 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning Multi-agent Negotiations via Self-Play
Jan 28, 2020


Making sophisticated, robust, and safe sequential decisions is at the heart of intelligent systems. This is especially critical for planning in complex multi-agent environments, where agents need to anticipate other agents' intentions and possible future actions. Traditional methods formulate the problem as a Markov Decision Process, but the solutions often rely on various assumptions and become brittle when presented with corner cases. In contrast, deep reinforcement learning (Deep RL) has been very effective at finding policies by simultaneously exploring, interacting, and learning from environments. Leveraging the powerful Deep RL paradigm, we demonstrate that an iterative procedure of self-play can create progressively more diverse environments, leading to the learning of sophisticated and robust multi-agent policies. We demonstrate this in a challenging multi-agent simulation of merging traffic, where agents must interact and negotiate with others in order to successfully merge on or off the road. While the environment starts off simple, we increase its complexity by iteratively adding an increasingly diverse set of agents to the agent "zoo" as training progresses. Qualitatively, we find that through self-play, our policies automatically learn interesting behaviors such as defensive driving, overtaking, yielding, and the use of signal lights to communicate intentions to other agents. In addition, quantitatively, we show a dramatic improvement of the success rate of merging maneuvers from 63% to over 98%.
Relational Mimic for Visual Adversarial Imitation Learning
Dec 18, 2019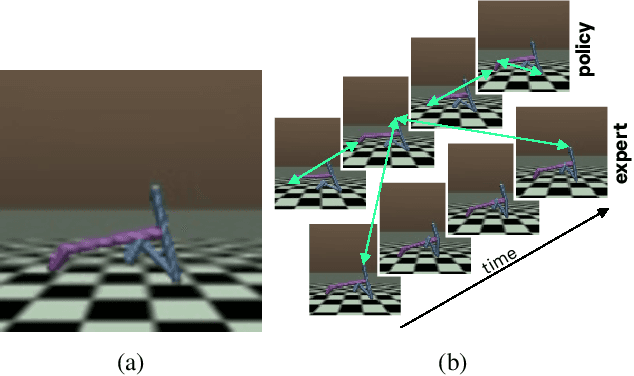

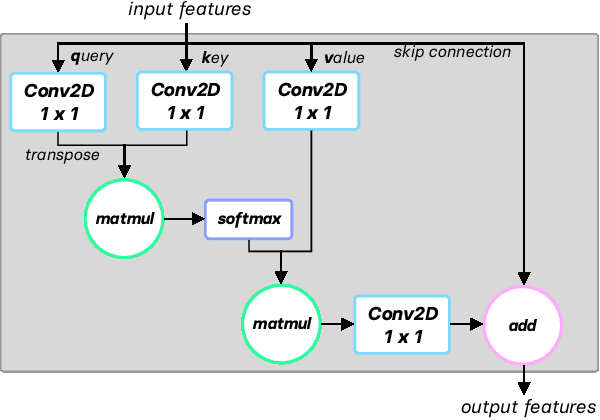
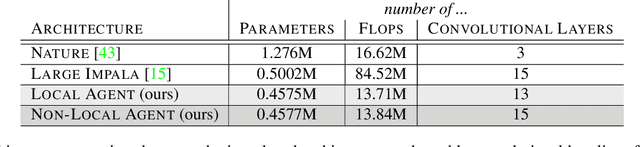
In this work, we introduce a new method for imitation learning from video demonstrations. Our method, Relational Mimic (RM), improves on previous visual imitation learning methods by combining generative adversarial networks and relational learning. RM is flexible and can be used in conjunction with other recent advances in generative adversarial imitation learning to better address the need for more robust and sample-efficient approaches. In addition, we introduce a new neural network architecture that improves upon the previous state-of-the-art in reinforcement learning and illustrate how increasing the relational reasoning capabilities of the agent enables the latter to achieve increasingly higher performance in a challenging locomotion task with pixel inputs. Finally, we study the effects and contributions of relational learning in policy evaluation, policy improvement and reward learning through ablation studies.
Multiple Futures Prediction
Dec 06, 2019
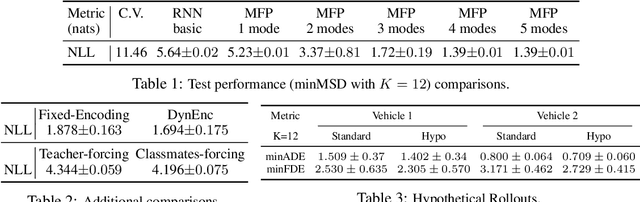


