 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised ConvLSTM for Fermi Large Area Telescope Transient Detection
May 21, 2026We present a framework for detecting transient gamma-ray phenomena in a controlled environment by combining end-to-end simulations of the Fermi-LAT sky with self-supervised spatio-temporal deep learning. We generate a ten-year synthetic Universe with gtobssim and process the simulated events into daily all-sky maps of counts and exposure, obtaining a time-ordered sequence that mirrors the structure of Fermi-LAT observations. To model the nominal evolution of the sky, we employ a Convolutional Long Short-Term Memory (ConvLSTM) network that operates directly on map sequences, preserving spatial locality while learning temporal dependencies. The model is trained to reconstruct expected emission, and departures from the learned baseline are quantified through pixel-wise mean-squared residual maps. We then define statistically motivated anomaly criteria by estimating per-pixel thresholds from the residual distribution on the training set, and we enforce spatial coherence via local filtering to suppress isolated fluctuations. The ConvLSTM is then deployed as trained predictor on Fermi-LAT daily maps, where the sky can depart from the nominal behavior because of genuine astrophysical variability and instrumental non-stationarities. The resulting pipeline flags localized, time-dependent excesses consistent with high-variable sources or transient events (e.g., flares or GRBs) and provides a benchmark for evaluating anomaly-detection strategies on long-duration, Fermi-LAT-like datasets.
* 17 pages, 5 figures. Accepted for publication in Astronomy and Computing. Author-accepted manuscript version
Graph Vector Field: A Unified Framework for Multimodal Health Risk Assessment from Heterogeneous Wearable and Environmental Data Streams
Mar 30, 2026Digital health research has advanced dynamic graph-based disease models, topological learning on simplicial complexes, and multimodal mixture-of-experts architectures, but these strands remain largely disconnected. We propose Graph Vector Field (GVF), a framework that models health risk as a vector-valued field on time-varying simplicial complexes, coupling discrete differential-geometric operators with modality-structured mixture-of-experts. Risk is represented as a vector-valued cochain whose evolution is parameterised with Hodge Laplacians and discrete exterior calculus operators, yielding a Helmholtz-Hodge decomposition into potential-driven (exact), circulation-like (coexact), and topologically constrained (harmonic) components linked to interpretable propagation, cyclic, and persistent risk mechanisms. Multimodal inputs from wearable sensors, behavioural/environmental context, and clinical/genomic data are incorporated through a bundle-structured mixture-of-experts in which modality-specific latent spaces are attached as fibres to the base complex. This separates modality-specific from shared contributions and offers a principled route toward modality-level identifiability. GVF integrates geometric dynamical systems, higher-order topology (enforced indirectly via geometric regularisation and Hodge decomposition), and structured multimodal fusion into a single framework for interpretable, modality-resolved risk modelling. This paper develops the mathematical foundations, architectural design, and formal guarantees; empirical validation is the subject of ongoing work.
The Dark Side of the Language: Pre-trained Transformers in the DarkNet
Feb 09, 2022

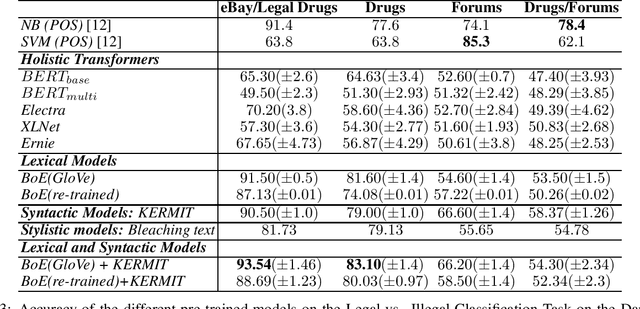
Pre-trained Transformers are challenging human performances in many natural language processing tasks. The gigantic datasets used for pre-training seem to be the key for their success on existing tasks. In this paper, we explore how a range of pre-trained natural language understanding models perform on truly novel and unexplored data, provided by classification tasks over a DarkNet corpus. Surprisingly, results show that syntactic and lexical neural networks largely outperform pre-trained Transformers. This seems to suggest that pre-trained Transformers have serious difficulties in adapting to radically novel texts.
Lacking the embedding of a word? Look it up into a traditional dictionary
Sep 24, 2021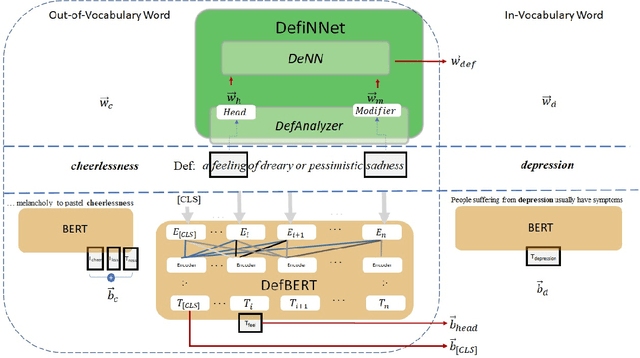
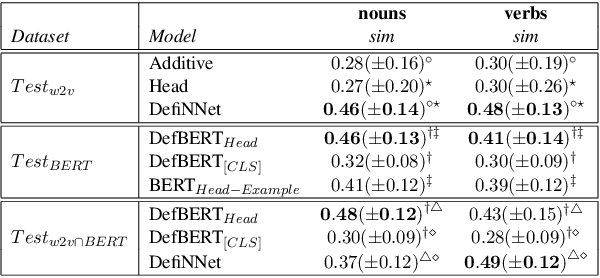
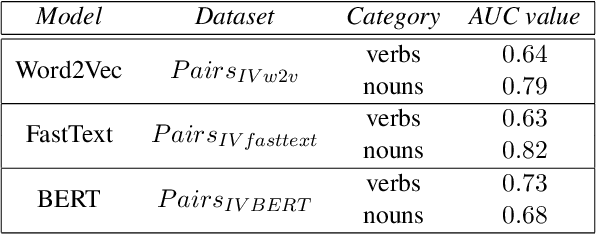
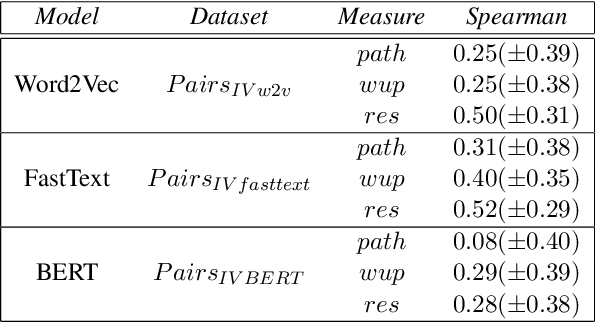
Word embeddings are powerful dictionaries, which may easily capture language variations. However, these dictionaries fail to give sense to rare words, which are surprisingly often covered by traditional dictionaries. In this paper, we propose to use definitions retrieved in traditional dictionaries to produce word embeddings for rare words. For this purpose, we introduce two methods: Definition Neural Network (DefiNNet) and Define BERT (DefBERT). In our experiments, DefiNNet and DefBERT significantly outperform state-of-the-art as well as baseline methods devised for producing embeddings of unknown words. In fact, DefiNNet significantly outperforms FastText, which implements a method for the same task-based on n-grams, and DefBERT significantly outperforms the BERT method for OOV words. Then, definitions in traditional dictionaries are useful to build word embeddings for rare words.