 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSULoRA: Closest Safe Update Low-Rank Adaptation
May 28, 2026Low-rank adaptation has become a standard method for parameter-efficient fine-tuning of large language models, but even small amounts of unsafe or adversarial fine-tuning data can substantially weaken the safety behavior of aligned models. Existing safety-preserving LoRA methods often rely on hard interventions such as projection, pruning, thresholding, or additional training objectives. While these methods can suppress unsafe update directions, they may also remove task-relevant information or require extra tuning. We introduce CSULoRA, a post-hoc method for correcting trained LoRA adapters through closest safe update estimation. CSULoRA estimates a safety-aligned subspace from the weight displacement between a safety-aligned model and its corresponding base checkpoint. It then decomposes each LoRA update into fully aligned, partially aligned, and off-subspace components. Instead of discarding components outside the estimated safety subspace, CSULoRA solves a closed-form penalized minimum-change problem that preserves the fully aligned component while smoothly attenuating potentially unsafe directions according to their relative energy. In adversarial fine-tuning experiments, CSULoRA substantially reduces attack success rate while preserving most of the utility gains obtained from standard LoRA fine-tuning.
Evaluating Explainable AI Attribution Methods in Neural Machine Translation via Attention-Guided Knowledge Distillation
Mar 11, 2026The study of the attribution of input features to the output of neural network models is an active area of research. While numerous Explainable AI (XAI) techniques have been proposed to interpret these models, the systematic and automated evaluation of these methods in sequence-to-sequence (seq2seq) models is less explored. This paper introduces a new approach for evaluating explainability methods in transformer-based seq2seq models. We use teacher-derived attribution maps as a structured side signal to guide a student model, and quantify the utility of different attribution methods through the student's ability to simulate targets. Using the Inseq library, we extract attribution scores over source-target sequence pairs and inject these scores into the attention mechanism of a student transformer model under four composition operators (addition, multiplication, averaging, and replacement). Across three language pairs (de-en, fr-en, ar-en) and attributions from Marian-MT and mBART models, Attention, Value Zeroing, and Layer Gradient $\times$ Activation consistently yield the largest gains in BLEU (and corresponding improvements in chrF) relative to baselines. In contrast, other gradient-based methods (Saliency, Integrated Gradients, DeepLIFT, Input $\times$ Gradient, GradientShap) lead to smaller and less consistent improvements. These results suggest that different attribution methods capture distinct signals and that attention-derived attributions better capture alignment between source and target representations in seq2seq models. Finally, we introduce an Attributor transformer that, given a source-target pair, learns to reconstruct the teacher's attribution map. Our findings demonstrate that the more accurately the Attributor can reproduce attribution maps, the more useful an injection of those maps is for the downstream task. The source code can be found on GitHub.
Cluster Purge Loss: Structuring Transformer Embeddings for Equivalent Mutants Detection
Jul 26, 2025Recent pre-trained transformer models achieve superior performance in various code processing objectives. However, although effective at optimizing decision boundaries, common approaches for fine-tuning them for downstream classification tasks - distance-based methods or training an additional classification head - often fail to thoroughly structure the embedding space to reflect nuanced intra-class semantic relationships. Equivalent code mutant detection is one of these tasks, where the quality of the embedding space is crucial to the performance of the models. We introduce a novel framework that integrates cross-entropy loss with a deep metric learning objective, termed Cluster Purge Loss. This objective, unlike conventional approaches, concentrates on adjusting fine-grained differences within each class, encouraging the separation of instances based on semantical equivalency to the class center using dynamically adjusted borders. Employing UniXCoder as the base model, our approach demonstrates state-of-the-art performance in the domain of equivalent mutant detection and produces a more interpretable embedding space.
The Dark Side of the Language: Pre-trained Transformers in the DarkNet
Feb 09, 2022

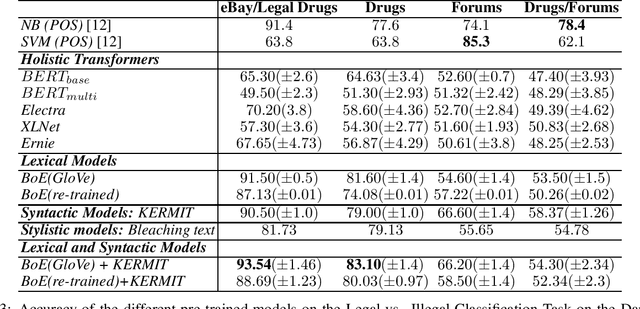
Pre-trained Transformers are challenging human performances in many natural language processing tasks. The gigantic datasets used for pre-training seem to be the key for their success on existing tasks. In this paper, we explore how a range of pre-trained natural language understanding models perform on truly novel and unexplored data, provided by classification tasks over a DarkNet corpus. Surprisingly, results show that syntactic and lexical neural networks largely outperform pre-trained Transformers. This seems to suggest that pre-trained Transformers have serious difficulties in adapting to radically novel texts.
Toward Dialogue Modeling: A Semantic Annotation Scheme for Questions and Answers
Aug 23, 2019

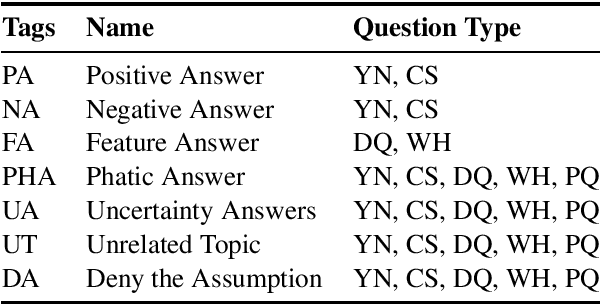
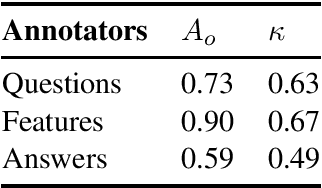
The present study proposes an annotation scheme for classifying the content and discourse contribution of question-answer pairs. We propose detailed guidelines for using the scheme and apply them to dialogues in English, Spanish, and Dutch. Finally, we report on initial machine learning experiments for automatic annotation.