 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Multilingual Chain-of-Thought in Process Reward Modeling
Paper and Code
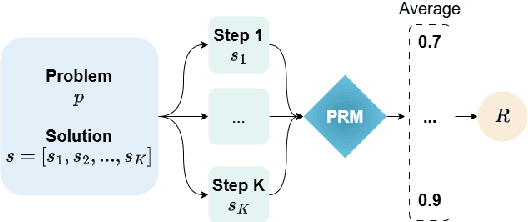
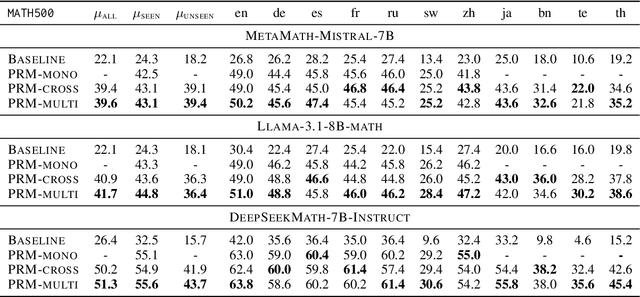
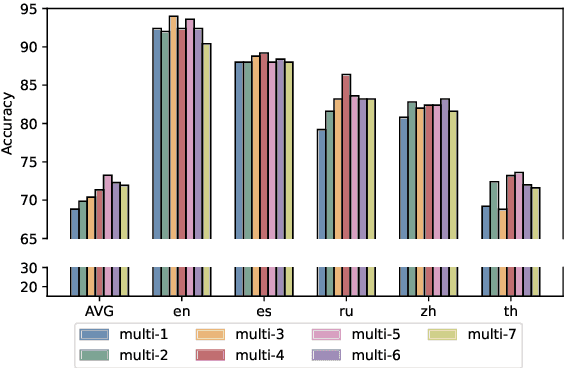

Large language models (LLMs) are designed to perform a wide range of tasks. To improve their ability to solve complex problems requiring multi-step reasoning, recent research leverages process reward modeling to provide fine-grained feedback at each step of the reasoning process for reinforcement learning (RL), but it predominantly focuses on English. In this paper, we tackle the critical challenge of extending process reward models (PRMs) to multilingual settings. To achieve this, we train multilingual PRMs on a dataset spanning seven languages, which is translated from English. Through comprehensive evaluations on two widely used reasoning benchmarks across 11 languages, we demonstrate that multilingual PRMs not only improve average accuracy but also reduce early-stage reasoning errors. Furthermore, our results highlight the sensitivity of multilingual PRMs to both the number of training languages and the volume of English data, while also uncovering the benefits arising from more candidate responses and trainable parameters. This work opens promising avenues for robust multilingual applications in complex, multi-step reasoning tasks. In addition, we release the code to foster research along this line.