 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Example-Based Explanations: Bridging the Gap between Generative Modeling and Explainability
Oct 28, 2024



Recently, several methods have leveraged deep generative modeling to produce example-based explanations of decision algorithms for high-dimensional input data. Despite promising results, a disconnect exists between these methods and the classical explainability literature, which focuses on lower-dimensional data with semantically meaningful features. This conceptual and communication gap leads to misunderstandings and misalignments in goals and expectations. In this paper, we bridge this gap by proposing a novel probabilistic framework for local example-based explanations. Our framework integrates the critical characteristics of classical local explanation desiderata while being amenable to high-dimensional data and their modeling through deep generative models. Our aim is to facilitate communication, foster rigor and transparency, and improve the quality of peer discussion and research progress.
GradCheck: Analyzing classifier guidance gradients for conditional diffusion sampling
Jun 25, 2024



To sample from an unconditionally trained Denoising Diffusion Probabilistic Model (DDPM), classifier guidance adds conditional information during sampling, but the gradients from classifiers, especially those not trained on noisy images, are often unstable. This study conducts a gradient analysis comparing robust and non-robust classifiers, as well as multiple gradient stabilization techniques. Experimental results demonstrate that these techniques significantly improve the quality of class-conditional samples for non-robust classifiers by providing more stable and informative classifier guidance gradients. The findings highlight the importance of gradient stability in enhancing the performance of classifier guidance, especially on non-robust classifiers.
Diffusion-based Visual Counterfactual Explanations -- Towards Systematic Quantitative Evaluation
Aug 11, 2023Latest methods for visual counterfactual explanations (VCE) harness the power of deep generative models to synthesize new examples of high-dimensional images of impressive quality. However, it is currently difficult to compare the performance of these VCE methods as the evaluation procedures largely vary and often boil down to visual inspection of individual examples and small scale user studies. In this work, we propose a framework for systematic, quantitative evaluation of the VCE methods and a minimal set of metrics to be used. We use this framework to explore the effects of certain crucial design choices in the latest diffusion-based generative models for VCEs of natural image classification (ImageNet). We conduct a battery of ablation-like experiments, generating thousands of VCEs for a suite of classifiers of various complexity, accuracy and robustness. Our findings suggest multiple directions for future advancements and improvements of VCE methods. By sharing our methodology and our approach to tackle the computational challenges of such a study on a limited hardware setup (including the complete code base), we offer a valuable guidance for researchers in the field fostering consistency and transparency in the assessment of counterfactual explanations.
Vector-Quantized Graph Auto-Encoder
Jun 13, 2023In this work, we addresses the problem of modeling distributions of graphs. We introduce the Vector-Quantized Graph Auto-Encoder (VQ-GAE), a permutation-equivariant discrete auto-encoder and designed to model the distribution of graphs. By exploiting the permutation-equivariance of graph neural networks (GNNs), our autoencoder circumvents the problem of the ordering of the graph representation. We leverage the capability of GNNs to capture local structures of graphs while employing vector-quantization to prevent the mapping of discrete objects to a continuous latent space. Furthermore, the use of autoregressive models enables us to capture the global structure of graphs via the latent representation. We evaluate our model on standard datasets used for graph generation and observe that it achieves excellent performance on some of the most salient evaluation metrics compared to the state-of-the-art.
