 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Fingerprint in Transformer Models: How Language Variation Influences Parameter Selection in Irony Detection
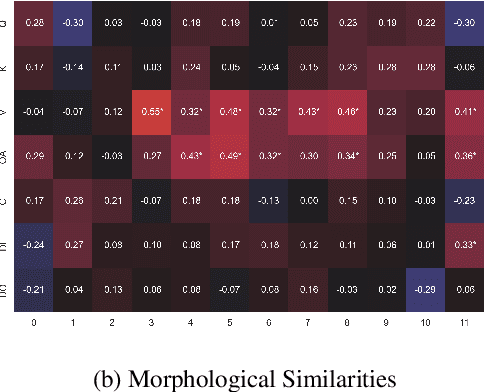
Jun 04, 2024This paper explores the correlation between linguistic diversity, sentiment analysis and transformer model architectures. We aim to investigate how different English variations impact transformer-based models for irony detection. To conduct our study, we used the EPIC corpus to extract five diverse English variation-specific datasets and applied the KEN pruning algorithm on five different architectures. Our results reveal several similarities between optimal subnetworks, which provide insights into the linguistic variations that share strong resemblances and those that exhibit greater dissimilarities. We discovered that optimal subnetworks across models share at least 60% of their parameters, emphasizing the significance of parameter values in capturing and interpreting linguistic variations. This study highlights the inherent structural similarities between models trained on different variants of the same language and also the critical role of parameter values in capturing these nuances.
Less is KEN: a Universal and Simple Non-Parametric Pruning Algorithm for Large Language Models
Feb 05, 2024Neural network pruning has become increasingly crucial due to the complexity of neural network models and their widespread use in various fields. Existing pruning algorithms often suffer from limitations such as architecture specificity, excessive complexity and reliance on complex calculations, rendering them impractical for real-world applications. In this paper, we propose KEN: a straightforward, universal and unstructured pruning algorithm based on Kernel Density Estimation (KDE). KEN aims to construct optimized transformer models by selectively preserving the most significant parameters while restoring others to their pre-training state. This approach maintains model performance while allowing storage of only the optimized subnetwork, leading to significant memory savings. Extensive evaluations on seven transformer models demonstrate that KEN achieves equal or better performance than the original models with a minimum parameter reduction of 25%. In-depth comparisons against other pruning and PEFT algorithms confirm KEN effectiveness. Furthermore, we introduce KEN_viz, an explainable tool that visualizes the optimized model composition and the subnetwork selected by KEN.
Exploring Linguistic Properties of Monolingual BERTs with Typological Classification among Languages
May 03, 2023
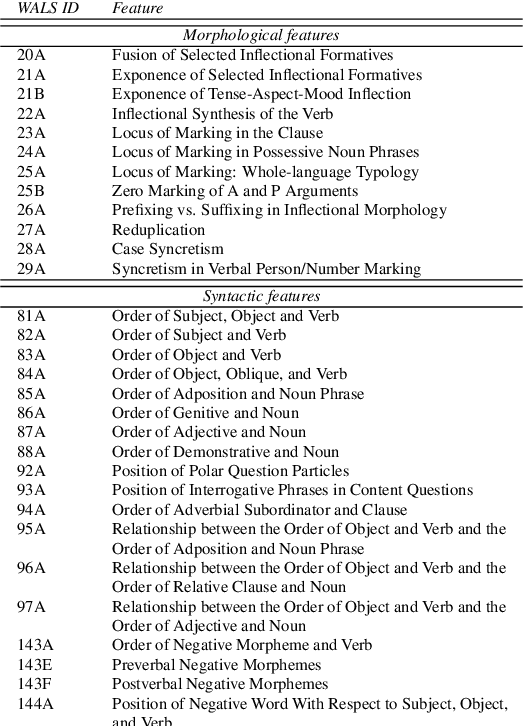
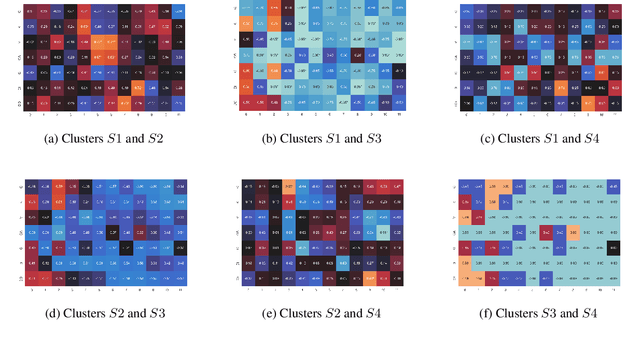
The overwhelming success of transformers is a real conundrum stimulating a compelling question: are these machines replicating some traditional linguistic models or discovering radically new theories? In this paper, we propose a novel standpoint to investigate this important question. Using typological similarities among languages, we aim to layer-wise compare transformers for different languages to observe whether these similarities emerge for particular layers. For this investigation, we propose to use Centered kernel alignment to measure similarity among weight matrices. We discovered that syntactic typological similarity is consistent with the similarity among weights in the middle layers. This finding confirms results obtained by syntactically probing BERT and, thus, gives an important confirmation that BERT is replicating traditional linguistic models.
