 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Grey-Box Modeling With Adaptive Data-Driven Models Toward Trustworthy Estimation of Theory-Driven Models
Paper and Code
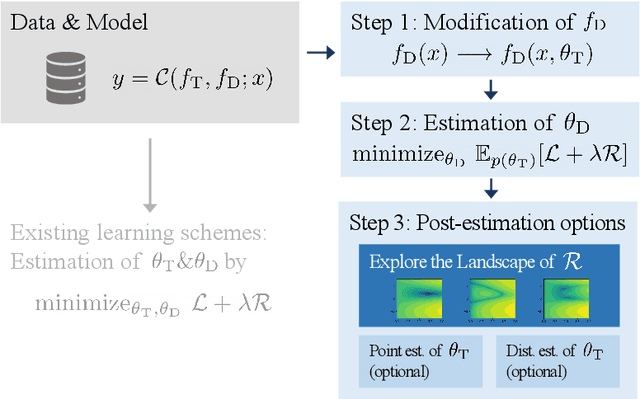

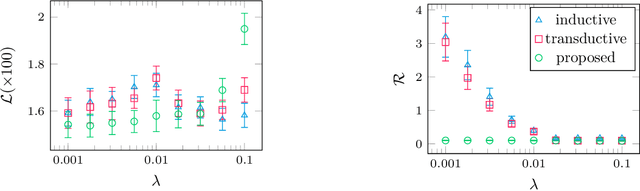
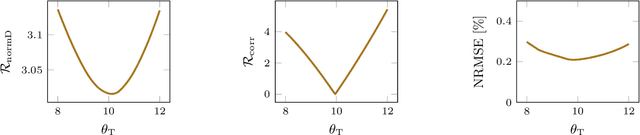
The combination of deep neural nets and theory-driven models, which we call deep grey-box modeling, can be inherently interpretable to some extent thanks to the theory backbone. Deep grey-box models are usually learned with a regularized risk minimization to prevent a theory-driven part from being overwritten and ignored by a deep neural net. However, an estimation of the theory-driven part obtained by uncritically optimizing a regularizer can hardly be trustworthy when we are not sure what regularizer is suitable for the given data, which may harm the interpretability. Toward a trustworthy estimation of the theory-driven part, we should analyze regularizers' behavior to compare different candidates and to justify a specific choice. In this paper, we present a framework that enables us to analyze a regularizer's behavior empirically with a slight change in the neural net's architecture and the training objective.