 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipschitzness Is All You Need To Tame Off-policy Generative Adversarial Imitation Learning
Jun 28, 2020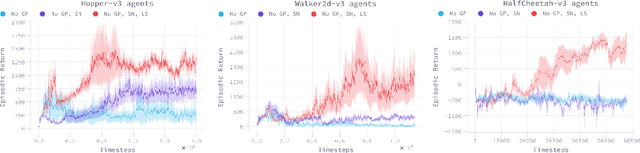
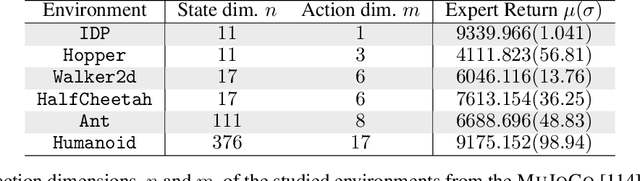
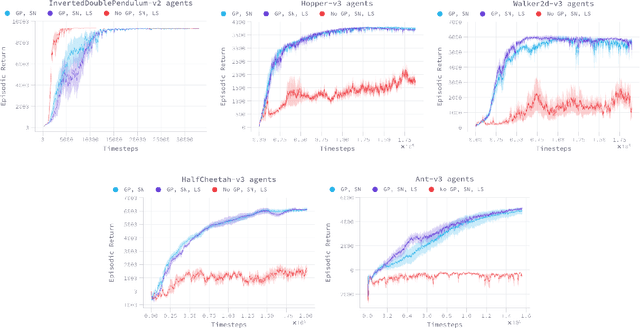
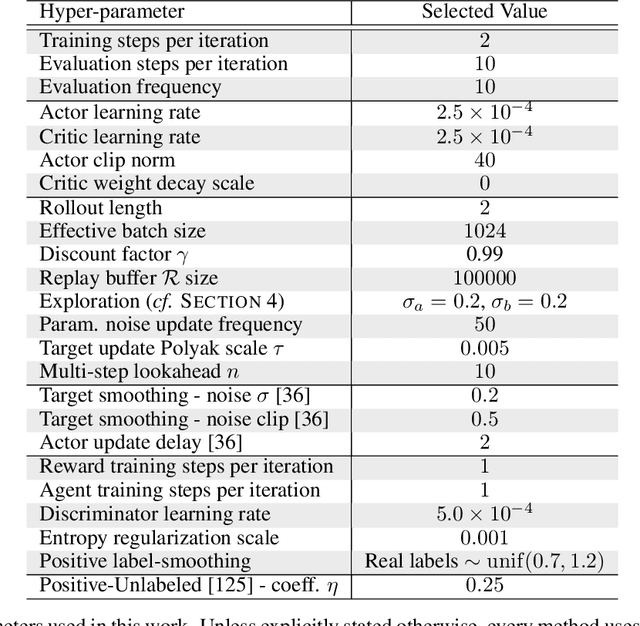
Despite the recent success of reinforcement learning in various domains, these approaches remain, for the most part, deterringly sensitive to hyper-parameters and are often riddled with essential engineering feats allowing their success. We consider the case of off-policy generative adversarial imitation learning, and perform an in-depth review, qualitative and quantitative, of the method. Crucially, we show that forcing the learned reward function to be local Lipschitz-continuous is a sine qua non condition for the method to perform well. We then study the effects of this necessary condition and provide several theoretical results involving the local Lipschitzness of the state-value function. Finally, we propose a novel reward-modulation technique inspired from a new interpretation of gradient-penalty regularization in reinforcement learning. Besides being extremely easy to implement and bringing little to no overhead, we show that our method provides improvements in several continuous control environments of the MuJoCo suite.
Learning by stochastic serializations
May 27, 2019



Complex structures are typical in machine learning. Tailoring learning algorithms for every structure requires an effort that may be saved by defining a generic learning procedure adaptive to any complex structure. In this paper, we propose to map any complex structure onto a generic form, called serialization, over which we can apply any sequence-based density estimator. We then show how to transfer the learned density back onto the space of original structures. To expose the learning procedure to the structural particularities of the original structures, we take care that the serializations reflect accurately the structures' properties. Enumerating all serializations is infeasible. We propose an effective way to sample representative serializations from the complete set of serializations which preserves the statistics of the complete set. Our method is competitive or better than state of the art learning algorithms that have been specifically designed for given structures. In addition, since the serialization involves sampling from a combinatorial process it provides considerable protection from overfitting, which we clearly demonstrate on a number of experiments.
Regularising Non-linear Models Using Feature Side-information
Mar 07, 2017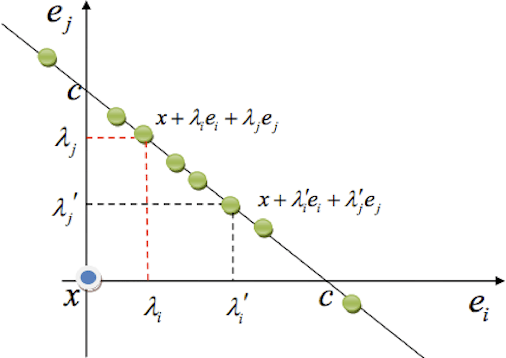
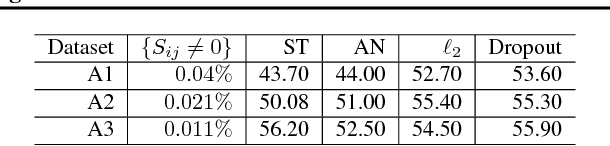
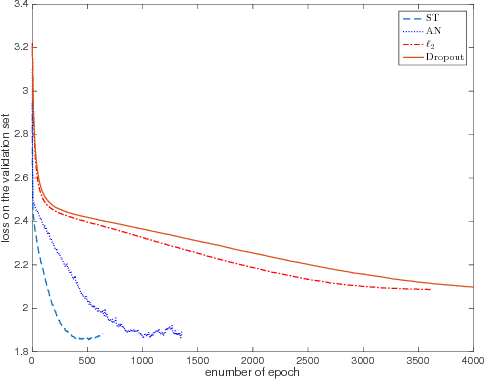
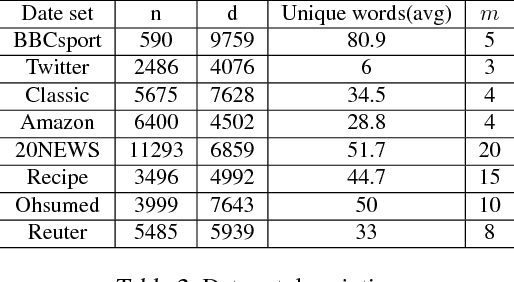
Very often features come with their own vectorial descriptions which provide detailed information about their properties. We refer to these vectorial descriptions as feature side-information. In the standard learning scenario, input is represented as a vector of features and the feature side-information is most often ignored or used only for feature selection prior to model fitting. We believe that feature side-information which carries information about features intrinsic property will help improve model prediction if used in a proper way during learning process. In this paper, we propose a framework that allows for the incorporation of the feature side-information during the learning of very general model families to improve the prediction performance. We control the structures of the learned models so that they reflect features similarities as these are defined on the basis of the side-information. We perform experiments on a number of benchmark datasets which show significant predictive performance gains, over a number of baselines, as a result of the exploitation of the side-information.