 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLapDDPM: A Conditional Graph Diffusion Model for scRNA-seq Generation with Spectral Adversarial Perturbations
Jun 16, 2025Generating high-fidelity and biologically plausible synthetic single-cell RNA sequencing (scRNA-seq) data, especially with conditional control, is challenging due to its high dimensionality, sparsity, and complex biological variations. Existing generative models often struggle to capture these unique characteristics and ensure robustness to structural noise in cellular networks. We introduce LapDDPM, a novel conditional Graph Diffusion Probabilistic Model for robust and high-fidelity scRNA-seq generation. LapDDPM uniquely integrates graph-based representations with a score-based diffusion model, enhanced by a novel spectral adversarial perturbation mechanism on graph edge weights. Our contributions are threefold: we leverage Laplacian Positional Encodings (LPEs) to enrich the latent space with crucial cellular relationship information; we develop a conditional score-based diffusion model for effective learning and generation from complex scRNA-seq distributions; and we employ a unique spectral adversarial training scheme on graph edge weights, boosting robustness against structural variations. Extensive experiments on diverse scRNA-seq datasets demonstrate LapDDPM's superior performance, achieving high fidelity and generating biologically-plausible, cell-type-specific samples. LapDDPM sets a new benchmark for conditional scRNA-seq data generation, offering a robust tool for various downstream biological applications.
Characterizing Massive Activations of Attention Mechanism in Graph Neural Networks
Sep 05, 2024Graph Neural Networks (GNNs) have become increasingly popular for effectively modeling data with graph structures. Recently, attention mechanisms have been integrated into GNNs to improve their ability to capture complex patterns. This paper presents the first comprehensive study revealing a critical, unexplored consequence of this integration: the emergence of Massive Activations (MAs) within attention layers. We introduce a novel method for detecting and analyzing MAs, focusing on edge features in different graph transformer architectures. Our study assesses various GNN models using benchmark datasets, including ZINC, TOX21, and PROTEINS. Key contributions include (1) establishing the direct link between attention mechanisms and MAs generation in GNNs, (2) developing a robust definition and detection method for MAs based on activation ratio distributions, (3) introducing the Explicit Bias Term (EBT) as a potential countermeasure and exploring it as an adversarial framework to assess models robustness based on the presence or absence of MAs. Our findings highlight the prevalence and impact of attention-induced MAs across different architectures, such as GraphTransformer, GraphiT, and SAN. The study reveals the complex interplay between attention mechanisms, model architecture, dataset characteristics, and MAs emergence, providing crucial insights for developing more robust and reliable graph models.
H&E-adversarial network: a convolutional neural network to learn stain-invariant features through Hematoxylin & Eosin regression
Jan 19, 2022
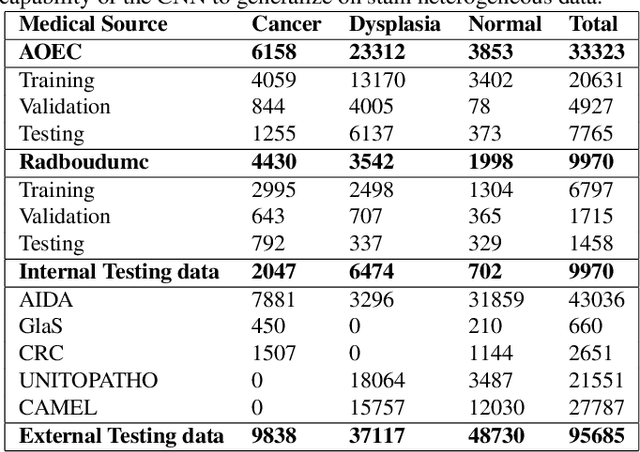
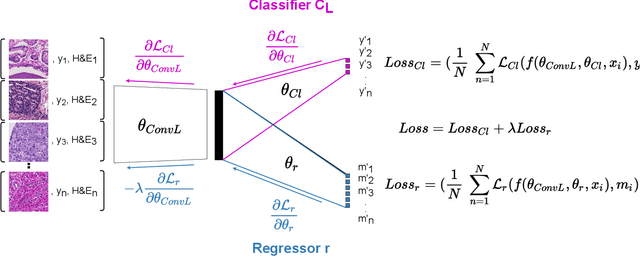

