 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Memorization Editing: Turning Memorization into a Defense to Strengthen Data Privacy in Large Language Models
Jun 09, 2025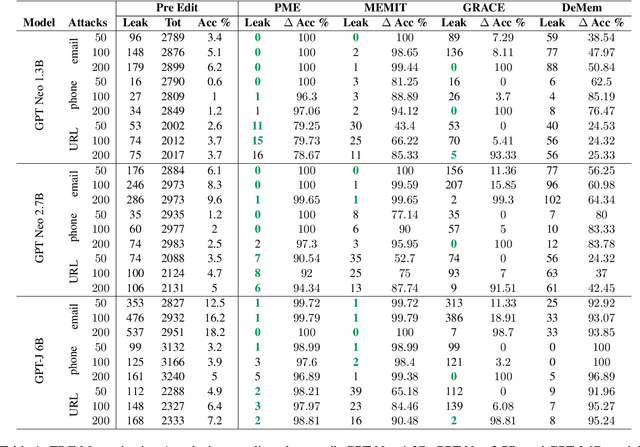

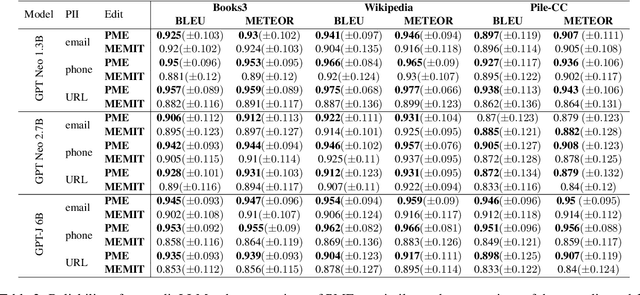
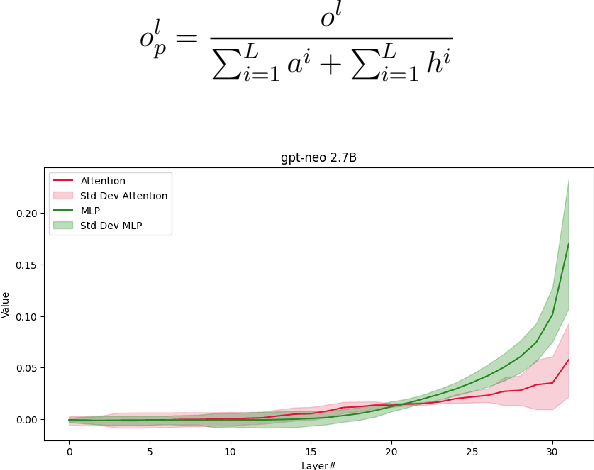
Large Language Models (LLMs) memorize, and thus, among huge amounts of uncontrolled data, may memorize Personally Identifiable Information (PII), which should not be stored and, consequently, not leaked. In this paper, we introduce Private Memorization Editing (PME), an approach for preventing private data leakage that turns an apparent limitation, that is, the LLMs' memorization ability, into a powerful privacy defense strategy. While attacks against LLMs have been performed exploiting previous knowledge regarding their training data, our approach aims to exploit the same kind of knowledge in order to make a model more robust. We detect a memorized PII and then mitigate the memorization of PII by editing a model knowledge of its training data. We verify that our procedure does not affect the underlying language model while making it more robust against privacy Training Data Extraction attacks. We demonstrate that PME can effectively reduce the number of leaked PII in a number of configurations, in some cases even reducing the accuracy of the privacy attacks to zero.
MeMo: Towards Language Models with Associative Memory Mechanisms
Feb 18, 2025



Memorization is a fundamental ability of Transformer-based Large Language Models, achieved through learning. In this paper, we propose a paradigm shift by designing an architecture to memorize text directly, bearing in mind the principle that memorization precedes learning. We introduce MeMo, a novel architecture for language modeling that explicitly memorizes sequences of tokens in layered associative memories. By design, MeMo offers transparency and the possibility of model editing, including forgetting texts. We experimented with the MeMo architecture, showing the memorization power of the one-layer and the multi-layer configurations.
Enhancing Data Privacy in Large Language Models through Private Association Editing
Jun 26, 2024



Large Language Models (LLMs) are powerful tools with extensive applications, but their tendency to memorize private information raises significant concerns as private data leakage can easily happen. In this paper, we introduce Private Association Editing (PAE), a novel defense approach for private data leakage. PAE is designed to effectively remove Personally Identifiable Information (PII) without retraining the model. Our approach consists of a four-step procedure: detecting memorized PII, applying PAE cards to mitigate memorization of private data, verifying resilience to targeted data extraction (TDE) attacks, and ensuring consistency in the post-edit LLMs. The versatility and efficiency of PAE, which allows for batch modifications, significantly enhance data privacy in LLMs. Experimental results demonstrate the effectiveness of PAE in mitigating private data leakage. We believe PAE will serve as a critical tool in the ongoing effort to protect data privacy in LLMs, encouraging the development of safer models for real-world applications.
A Trip Towards Fairness: Bias and De-Biasing in Large Language Models
May 23, 2023An outbreak in the popularity of transformer-based Language Models (such as GPT (Brown et al., 2020) and PaLM (Chowdhery et al., 2022)) has opened the doors to new Machine Learning applications. In particular, in Natural Language Processing and how pre-training from large text, corpora is essential in achieving remarkable results in downstream tasks. However, these Language Models seem to have inherent biases toward certain demographics reflected in their training data. While research has attempted to mitigate this problem, existing methods either fail to remove bias altogether, degrade performance, or are expensive. This paper examines the bias produced by promising Language Models when varying parameters and pre-training data. Finally, we propose a de-biasing technique that produces robust de-bias models that maintain performance on downstream tasks.