GrannGAN: Graph annotation generative adversarial networks
Dec 01, 2022
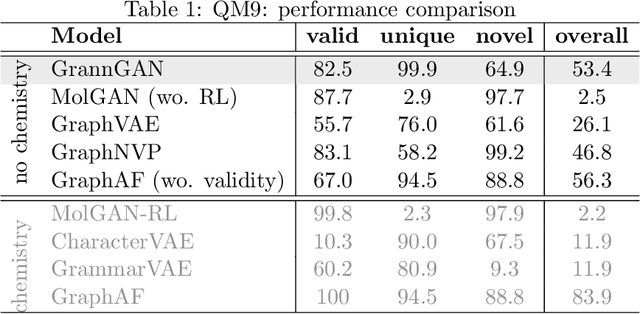
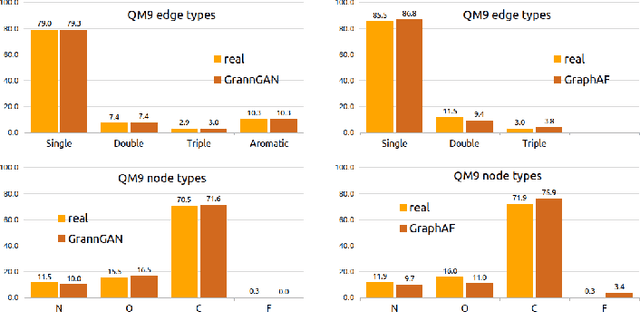

We consider the problem of modelling high-dimensional distributions and generating new examples of data with complex relational feature structure coherent with a graph skeleton. The model we propose tackles the problem of generating the data features constrained by the specific graph structure of each data point by splitting the task into two phases. In the first it models the distribution of features associated with the nodes of the given graph, in the second it complements the edge features conditionally on the node features. We follow the strategy of implicit distribution modelling via generative adversarial network (GAN) combined with permutation equivariant message passing architecture operating over the sets of nodes and edges. This enables generating the feature vectors of all the graph objects in one go (in 2 phases) as opposed to a much slower one-by-one generations of sequential models, prevents the need for expensive graph matching procedures usually needed for likelihood-based generative models, and uses efficiently the network capacity by being insensitive to the particular node ordering in the graph representation. To the best of our knowledge, this is the first method that models the feature distribution along the graph skeleton allowing for generations of annotated graphs with user specified structures. Our experiments demonstrate the ability of our model to learn complex structured distributions through quantitative evaluation over three annotated graph datasets.
Permutation Equivariant Generative Adversarial Networks for Graphs
Dec 07, 2021One of the most discussed issues in graph generative modeling is the ordering of the representation. One solution consists of using equivariant generative functions, which ensure the ordering invariance. After having discussed some properties of such functions, we propose 3G-GAN, a 3-stages model relying on GANs and equivariant functions. The model is still under development. However, we present some encouraging exploratory experiments and discuss the issues still to be addressed.
Sparse Learning for Variable Selection with Structures and Nonlinearities
Mar 26, 2019

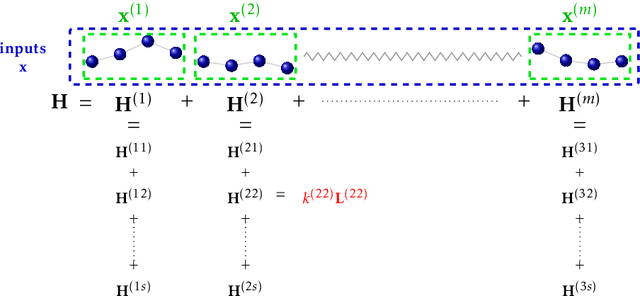
In this thesis we discuss machine learning methods performing automated variable selection for learning sparse predictive models. There are multiple reasons for promoting sparsity in the predictive models. By relying on a limited set of input variables the models naturally counteract the overfitting problem ubiquitous in learning from finite sets of training points. Sparse models are cheaper to use for predictions, they usually require lower computational resources and by relying on smaller sets of inputs can possibly reduce costs for data collection and storage. Sparse models can also contribute to better understanding of the investigated phenomenons as they are easier to interpret than full models.
