 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient On-Policy Imitation Learning from Observations
Jun 16, 2023Imitation learning from demonstrations (ILD) aims to alleviate numerous shortcomings of reinforcement learning through the use of demonstrations. However, in most real-world applications, expert action guidance is absent, making the use of ILD impossible. Instead, we consider imitation learning from observations (ILO), where no expert actions are provided, making it a significantly more challenging problem to address. Existing methods often employ on-policy learning, which is known to be sample-costly. This paper presents SEILO, a novel sample-efficient on-policy algorithm for ILO, that combines standard adversarial imitation learning with inverse dynamics modeling. This approach enables the agent to receive feedback from both the adversarial procedure and a behavior cloning loss. We empirically demonstrate that our proposed algorithm requires fewer interactions with the environment to achieve expert performance compared to other state-of-the-art on-policy ILO and ILD methods.
Where is the Grass Greener? Revisiting Generalized Policy Iteration for Offline Reinforcement Learning
Jul 03, 2021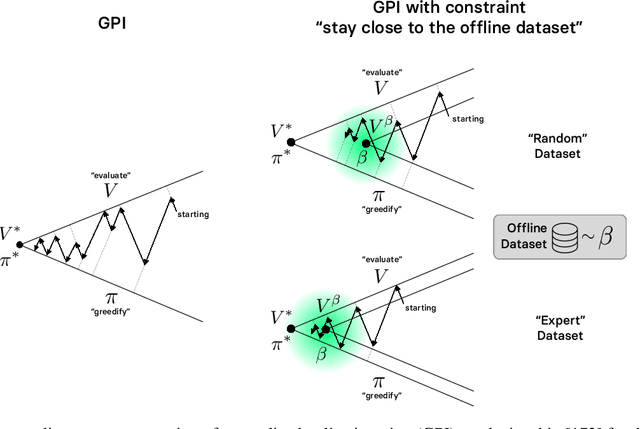
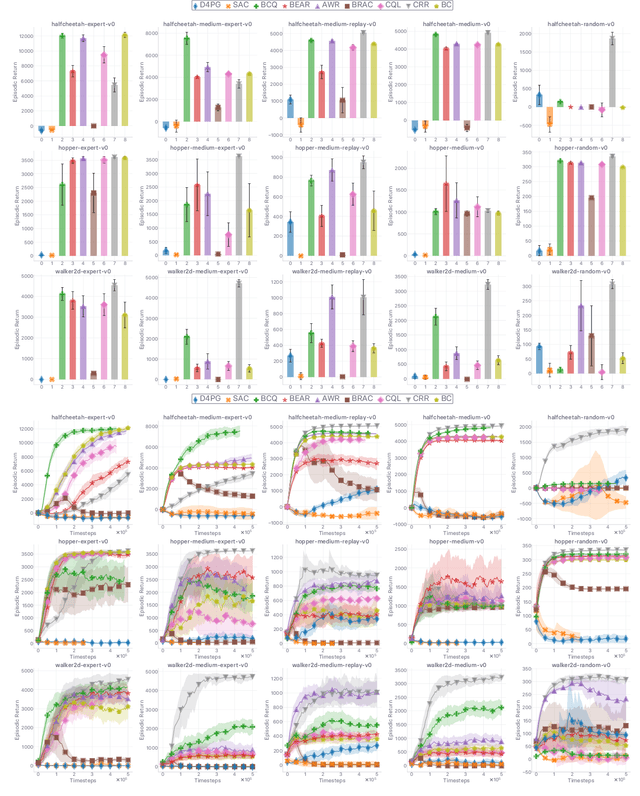
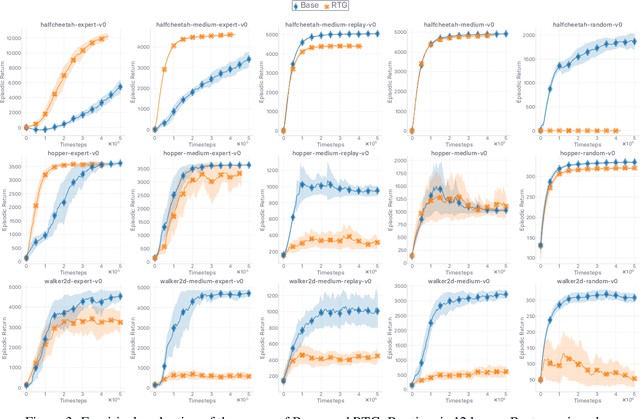
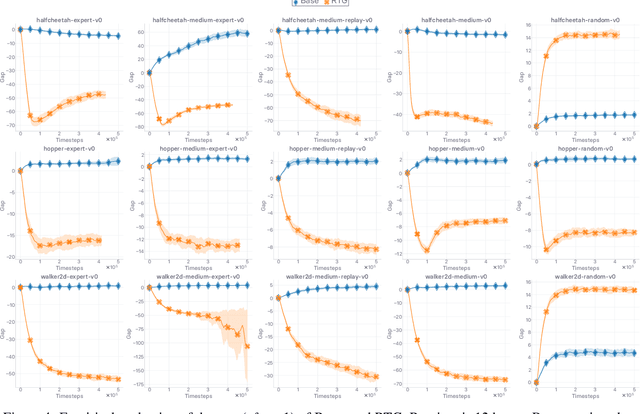
The performance of state-of-the-art baselines in the offline RL regime varies widely over the spectrum of dataset qualities, ranging from "far-from-optimal" random data to "close-to-optimal" expert demonstrations. We re-implement these under a fair, unified, and highly factorized framework, and show that when a given baseline outperforms its competing counterparts on one end of the spectrum, it never does on the other end. This consistent trend prevents us from naming a victor that outperforms the rest across the board. We attribute the asymmetry in performance between the two ends of the quality spectrum to the