Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Learning for Variable Selection with Structures and Nonlinearities
Paper and Code
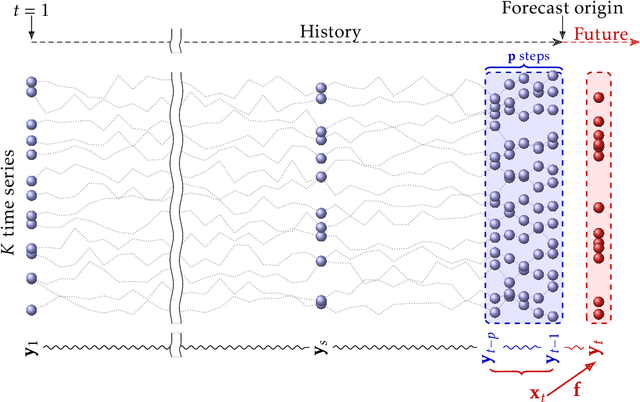

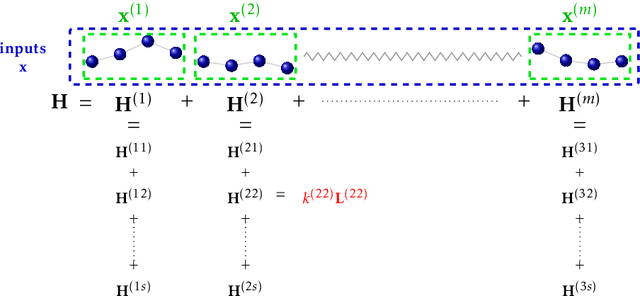
In this thesis we discuss machine learning methods performing automated variable selection for learning sparse predictive models. There are multiple reasons for promoting sparsity in the predictive models. By relying on a limited set of input variables the models naturally counteract the overfitting problem ubiquitous in learning from finite sets of training points. Sparse models are cheaper to use for predictions, they usually require lower computational resources and by relying on smaller sets of inputs can possibly reduce costs for data collection and storage. Sparse models can also contribute to better understanding of the investigated phenomenons as they are easier to interpret than full models.
* PhD thesis
View paper on