across synthetic and real-world graph benchmarks. These results highlight the probability simplex as an effective framework for discrete generative modeling.
Variational Grey-Box Dynamics Matching
Feb 19, 2026Deep generative models such as flow matching and diffusion models have shown great potential in learning complex distributions and dynamical systems, but often act as black-boxes, neglecting underlying physics. In contrast, physics-based simulation models described by ODEs/PDEs remain interpretable, but may have missing or unknown terms, unable to fully describe real-world observations. We bridge this gap with a novel grey-box method that integrates incomplete physics models directly into generative models. Our approach learns dynamics from observational trajectories alone, without ground-truth physics parameters, in a simulation-free manner that avoids scalability and stability issues of Neural ODEs. The core of our method lies in modelling a structured variational distribution within the flow matching framework, by using two latent encodings: one to model the missing stochasticity and multi-modal velocity, and a second to encode physics parameters as a latent variable with a physics-informed prior. Furthermore, we present an adaptation of the framework to handle second-order dynamics. Our experiments on representative ODE/PDE problems show that our method performs on par with or superior to fully data-driven approaches and previous grey-box baselines, while preserving the interpretability of the physics model. Our code is available at https://github.com/DMML-Geneva/VGB-DM.
Critical Iterative Denoising: A Discrete Generative Model Applied to Graphs
Mar 27, 2025
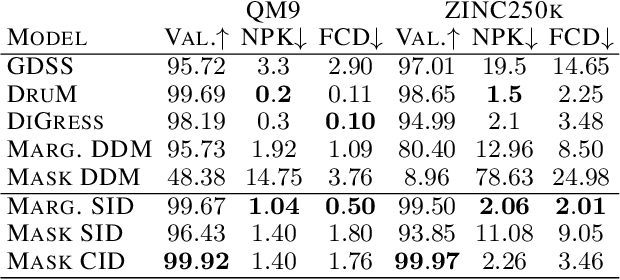

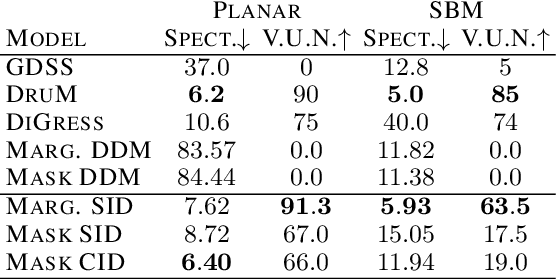
Discrete Diffusion and Flow Matching models have significantly advanced generative modeling for discrete structures, including graphs. However, the time dependencies in the noising process of these models lead to error accumulation and propagation during the backward process. This issue, particularly pronounced in mask diffusion, is a known limitation in sequence modeling and, as we demonstrate, also impacts discrete diffusion models for graphs. To address this problem, we propose a novel framework called Iterative Denoising, which simplifies discrete diffusion and circumvents the issue by assuming conditional independence across time. Additionally, we enhance our model by incorporating a Critic, which during generation selectively retains or corrupts elements in an instance based on their likelihood under the data distribution. Our empirical evaluations demonstrate that the proposed method significantly outperforms existing discrete diffusion baselines in graph generation tasks.
MING: A Functional Approach to Learning Molecular Generative Models
Oct 16, 2024



Traditional molecule generation methods often rely on sequence or graph-based representations, which can limit their expressive power or require complex permutation-equivariant architectures. This paper introduces a novel paradigm for learning molecule generative models based on functional representations. Specifically, we propose Molecular Implicit Neural Generation (MING), a diffusion-based model that learns molecular distributions in function space. Unlike standard diffusion processes in data space, MING employs a novel functional denoising probabilistic process, which jointly denoises the information in both the function's input and output spaces by leveraging an expectation-maximization procedure for latent implicit neural representations of data. This approach allows for a simple yet effective model design that accurately captures underlying function distributions. Experimental results on molecule-related datasets demonstrate MING's superior performance and ability to generate plausible molecular samples, surpassing state-of-the-art data-space methods while offering a more streamlined architecture and significantly faster generation times.