amount of inductive bias injected into the agent to entice it to posit that the behavior underlying the offline dataset is optimal for the task. The more bias is injected, the higher the agent performs, provided the dataset is close-to-optimal. Otherwise, its effect is brutally detrimental. Adopting an advantage-weighted regression template as base, we conduct an investigation which corroborates that injections of such optimality inductive bias, when not done parsimoniously, makes the agent subpar in the datasets it was dominant as soon as the offline policy is sub-optimal. In an effort to design methods that perform well across the whole spectrum, we revisit the generalized policy iteration scheme for the offline regime, and study the impact of nine distinct newly-introduced proposal distributions over actions, involved in proposed generalization of the policy evaluation and policy improvement update rules. We show that certain orchestrations strike the right balance and can improve the performance on one end of the spectrum without harming it on the other end.
Conditional Neural Relational Inference for Interacting Systems
Jul 02, 2021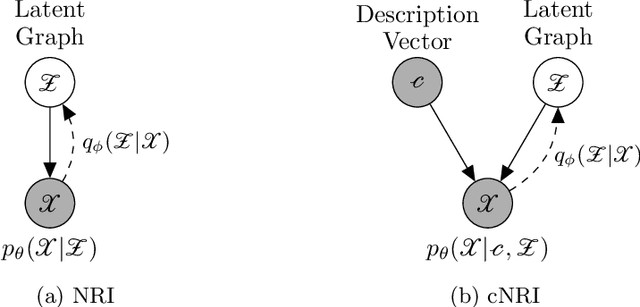

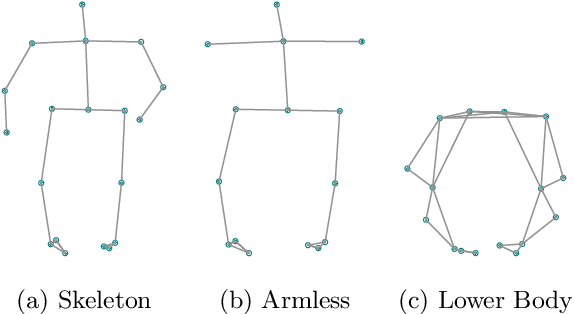
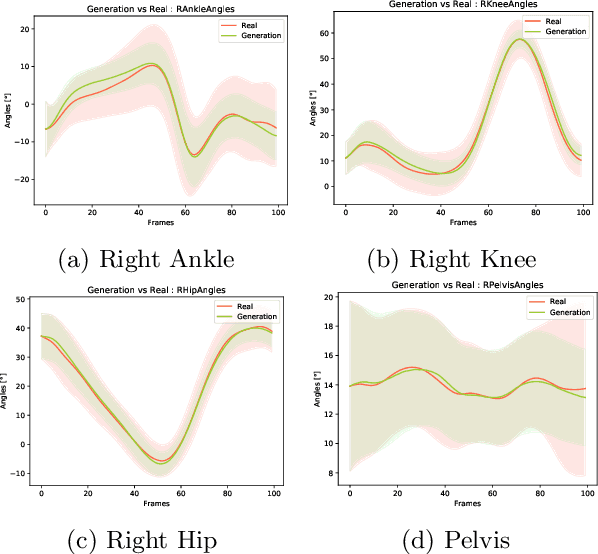
In this work, we want to learn to model the dynamics of similar yet distinct groups of interacting objects. These groups follow some common physical laws that exhibit specificities that are captured through some vectorial description. We develop a model that allows us to do conditional generation from any such group given its vectorial description. Unlike previous work on learning dynamical systems that can only do trajectory completion and require a part of the trajectory dynamics to be provided as input in generation time, we do generation using only the conditioning vector with no access to generation time's trajectories. We evaluate our model in the setting of modeling human gait and, in particular pathological human gait.