Temporal prediction is critical for making intelligent and robust decisions in complex dynamic environments. Motion prediction needs to model the inherently uncertain future which often contains multiple potential outcomes, due to multi-agent interactions and the latent goals of others. Towards these goals, we introduce a probabilistic framework that efficiently learns latent variables to jointly model the multi-step future motions of agents in a scene. Our framework is data-driven and learns semantically meaningful latent variables to represent the multimodal future, without requiring explicit labels. Using a dynamic attention-based state encoder, we learn to encode the past as well as the future interactions among agents, efficiently scaling to any number of agents. Finally, our model can be used for planning via computing a conditional probability density over the trajectories of other agents given a hypothetical rollout of the 'self' agent. We demonstrate our algorithms by predicting vehicle trajectories of both simulated and real data, demonstrating the state-of-the-art results on several vehicle trajectory datasets.
Worst Cases Policy Gradients
Nov 09, 2019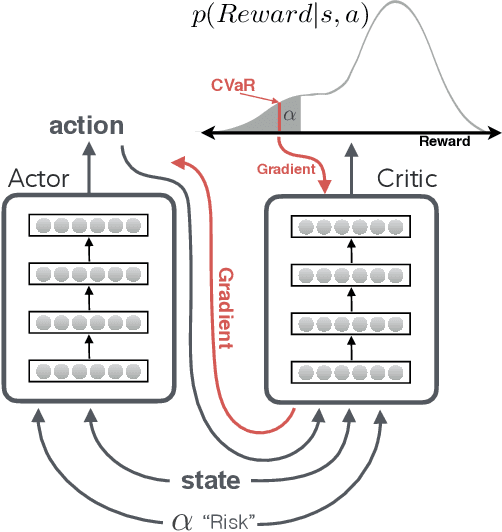
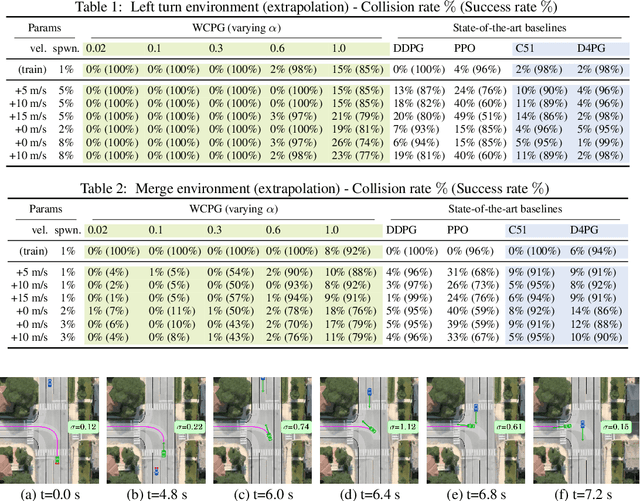
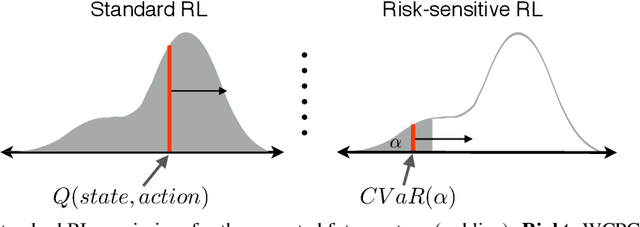

Recent advances in deep reinforcement learning have demonstrated the capability of learning complex control policies from many types of environments. When learning policies for safety-critical applications, it is essential to be sensitive to risks and avoid catastrophic events. Towards this goal, we propose an actor-critic framework that models the uncertainty of the future and simultaneously learns a policy based on that uncertainty model. Specifically, given a distribution of the future return for any state and action, we optimize policies for varying levels of conditional Value-at-Risk. The learned policy can map the same state to different actions depending on the propensity for risk. We demonstrate the effectiveness of our approach in the domain of driving simulations, where we learn maneuvers in two scenarios. Our learned controller can dynamically select actions along a continuous axis, where safe and conservative behaviors are found at one end while riskier behaviors are found at the other. Finally, when testing with very different simulation parameters, our risk-averse policies generalize significantly better compared to other reinforcement learning approaches.