Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dark Side of the Language: Pre-trained Transformers in the DarkNet
Paper and Code
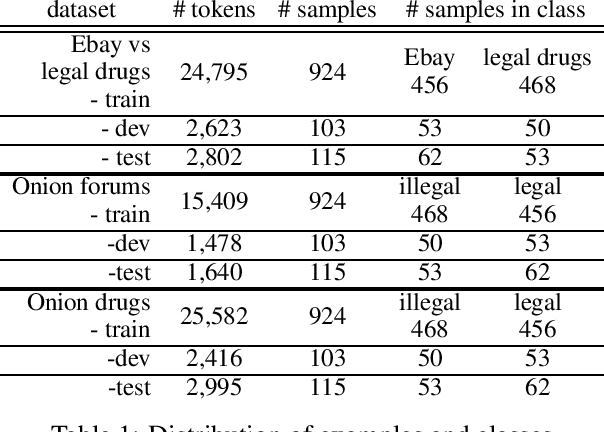

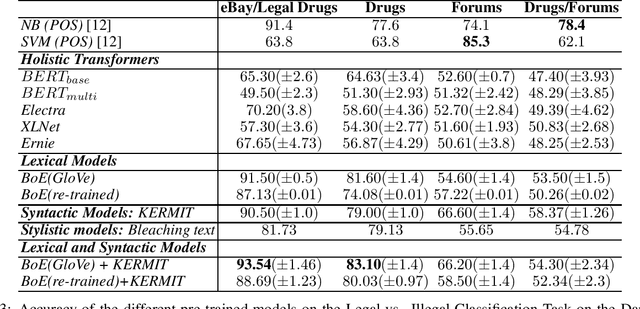
Pre-trained Transformers are challenging human performances in many natural language processing tasks. The gigantic datasets used for pre-training seem to be the key for their success on existing tasks. In this paper, we explore how a range of pre-trained natural language understanding models perform on truly novel and unexplored data, provided by classification tasks over a DarkNet corpus. Surprisingly, results show that syntactic and lexical neural networks largely outperform pre-trained Transformers. This seems to suggest that pre-trained Transformers have serious difficulties in adapting to radically novel texts.
View paper on