Continual Classification Learning Using Generative Models
Oct 24, 2018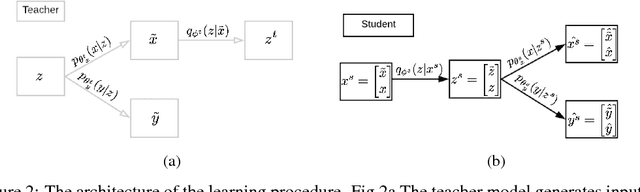
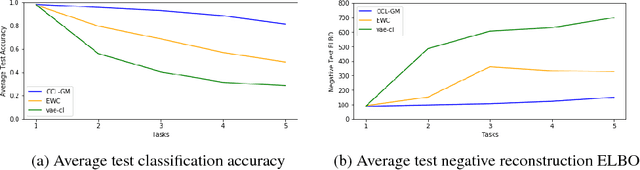
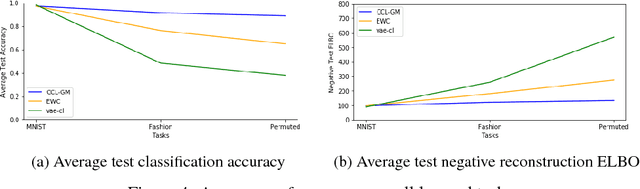
Continual learning is the ability to sequentially learn over time by accommodating knowledge while retaining previously learned experiences. Neural networks can learn multiple tasks when trained on them jointly, but cannot maintain performance on previously learned tasks when tasks are presented one at a time. This problem is called catastrophic forgetting. In this work, we propose a classification model that learns continuously from sequentially observed tasks, while preventing catastrophic forgetting. We build on the lifelong generative capabilities of [10] and extend it to the classification setting by deriving a new variational bound on the joint log likelihood, $\log p(x; y)$.
Lifelong Generative Modeling
Sep 18, 2018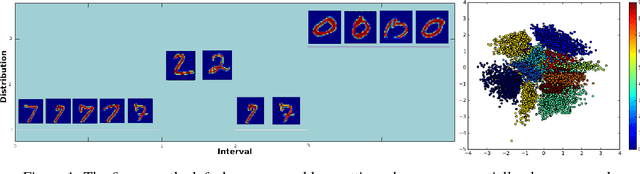
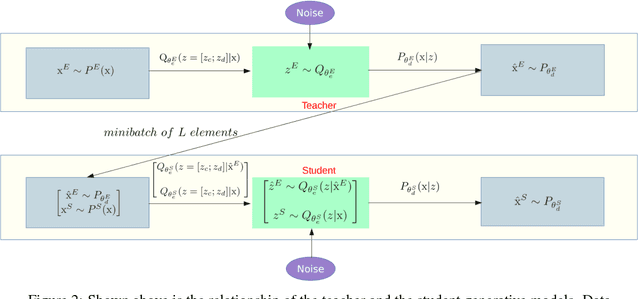
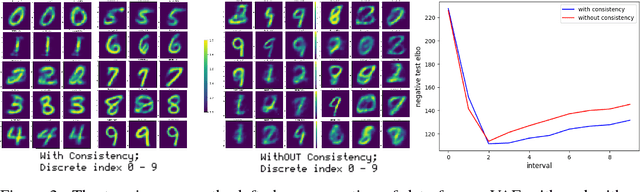
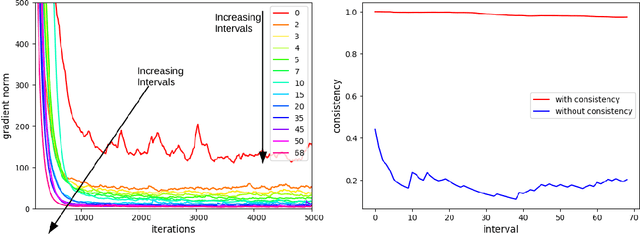
Lifelong learning is the problem of learning multiple consecutive tasks in a sequential manner where knowledge gained from previous tasks is retained and used for future learning. It is essential towards the development of intelligent machines that can adapt to their surroundings. In this work we focus on a lifelong learning approach to generative modeling where we continuously incorporate newly observed distributions into our learnt model. We do so through a student-teacher Variational Autoencoder architecture which allows us to learn and preserve all the distributions seen so far without the need to retain the past data nor the past models. Through the introduction of a novel cross-model regularizer, inspired by a Bayesian update rule, the student model leverages the information learnt by the teacher, which acts as a summary of everything seen till now. The regularizer has the additional benefit of reducing the effect of catastrophic interference that appears when we learn over sequences of distributions. We demonstrate its efficacy in learning sequentially observed distributions as well as its ability to learn a common latent representation across a complex transfer learning scenario.