Kolmogorov-Smirnov GAN
Jun 28, 2024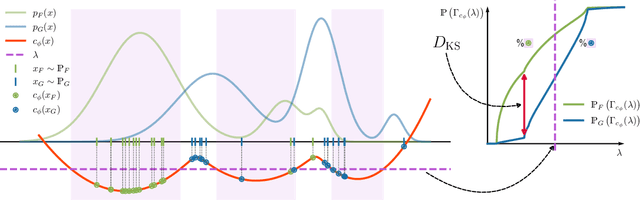
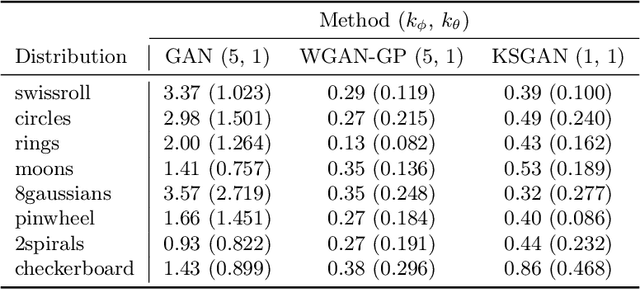
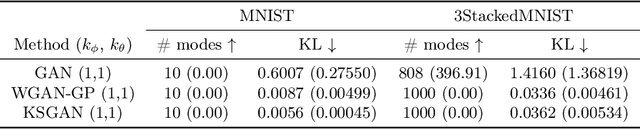
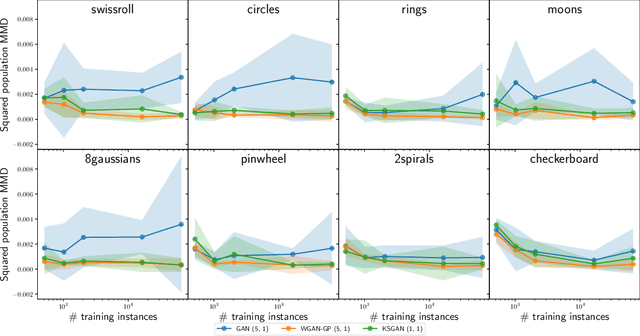
We propose a novel deep generative model, the Kolmogorov-Smirnov Generative Adversarial Network (KSGAN). Unlike existing approaches, KSGAN formulates the learning process as a minimization of the Kolmogorov-Smirnov (KS) distance, generalized to handle multivariate distributions. This distance is calculated using the quantile function, which acts as the critic in the adversarial training process. We formally demonstrate that minimizing the KS distance leads to the trained approximate distribution aligning with the target distribution. We propose an efficient implementation and evaluate its effectiveness through experiments. The results show that KSGAN performs on par with existing adversarial methods, exhibiting stability during training, resistance to mode dropping and collapse, and tolerance to variations in hyperparameter settings. Additionally, we review the literature on the Generalized KS test and discuss the connections between KSGAN and existing adversarial generative models.
Discrete Latent Graph Generative Modeling with Diffusion Bridges
Mar 25, 2024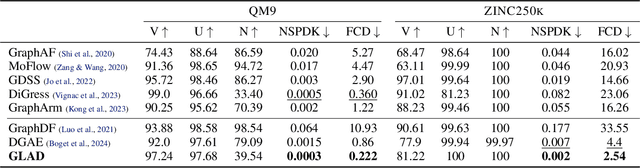
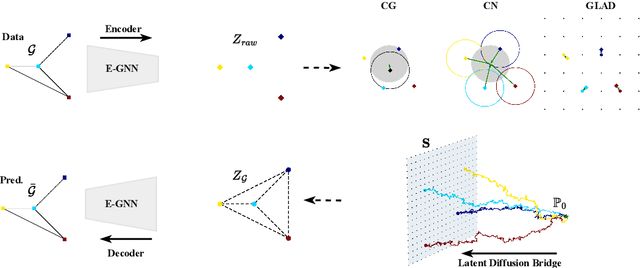
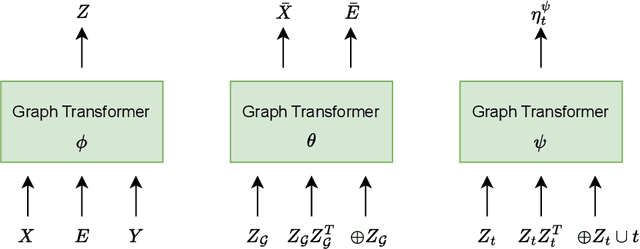

Learning graph generative models over latent spaces has received less attention compared to models that operate on the original data space and has so far demonstrated lacklustre performance. We present GLAD a latent space graph generative model. Unlike most previous latent space graph generative models, GLAD operates on a discrete latent space that preserves to a significant extent the discrete nature of the graph structures making no unnatural assumptions such as latent space continuity. We learn the prior of our discrete latent space by adapting diffusion bridges to its structure. By operating over an appropriately constructed latent space we avoid relying on decompositions that are often used in models that operate in the original data space. We present experiments on a series of graph benchmark datasets which clearly show the superiority of the discrete latent space and obtain state of the art graph generative performance, making GLAD the first latent space graph generative model with competitive performance. Our source code is published at: \url{https://github.com/v18nguye/GLAD}.