Computational pathology is a domain that aims to develop algorithms to automatically analyze large digitized histopathology images, called whole slide images (WSI). WSIs are produced scanning thin tissue samples that are stained to make specific structures visible. They show stain colour heterogeneity due to different preparation and scanning settings applied across medical centers. Stain colour heterogeneity is a problem to train convolutional neural networks (CNN), the state-of-the-art algorithms for most computational pathology tasks, since CNNs usually underperform when tested on images including different stain variations than those within data used to train the CNN. Despite several methods that were developed, stain colour heterogeneity is still an unsolved challenge that limits the development of CNNs that can generalize on data from several medical centers. This paper aims to present a novel method to train CNNs that better generalize on data including several colour variations. The method, called H&E-adversarial CNN, exploits H&E matrix information to learn stain-invariant features during the training. The method is evaluated on the classification of colon and prostate histopathology images, involving eleven heterogeneous datasets, and compared with five other techniques used to handle stain colour heterogeneity. H&E-adversarial CNNs show an improvement in performance compared to the other algorithms, demonstrating that it can help to better deal with stain colour heterogeneous images.
Learning by stochastic serializations
May 27, 2019



Complex structures are typical in machine learning. Tailoring learning algorithms for every structure requires an effort that may be saved by defining a generic learning procedure adaptive to any complex structure. In this paper, we propose to map any complex structure onto a generic form, called serialization, over which we can apply any sequence-based density estimator. We then show how to transfer the learned density back onto the space of original structures. To expose the learning procedure to the structural particularities of the original structures, we take care that the serializations reflect accurately the structures' properties. Enumerating all serializations is infeasible. We propose an effective way to sample representative serializations from the complete set of serializations which preserves the statistics of the complete set. Our method is competitive or better than state of the art learning algorithms that have been specifically designed for given structures. In addition, since the serialization involves sampling from a combinatorial process it provides considerable protection from overfitting, which we clearly demonstrate on a number of experiments.
Learning Predictive Leading Indicators for Forecasting Time Series Systems with Unknown Clusters of Forecast Tasks
Oct 02, 2017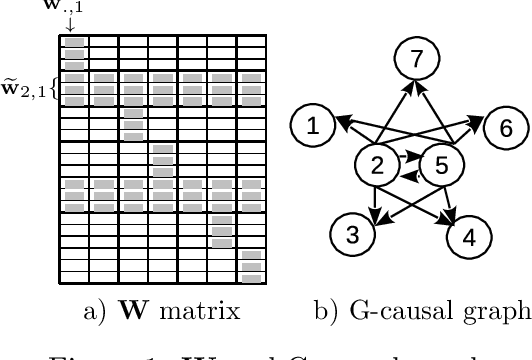

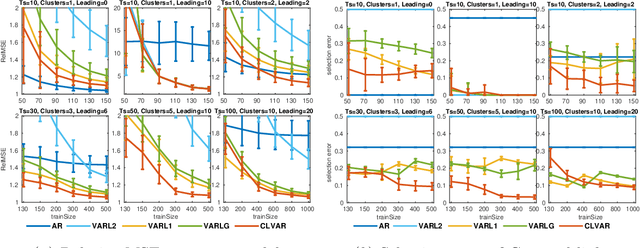
We present a new method for forecasting systems of multiple interrelated time series. The method learns the forecast models together with discovering leading indicators from within the system that serve as good predictors improving the forecast accuracy and a cluster structure of the predictive tasks around these. The method is based on the classical linear vector autoregressive model (VAR) and links the discovery of the leading indicators to inferring sparse graphs of Granger causality. We formulate a new constrained optimisation problem to promote the desired sparse structures across the models and the sharing of information amongst the learning tasks in a multi-task manner. We propose an algorithm for solving the problem and document on a battery of synthetic and real-data experiments the advantages of our new method over baseline VAR models as well as the state-of-the-art sparse VAR learning methods.
Two-Stage Metric Learning
May 12, 2014
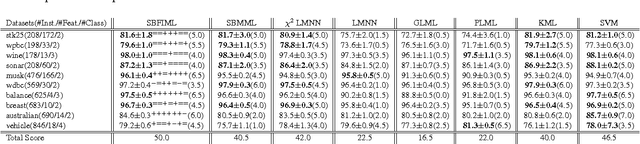

In this paper, we present a novel two-stage metric learning algorithm. We first map each learning instance to a probability distribution by computing its similarities to a set of fixed anchor points. Then, we define the distance in the input data space as the Fisher information distance on the associated statistical manifold. This induces in the input data space a new family of distance metric with unique properties. Unlike kernelized metric learning, we do not require the similarity measure to be positive semi-definite. Moreover, it can also be interpreted as a local metric learning algorithm with well defined distance approximation. We evaluate its performance on a number of datasets. It outperforms significantly other metric learning methods and SVM.