Every time I fire a conversational designer, the performance of the dialog system goes down
Sep 27, 2021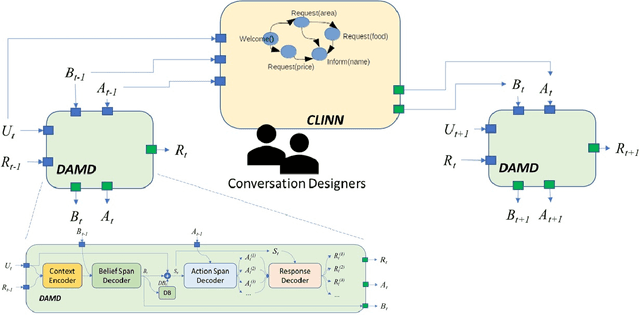
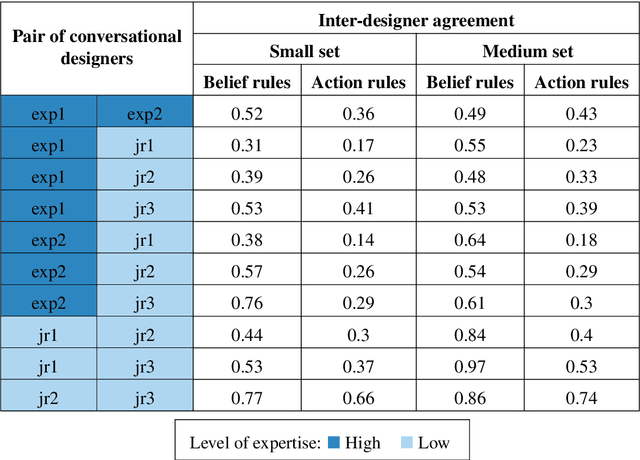
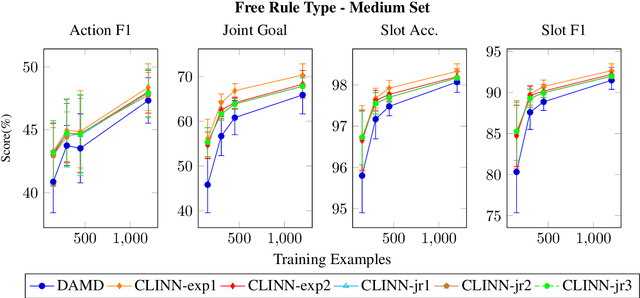
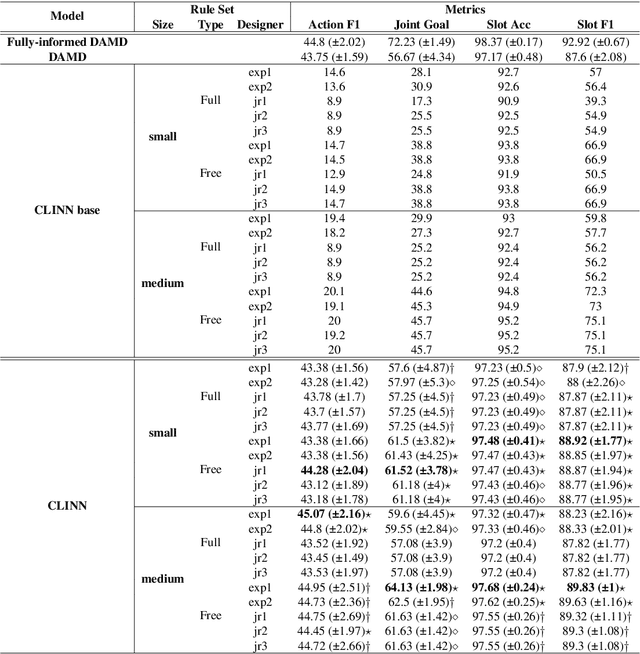
Incorporating explicit domain knowledge into neural-based task-oriented dialogue systems is an effective way to reduce the need of large sets of annotated dialogues. In this paper, we investigate how the use of explicit domain knowledge of conversational designers affects the performance of neural-based dialogue systems. To support this investigation, we propose the Conversational-Logic-Injection-in-Neural-Network system (CLINN) where explicit knowledge is coded in semi-logical rules. By using CLINN, we evaluated semi-logical rules produced by a team of differently skilled conversational designers. We experimented with the Restaurant topic of the MultiWOZ dataset. Results show that external knowledge is extremely important for reducing the need of annotated examples for conversational systems. In fact, rules from conversational designers used in CLINN significantly outperform a state-of-the-art neural-based dialogue system.