Lipschitzness Is All You Need To Tame Off-policy Generative Adversarial Imitation Learning
Jun 28, 2020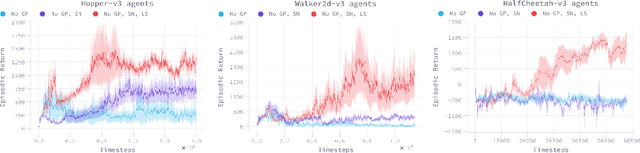
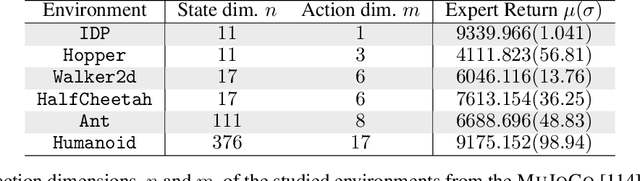
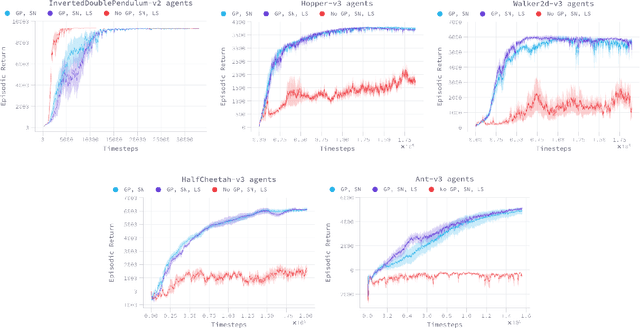
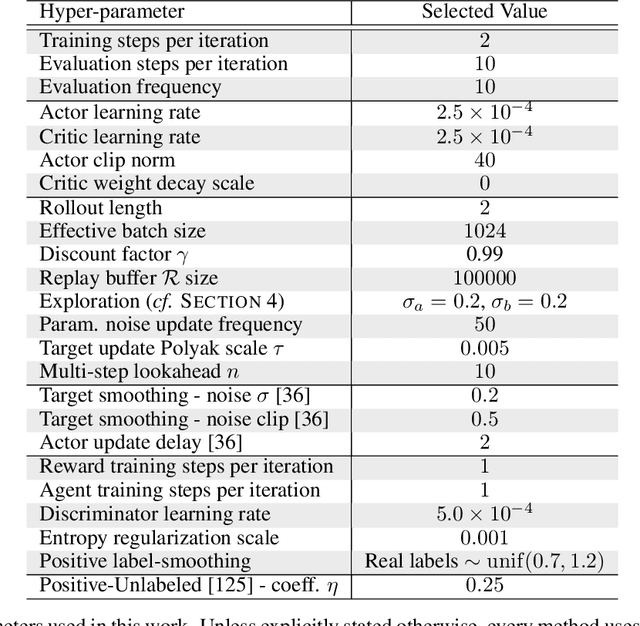
Despite the recent success of reinforcement learning in various domains, these approaches remain, for the most part, deterringly sensitive to hyper-parameters and are often riddled with essential engineering feats allowing their success. We consider the case of off-policy generative adversarial imitation learning, and perform an in-depth review, qualitative and quantitative, of the method. Crucially, we show that forcing the learned reward function to be local Lipschitz-continuous is a sine qua non condition for the method to perform well. We then study the effects of this necessary condition and provide several theoretical results involving the local Lipschitzness of the state-value function. Finally, we propose a novel reward-modulation technique inspired from a new interpretation of gradient-penalty regularization in reinforcement learning. Besides being extremely easy to implement and bringing little to no overhead, we show that our method provides improvements in several continuous control environments of the MuJoCo suite.
