 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is the Grass Greener? Revisiting Generalized Policy Iteration for Offline Reinforcement Learning
Paper and Code
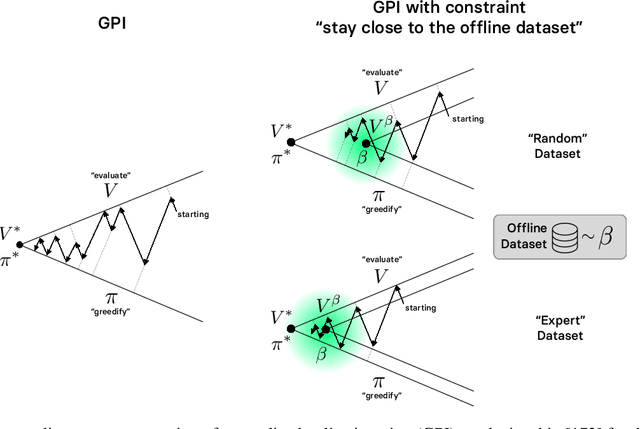
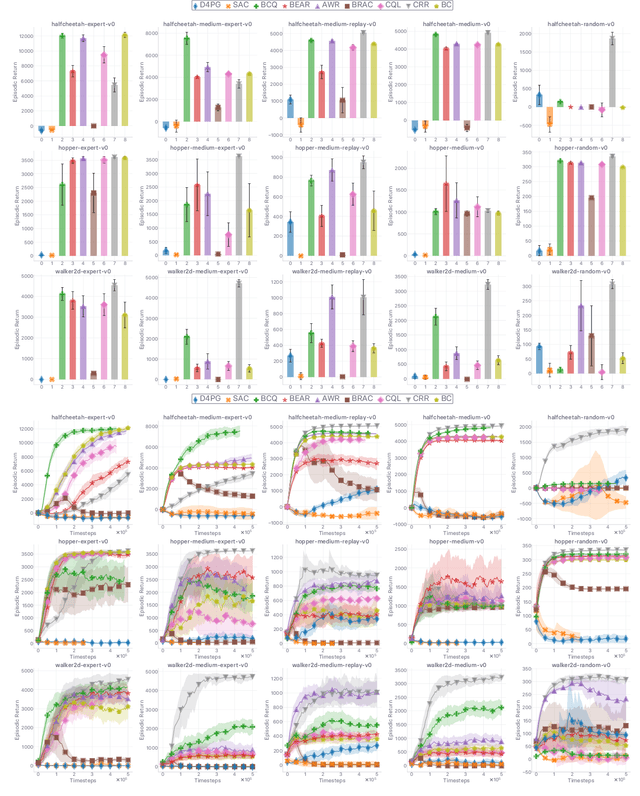
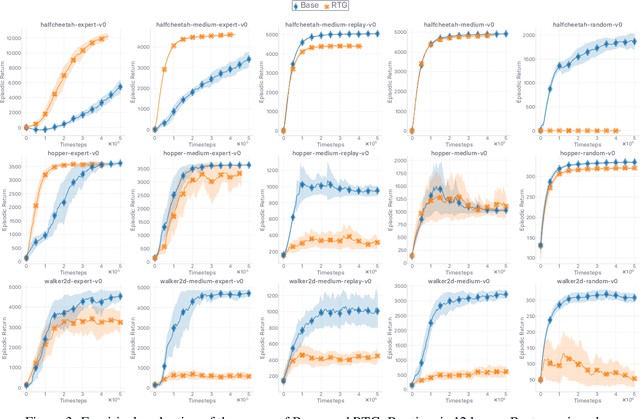
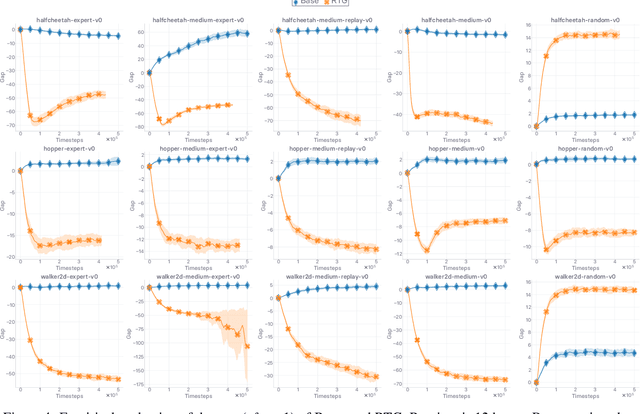
The performance of state-of-the-art baselines in the offline RL regime varies widely over the spectrum of dataset qualities, ranging from "far-from-optimal" random data to "close-to-optimal" expert demonstrations. We re-implement these under a fair, unified, and highly factorized framework, and show that when a given baseline outperforms its competing counterparts on one end of the spectrum, it never does on the other end. This consistent trend prevents us from naming a victor that outperforms the rest across the board. We attribute the asymmetry in performance between the two ends of the quality spectrum to the amount of inductive bias injected into the agent to entice it to posit that the behavior underlying the offline dataset is optimal for the task. The more bias is injected, the higher the agent performs, provided the dataset is close-to-optimal. Otherwise, its effect is brutally detrimental. Adopting an advantage-weighted regression template as base, we conduct an investigation which corroborates that injections of such optimality inductive bias, when not done parsimoniously, makes the agent subpar in the datasets it was dominant as soon as the offline policy is sub-optimal. In an effort to design methods that perform well across the whole spectrum, we revisit the generalized policy iteration scheme for the offline regime, and study the impact of nine distinct newly-introduced proposal distributions over actions, involved in proposed generalization of the policy evaluation and policy improvement update rules. We show that certain orchestrations strike the right balance and can improve the performance on one end of the spectrum without harming it on the other end.