 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMING: A Functional Approach to Learning Molecular Generative Models
Oct 16, 2024



Traditional molecule generation methods often rely on sequence or graph-based representations, which can limit their expressive power or require complex permutation-equivariant architectures. This paper introduces a novel paradigm for learning molecule generative models based on functional representations. Specifically, we propose Molecular Implicit Neural Generation (MING), a diffusion-based model that learns molecular distributions in function space. Unlike standard diffusion processes in data space, MING employs a novel functional denoising probabilistic process, which jointly denoises the information in both the function's input and output spaces by leveraging an expectation-maximization procedure for latent implicit neural representations of data. This approach allows for a simple yet effective model design that accurately captures underlying function distributions. Experimental results on molecule-related datasets demonstrate MING's superior performance and ability to generate plausible molecular samples, surpassing state-of-the-art data-space methods while offering a more streamlined architecture and significantly faster generation times.
Kolmogorov-Smirnov GAN
Jun 28, 2024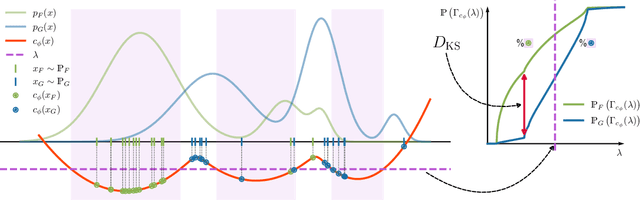
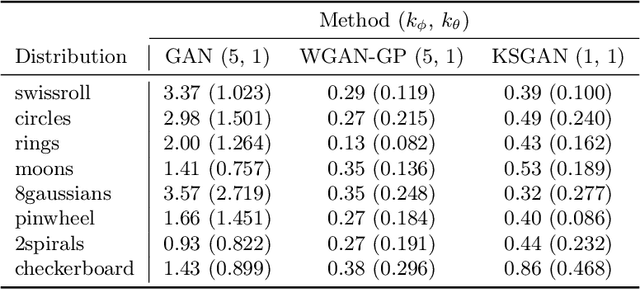
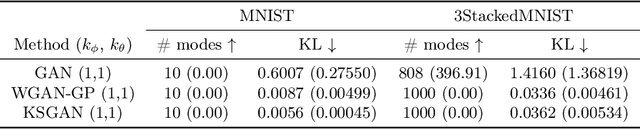
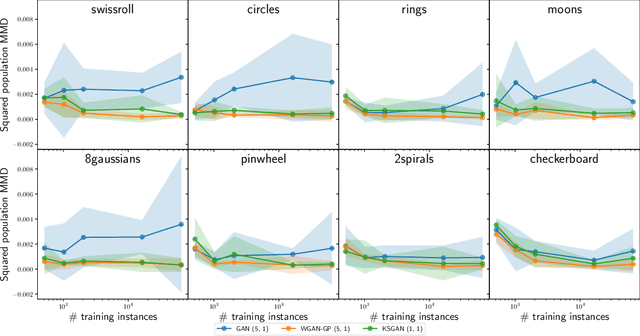
We propose a novel deep generative model, the Kolmogorov-Smirnov Generative Adversarial Network (KSGAN). Unlike existing approaches, KSGAN formulates the learning process as a minimization of the Kolmogorov-Smirnov (KS) distance, generalized to handle multivariate distributions. This distance is calculated using the quantile function, which acts as the critic in the adversarial training process. We formally demonstrate that minimizing the KS distance leads to the trained approximate distribution aligning with the target distribution. We propose an efficient implementation and evaluate its effectiveness through experiments. The results show that KSGAN performs on par with existing adversarial methods, exhibiting stability during training, resistance to mode dropping and collapse, and tolerance to variations in hyperparameter settings. Additionally, we review the literature on the Generalized KS test and discuss the connections between KSGAN and existing adversarial generative models.
Calibrating Neural Simulation-Based Inference with Differentiable Coverage Probability
