 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Latent Graph Generative Modeling with Diffusion Bridges
Mar 25, 2024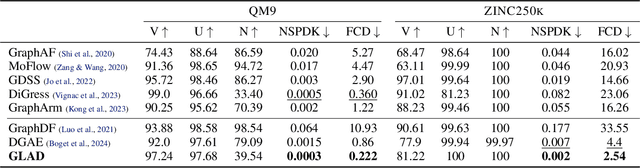
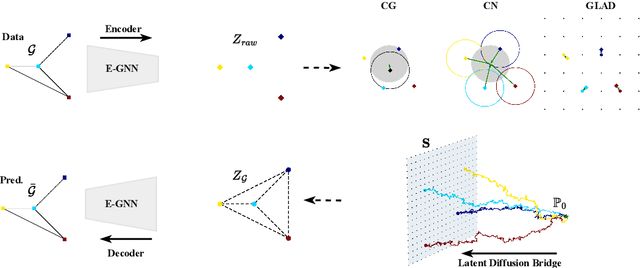
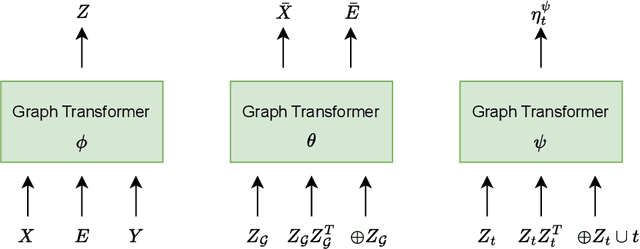

Learning graph generative models over latent spaces has received less attention compared to models that operate on the original data space and has so far demonstrated lacklustre performance. We present GLAD a latent space graph generative model. Unlike most previous latent space graph generative models, GLAD operates on a discrete latent space that preserves to a significant extent the discrete nature of the graph structures making no unnatural assumptions such as latent space continuity. We learn the prior of our discrete latent space by adapting diffusion bridges to its structure. By operating over an appropriately constructed latent space we avoid relying on decompositions that are often used in models that operate in the original data space. We present experiments on a series of graph benchmark datasets which clearly show the superiority of the discrete latent space and obtain state of the art graph generative performance, making GLAD the first latent space graph generative model with competitive performance. Our source code is published at: \url{https://github.com/v18nguye/GLAD}.
Improving VAE generations of multimodal data through data-dependent conditional priors
Nov 25, 2019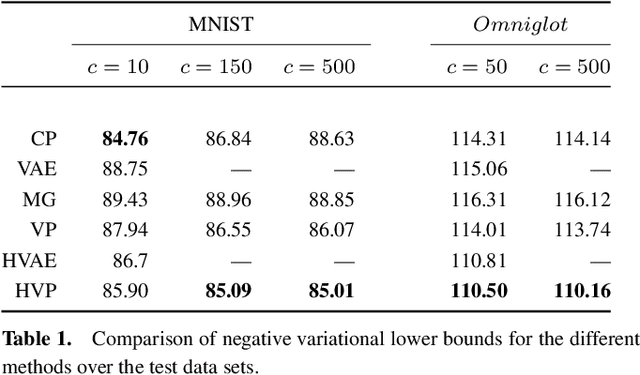


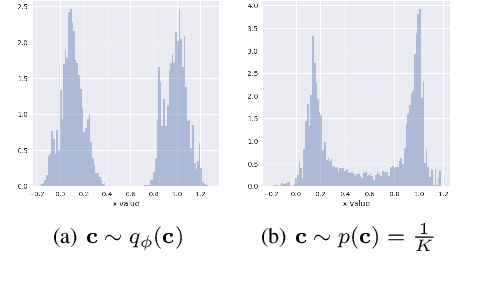
One of the major shortcomings of variational autoencoders is the inability to produce generations from the individual modalities of data originating from mixture distributions. This is primarily due to the use of a simple isotropic Gaussian as the prior for the latent code in the ancestral sampling procedure for the data generations. We propose a novel formulation of variational autoencoders, conditional prior VAE (CP-VAE), which learns to differentiate between the individual mixture components and therefore allows for generations from the distributional data clusters. We assume a two-level generative process with a continuous (Gaussian) latent variable sampled conditionally on a discrete (categorical) latent component. The new variational objective naturally couples the learning of the posterior and prior conditionals, and the learning of the latent categories encoding the multimodality of the original data in an unsupervised manner. The data-dependent conditional priors are then used to sample the continuous latent code when generating new samples from the individual mixture components corresponding to the multimodal structure of the original data. Our experimental results illustrate the generative performance of our new model comparing to multiple baselines.
Continual Classification Learning Using Generative Models
Oct 24, 2018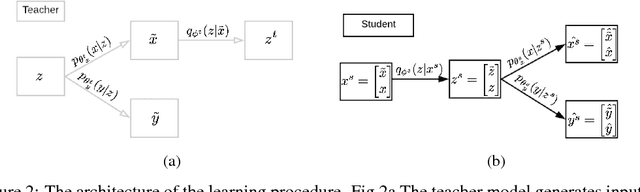
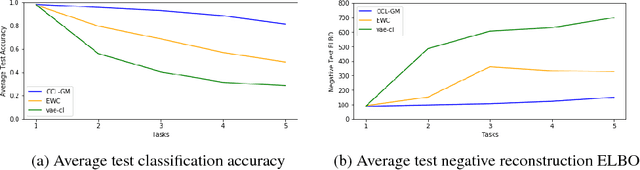
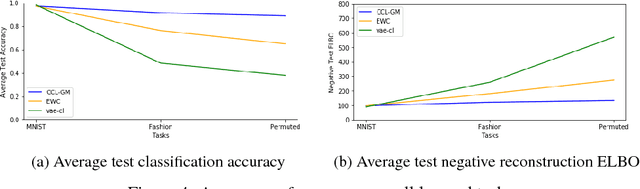
Continual learning is the ability to sequentially learn over time by accommodating knowledge while retaining previously learned experiences. Neural networks can learn multiple tasks when trained on them jointly, but cannot maintain performance on previously learned tasks when tasks are presented one at a time. This problem is called catastrophic forgetting. In this work, we propose a classification model that learns continuously from sequentially observed tasks, while preventing catastrophic forgetting. We build on the lifelong generative capabilities of [10] and extend it to the classification setting by deriving a new variational bound on the joint log likelihood, $\log p(x; y)$.