 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveSSM: Multiscale State-Space Models for Non-stationary Signal Attention
Feb 25, 2026State-space models (SSMs) have emerged as a powerful foundation for long-range sequence modeling, with the HiPPO framework showing that continuous-time projection operators can be used to derive stable, memory-efficient dynamical systems that encode the past history of the input signal. However, existing projection-based SSMs often rely on polynomial bases with global temporal support, whose inductive biases are poorly matched to signals exhibiting localized or transient structure. In this work, we introduce \emph{WaveSSM}, a collection of SSMs constructed over wavelet frames. Our key observation is that wavelet frames yield a localized support on the temporal dimension, useful for tasks requiring precise localization. Empirically, we show that on equal conditions, \textit{WaveSSM} outperforms orthogonal counterparts as S4 on real-world datasets with transient dynamics, including physiological signals on the PTB-XL dataset and raw audio on Speech Commands.
Broadening Discovery through Structural Models: Multimodal Combination of Local and Structural Properties for Predicting Chemical Features
Feb 25, 2025



In recent years, machine learning has profoundly reshaped the field of chemistry, facilitating significant advancements across various applications, including the prediction of molecular properties and the generation of molecular structures. Language models and graph-based models are extensively utilized within this domain, consistently achieving state-of-the-art results across an array of tasks. However, the prevailing practice of representing chemical compounds in the SMILES format -- used by most datasets and many language models -- presents notable limitations as a training data format. In contrast, chemical fingerprints offer a more physically informed representation of compounds, thereby enhancing their suitability for model training. This study aims to develop a language model that is specifically trained on fingerprints. Furthermore, we introduce a bimodal architecture that integrates this language model with a graph model. Our proposed methodology synthesizes these approaches, utilizing RoBERTa as the language model and employing Graph Isomorphism Networks (GIN), Graph Convolutional Networks (GCN) and Graphormer as graph models. This integration results in a significant improvement in predictive performance compared to conventional strategies for tasks such as Quantitative Structure-Activity Relationship (QSAR) and the prediction of nuclear magnetic resonance (NMR) spectra, among others.
$ψ$DAG: Projected Stochastic Approximation Iteration for DAG Structure Learning
Oct 31, 2024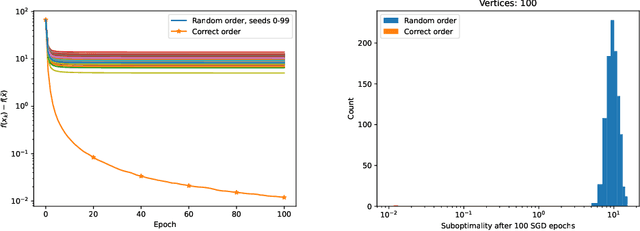

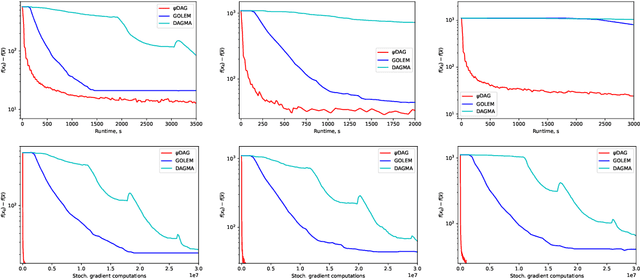
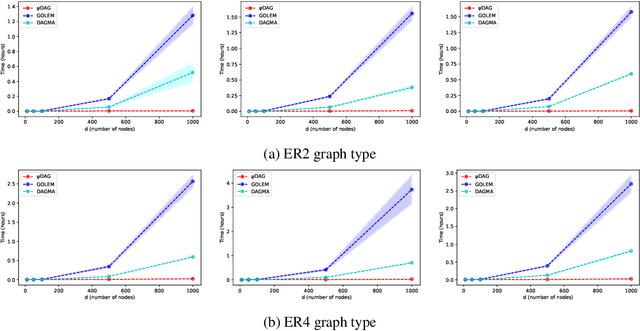
Learning the structure of Directed Acyclic Graphs (DAGs) presents a significant challenge due to the vast combinatorial search space of possible graphs, which scales exponentially with the number of nodes. Recent advancements have redefined this problem as a continuous optimization task by incorporating differentiable acyclicity constraints. These methods commonly rely on algebraic characterizations of DAGs, such as matrix exponentials, to enable the use of gradient-based optimization techniques. Despite these innovations, existing methods often face optimization difficulties due to the highly non-convex nature of DAG constraints and the per-iteration computational complexity. In this work, we present a novel framework for learning DAGs, employing a Stochastic Approximation approach integrated with Stochastic Gradient Descent (SGD)-based optimization techniques. Our framework introduces new projection methods tailored to efficiently enforce DAG constraints, ensuring that the algorithm converges to a feasible local minimum. With its low iteration complexity, the proposed method is well-suited for handling large-scale problems with improved computational efficiency. We demonstrate the effectiveness and scalability of our framework through comprehensive experimental evaluations, which confirm its superior performance across various settings.
MirrorCheck: Efficient Adversarial Defense for Vision-Language Models
Jun 13, 2024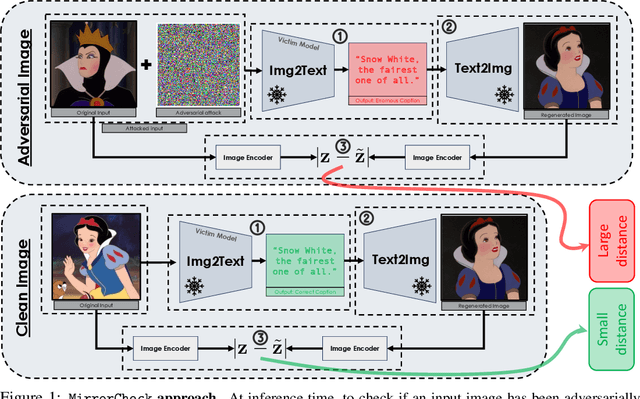



Vision-Language Models (VLMs) are becoming increasingly vulnerable to adversarial attacks as various novel attack strategies are being proposed against these models. While existing defenses excel in unimodal contexts, they currently fall short in safeguarding VLMs against adversarial threats. To mitigate this vulnerability, we propose a novel, yet elegantly simple approach for detecting adversarial samples in VLMs. Our method leverages Text-to-Image (T2I) models to generate images based on captions produced by target VLMs. Subsequently, we calculate the similarities of the embeddings of both input and generated images in the feature space to identify adversarial samples. Empirical evaluations conducted on different datasets validate the efficacy of our approach, outperforming baseline methods adapted from image classification domains. Furthermore, we extend our methodology to classification tasks, showcasing its adaptability and model-agnostic nature. Theoretical analyses and empirical findings also show the resilience of our approach against adaptive attacks, positioning it as an excellent defense mechanism for real-world deployment against adversarial threats.