Calibrating Neural Simulation-Based Inference with Differentiable Coverage Probability
Oct 20, 2023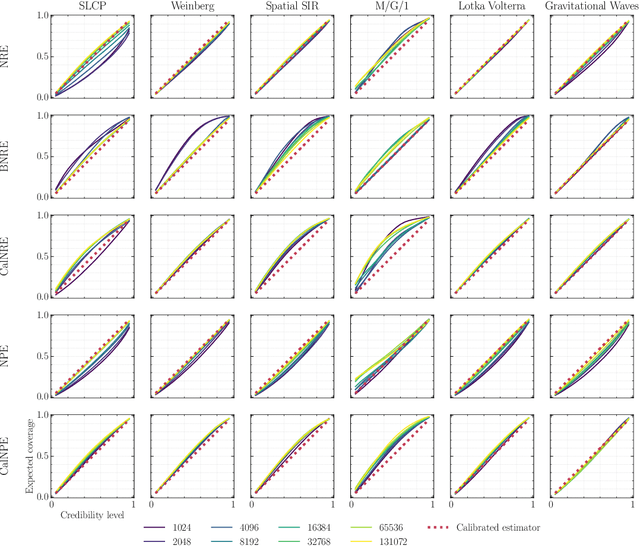
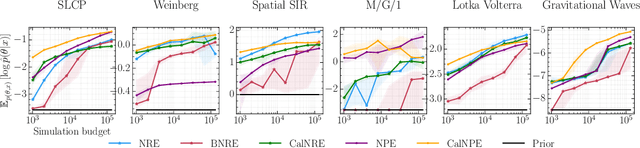
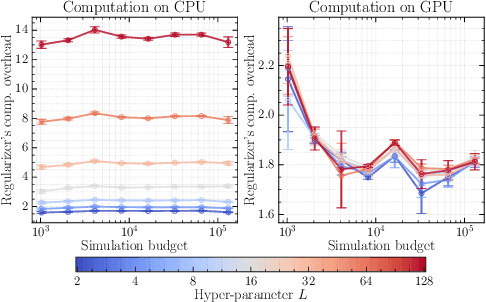
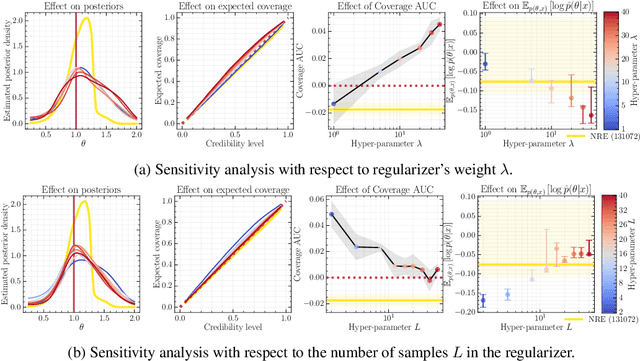
Bayesian inference allows expressing the uncertainty of posterior belief under a probabilistic model given prior information and the likelihood of the evidence. Predominantly, the likelihood function is only implicitly established by a simulator posing the need for simulation-based inference (SBI). However, the existing algorithms can yield overconfident posteriors (Hermans *et al.*, 2022) defeating the whole purpose of credibility if the uncertainty quantification is inaccurate. We propose to include a calibration term directly into the training objective of the neural model in selected amortized SBI techniques. By introducing a relaxation of the classical formulation of calibration error we enable end-to-end backpropagation. The proposed method is not tied to any particular neural model and brings moderate computational overhead compared to the profits it introduces. It is directly applicable to existing computational pipelines allowing reliable black-box posterior inference. We empirically show on six benchmark problems that the proposed method achieves competitive or better results in terms of coverage and expected posterior density than the previously existing approaches.
Sample-Efficient On-Policy Imitation Learning from Observations
Jun 16, 2023Imitation learning from demonstrations (ILD) aims to alleviate numerous shortcomings of reinforcement learning through the use of demonstrations. However, in most real-world applications, expert action guidance is absent, making the use of ILD impossible. Instead, we consider imitation learning from observations (ILO), where no expert actions are provided, making it a significantly more challenging problem to address. Existing methods often employ on-policy learning, which is known to be sample-costly. This paper presents SEILO, a novel sample-efficient on-policy algorithm for ILO, that combines standard adversarial imitation learning with inverse dynamics modeling. This approach enables the agent to receive feedback from both the adversarial procedure and a behavior cloning loss. We empirically demonstrate that our proposed algorithm requires fewer interactions with the environment to achieve expert performance compared to other state-of-the-art on-policy ILO and ILD methods.
Vector-Quantized Graph Auto-Encoder
Jun 13, 2023In this work, we addresses the problem of modeling distributions of graphs. We introduce the Vector-Quantized Graph Auto-Encoder (VQ-GAE), a permutation-equivariant discrete auto-encoder and designed to model the distribution of graphs. By exploiting the permutation-equivariance of graph neural networks (GNNs), our autoencoder circumvents the problem of the ordering of the graph representation. We leverage the capability of GNNs to capture local structures of graphs while employing vector-quantization to prevent the mapping of discrete objects to a continuous latent space. Furthermore, the use of autoregressive models enables us to capture the global structure of graphs via the latent representation. We evaluate our model on standard datasets used for graph generation and observe that it achieves excellent performance on some of the most salient evaluation metrics compared to the state-of-the-art.