Oct 20, 2023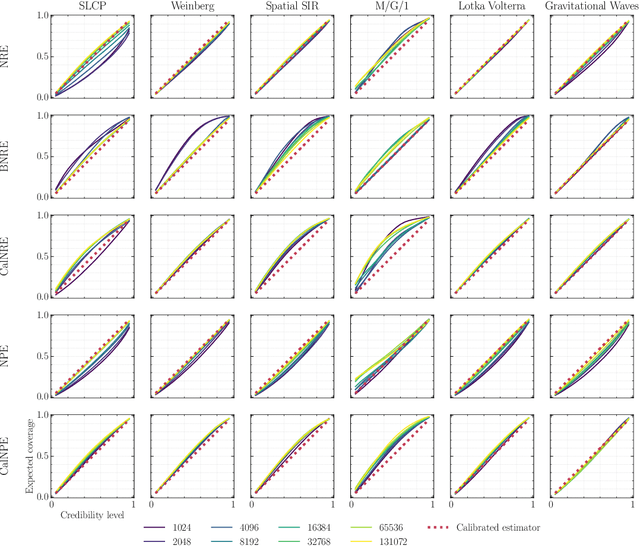
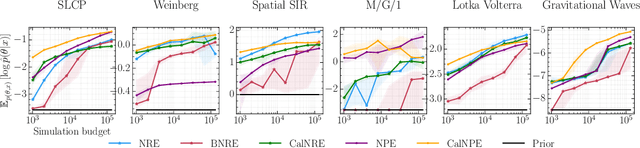
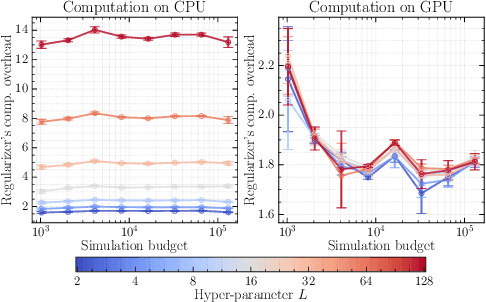
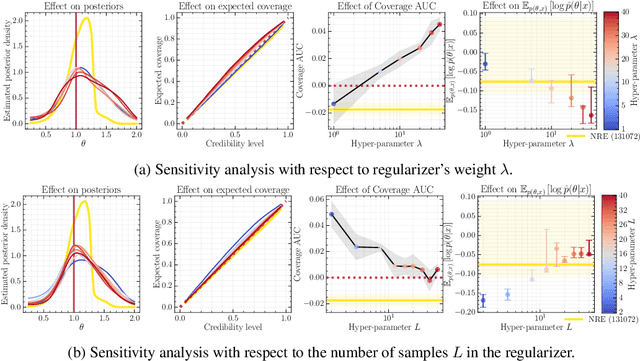
Bayesian inference allows expressing the uncertainty of posterior belief under a probabilistic model given prior information and the likelihood of the evidence. Predominantly, the likelihood function is only implicitly established by a simulator posing the need for simulation-based inference (SBI). However, the existing algorithms can yield overconfident posteriors (Hermans *et al.*, 2022) defeating the whole purpose of credibility if the uncertainty quantification is inaccurate. We propose to include a calibration term directly into the training objective of the neural model in selected amortized SBI techniques. By introducing a relaxation of the classical formulation of calibration error we enable end-to-end backpropagation. The proposed method is not tied to any particular neural model and brings moderate computational overhead compared to the profits it introduces. It is directly applicable to existing computational pipelines allowing reliable black-box posterior inference. We empirically show on six benchmark problems that the proposed method achieves competitive or better results in terms of coverage and expected posterior density than the previously existing approaches.
Incremental embedding for temporal networks
Apr 06, 2019

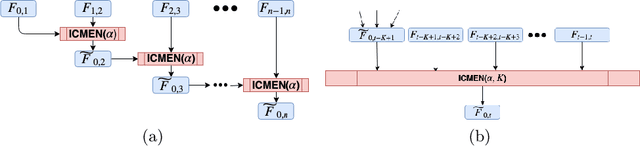

Prediction over edges and nodes in graphs requires appropriate and efficiently achieved data representation. Recent research on representation learning for dynamic networks resulted in a significant progress. However, the more precise and accurate methods, the greater computational and memory complexity. Here, we introduce ICMEN - the first-in-class incremental meta-embedding method that produces vector representations of nodes respecting temporal dependencies in the graph. ICMEN efficiently constructs nodes' embedding from historical representations by linearly convex combinations making the process less memory demanding than state-of-the-art embedding algorithms. The method is capable of constructing representation for inactive and new nodes without a need to re-embed. The results of link prediction on several real-world datasets shown that applying ICMEN incremental meta-method to any base embedding approach, we receive similar results and save memory and computational power. Taken together, our work proposes a new way of efficient online representation learning in dynamic complex networks.