Relational Mimic for Visual Adversarial Imitation Learning
Dec 18, 2019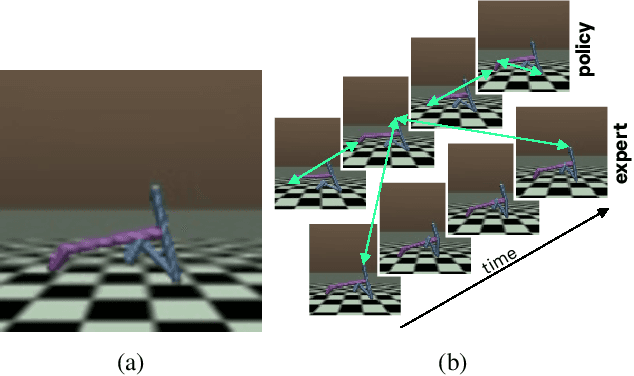

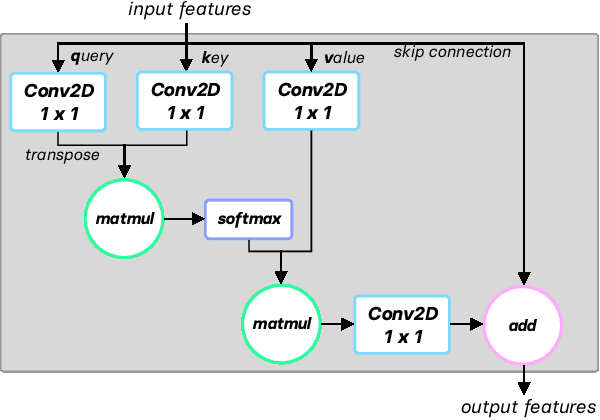
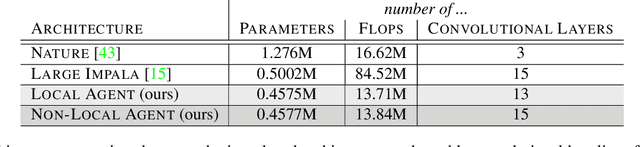
In this work, we introduce a new method for imitation learning from video demonstrations. Our method, Relational Mimic (RM), improves on previous visual imitation learning methods by combining generative adversarial networks and relational learning. RM is flexible and can be used in conjunction with other recent advances in generative adversarial imitation learning to better address the need for more robust and sample-efficient approaches. In addition, we introduce a new neural network architecture that improves upon the previous state-of-the-art in reinforcement learning and illustrate how increasing the relational reasoning capabilities of the agent enables the latter to achieve increasingly higher performance in a challenging locomotion task with pixel inputs. Finally, we study the effects and contributions of relational learning in policy evaluation, policy improvement and reward learning through ablation studies.
Sample-Efficient Imitation Learning via Generative Adversarial Nets
Oct 23, 2018


GAIL is a recent successful imitation learning architecture that exploits the adversarial training procedure introduced in GANs. Albeit successful at generating behaviours similar to those demonstrated to the agent, GAIL suffers from a high sample complexity in the number of interactions it has to carry out in the environment in order to achieve satisfactory performance. We dramatically shrink the amount of interactions with the environment necessary to learn well-behaved imitation policies, by up to several orders of magnitude. Our framework, operating in the model-free regime, exhibits a significant increase in sample-efficiency over previous methods by simultaneously a) learning a self-tuned adversarially-trained surrogate reward and b) leveraging an off-policy actor-critic architecture. We show that our approach is simple to implement and that the learned agents remain remarkably stable, as shown in our experiments that span a variety of continuous control tasks. Video visualisation available at: \url{https://streamable.com/42l01}