Lacking the embedding of a word? Look it up into a traditional dictionary
Sep 24, 2021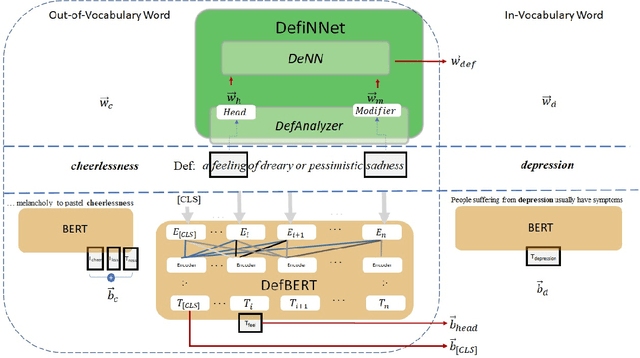
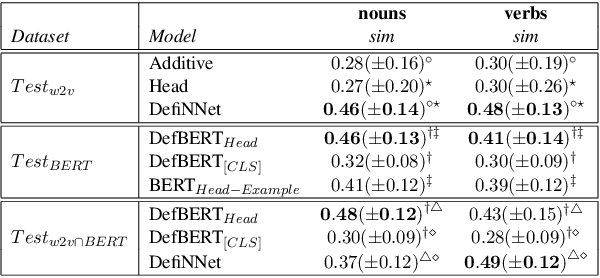
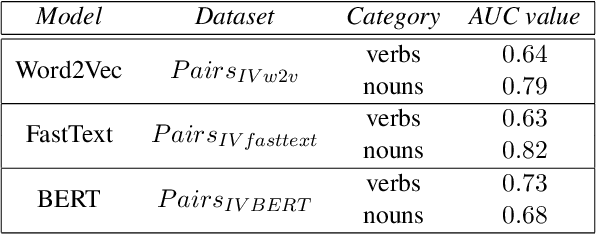
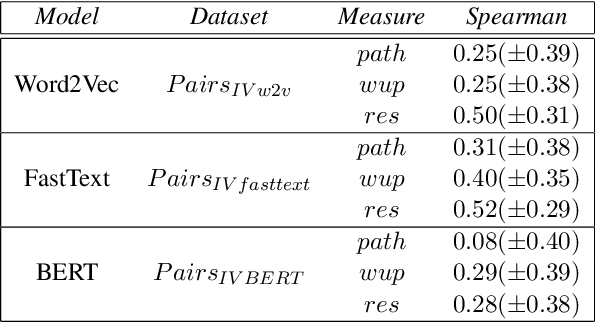
Word embeddings are powerful dictionaries, which may easily capture language variations. However, these dictionaries fail to give sense to rare words, which are surprisingly often covered by traditional dictionaries. In this paper, we propose to use definitions retrieved in traditional dictionaries to produce word embeddings for rare words. For this purpose, we introduce two methods: Definition Neural Network (DefiNNet) and Define BERT (DefBERT). In our experiments, DefiNNet and DefBERT significantly outperform state-of-the-art as well as baseline methods devised for producing embeddings of unknown words. In fact, DefiNNet significantly outperforms FastText, which implements a method for the same task-based on n-grams, and DefBERT significantly outperforms the BERT method for OOV words. Then, definitions in traditional dictionaries are useful to build word embeddings for rare words.