 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Chain-of-Thought Reasoning via Quasi-Symbolic Abstractions
Feb 18, 2025Chain-of-Though (CoT) represents a common strategy for reasoning in Large Language Models (LLMs) by decomposing complex tasks into intermediate inference steps. However, explanations generated via CoT are susceptible to content biases that negatively affect their robustness and faithfulness. To mitigate existing limitations, recent work has proposed using logical formalisms coupled with external symbolic solvers. However, fully symbolic approaches possess the bottleneck of requiring a complete translation from natural language to formal languages, a process that affects efficiency and flexibility. To achieve a trade-off, this paper investigates methods to disentangle content from logical reasoning without a complete formalisation. In particular, we present QuaSAR (for Quasi-Symbolic Abstract Reasoning), a variation of CoT that guides LLMs to operate at a higher level of abstraction via quasi-symbolic explanations. Our framework leverages the capability of LLMs to formalise only relevant variables and predicates, enabling the coexistence of symbolic elements with natural language. We show the impact of QuaSAR for in-context learning and for constructing demonstrations to improve the reasoning capabilities of smaller models. Our experiments show that quasi-symbolic abstractions can improve CoT-based methods by up to 8% accuracy, enhancing robustness and consistency on challenging adversarial variations on both natural language (i.e. MMLU-Redux) and symbolic reasoning tasks (i.e., GSM-Symbolic).
Eliciting Critical Reasoning in Retrieval-Augmented Language Models via Contrastive Explanations
Oct 30, 2024



Retrieval-augmented generation (RAG) has emerged as a critical mechanism in contemporary NLP to support Large Language Models(LLMs) in systematically accessing richer factual context. However, the integration of RAG mechanisms brings its inherent challenges, as LLMs need to deal with potentially noisy contexts. Recent studies have shown that LLMs still struggle to critically analyse RAG-based in-context information, a limitation that may lead to incorrect inferences and hallucinations. In this paper, we investigate how to elicit critical reasoning in RAG via contrastive explanations. In particular, we propose Contrastive-RAG (C-RAG), a framework that (i) retrieves relevant documents given a query, (ii) selects and exemplifies relevant passages, and (iii) generates explanations that explicitly contrast the relevance of the passages to (iv) support the final answer. We show the impact of C-RAG building contrastive reasoning demonstrations from LLMs to instruct smaller models for retrieval-augmented tasks. Extensive experiments demonstrate that C-RAG improves state-of-the-art RAG models while (a) requiring significantly fewer prompts and demonstrations and (b) being robust to perturbations in the retrieved documents.
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
May 01, 2024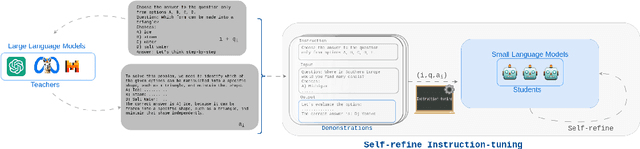
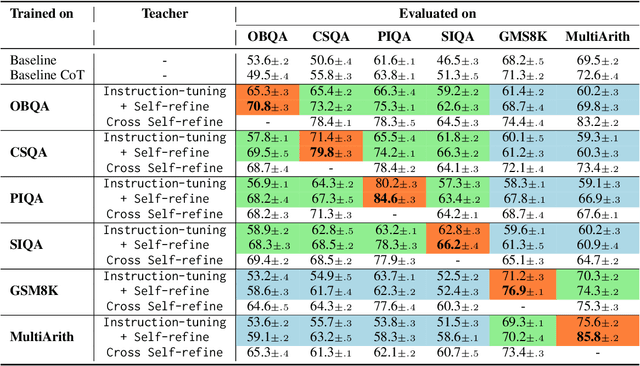
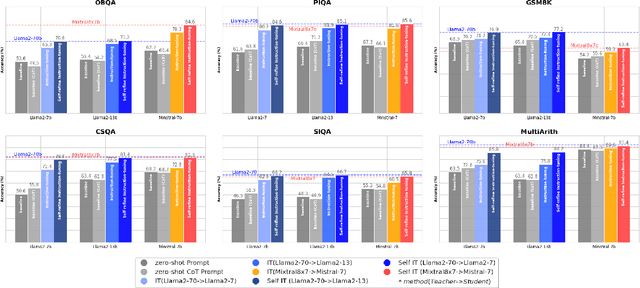

The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.