Learning Predictive Leading Indicators for Forecasting Time Series Systems with Unknown Clusters of Forecast Tasks
Oct 02, 2017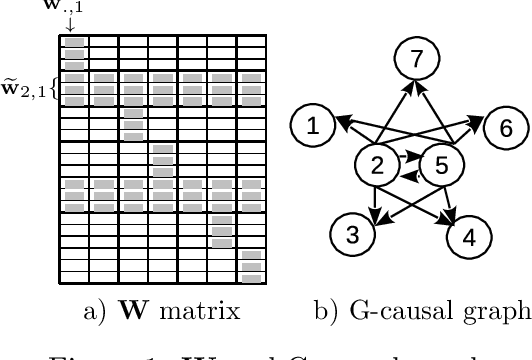

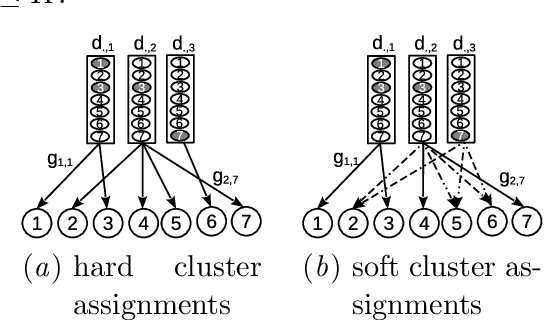
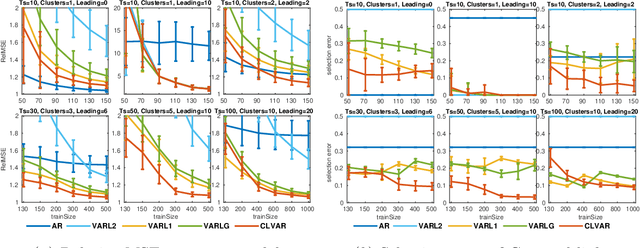
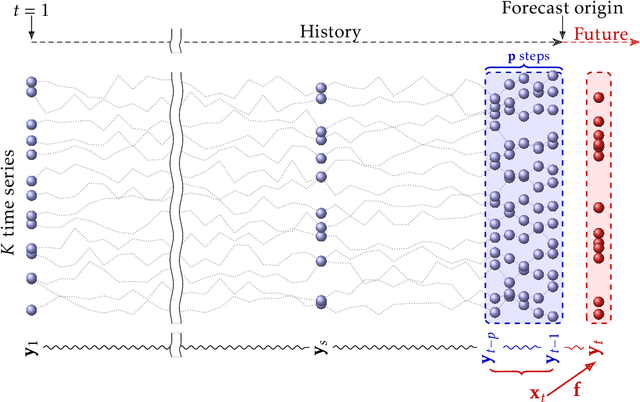
We present a new method for forecasting systems of multiple interrelated time series. The method learns the forecast models together with discovering leading indicators from within the system that serve as good predictors improving the forecast accuracy and a cluster structure of the predictive tasks around these. The method is based on the classical linear vector autoregressive model (VAR) and links the discovery of the leading indicators to inferring sparse graphs of Granger causality. We formulate a new constrained optimisation problem to promote the desired sparse structures across the models and the sharing of information amongst the learning tasks in a multi-task manner. We propose an algorithm for solving the problem and document on a battery of synthetic and real-data experiments the advantages of our new method over baseline VAR models as well as the state-of-the-art sparse VAR learning methods.